多数据源和Mapper配置
一、介绍
为应用程序配置 pgvector(向量库) 与 MySQL(业务库) 两套数据源,并基于已设计的库表,编写基础设施层的 Mapper 操作。
数据库表的 Mapper 编写属于一种相对固定的结构化代码,可以通过 MyBatis 工具自动生成,也可以借助 AI 编码工具完成。但对于学习阶段的新人,更建议采用 手动编写 的方式:
- 可以在实践中更深入地理解 库表设计 与 字段含义;
- 在遇到报错时,能够通过 错误排查 积累经验,从而提升编程能力。
二、功能流程
如图,两个数据源的配置和使用;
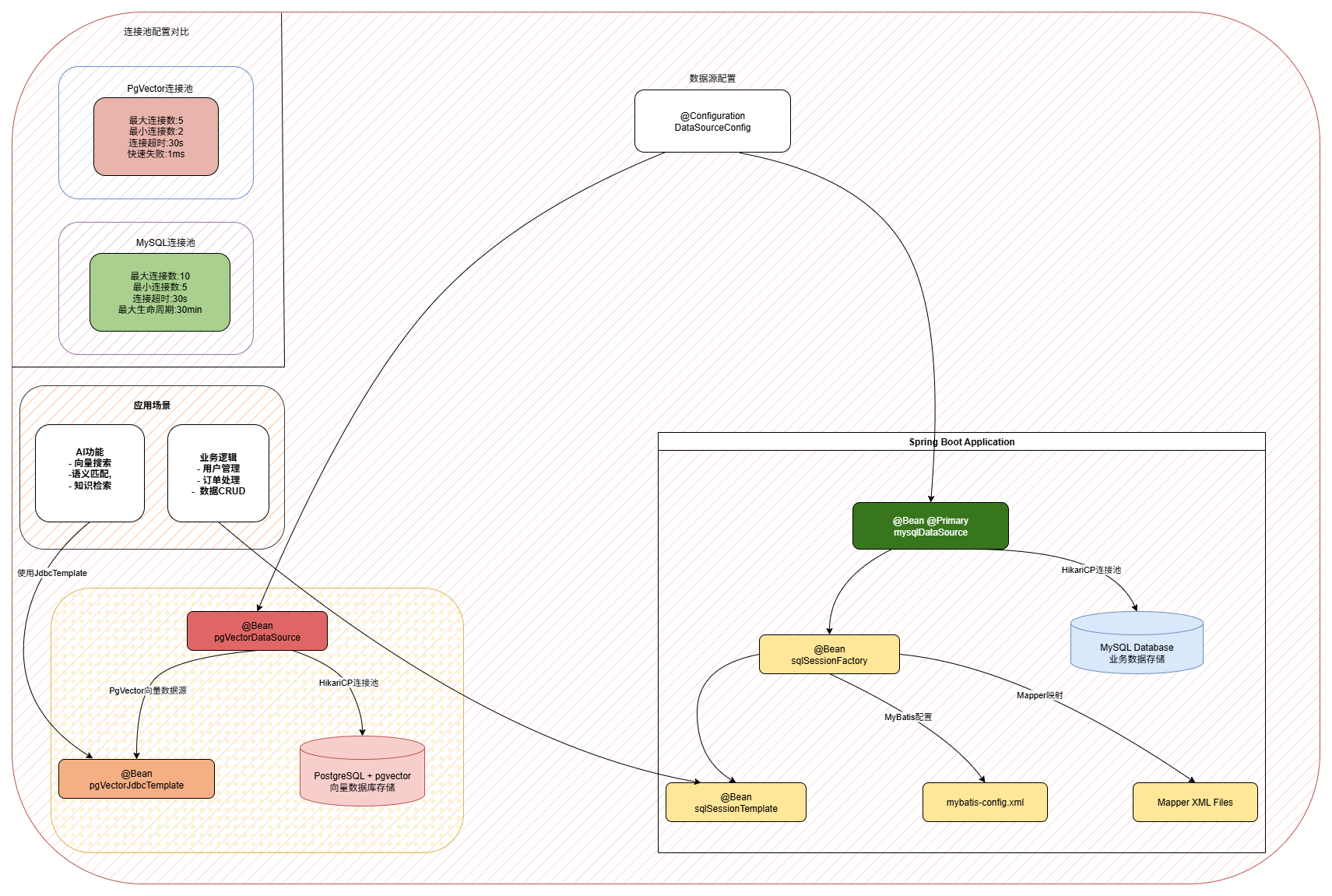
首先,为了让应用程序支持 多数据源连接,需要新增一个扩展的 DataSourceConfig 配置类,用于自定义数据源的加载逻辑。这样可以替代原本通过 yml 配置文件 由 Spring 自动加载数据源的方式,实现更灵活的管理。
随后,根据不同类型的数据源,将其分别注入到:
- AI 向量库使用场景(如 pgvector)
- MyBatis 业务使用场景(如 MySQL)
从而保证应用能够在不同的场景下高效调用对应的数据源。
三、编码实现
2. 数据源配置
在传统的 Spring Boot 应用中,通常通过 application.yml 配置 单一数据源,由框架完成自动装配。但在 AI 应用场景下,往往需要同时连接 MySQL(业务数据) 与 PgVector(向量数据),因此需要 手动配置多数据源,以满足不同数据类型与访问场景的需求。
2.1 配置类基础结构
@Configuration
public class DataSourceConfig {
// 多数据源配置
}@Configuration:用于标记该类是一个 Spring 配置类,Spring 容器会扫描并加载其中定义的 Bean。
该配置类替代了传统在 application.yml 中编写的数据源配置方式,提供了更加灵活的 多数据源管理能力,能够满足业务库(MySQL)与向量库(PgVector)等多场景下的使用需求。
2.2 MySQL业务数据源配置
@Bean("mysqlDataSource")
@Primary
public DataSource mysqlDataSource(@Value("${spring.datasource.mysql.driver-class-name}") String driverClassName,
@Value("${spring.datasource.mysql.url}") String url,
@Value("${spring.datasource.mysql.username}") String username,
@Value("${spring.datasource.mysql.password}") String password,
@Value("${spring.datasource.mysql.hikari.maximum-pool-size:10}") int maximumPoolSize,
@Value("${spring.datasource.mysql.hikari.minimum-idle:5}") int minimumIdle,
@Value("${spring.datasource.mysql.hikari.idle-timeout:30000}") long idleTimeout,
@Value("${spring.datasource.mysql.hikari.connection-timeout:30000}") long connectionTimeout,
@Value("${spring.datasource.mysql.hikari.max-lifetime:1800000}") long maxLifetime) {
// 创建HikariCP连接池
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName(driverClassName);
dataSource.setJdbcUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
// 连接池参数配置
dataSource.setMaximumPoolSize(maximumPoolSize); // 最大连接数:10
dataSource.setMinimumIdle(minimumIdle); // 最小空闲连接数:5
dataSource.setIdleTimeout(idleTimeout); // 空闲连接超时时间:30秒
dataSource.setConnectionTimeout(connectionTimeout); // 连接超时时间:30秒
dataSource.setMaxLifetime(maxLifetime); // 连接最大存活时间:30分钟
dataSource.setPoolName("MainHikariPool"); // 连接池名称
return dataSource;
}1. 注解说明
@Bean("mysqlDataSource"):将方法返回值注册为 Spring Bean,Bean 名称为"mysqlDataSource"。@Primary:标记为主数据源。当存在多个同类型的 Bean 时,Spring 会优先选择该数据源。
2. 参数注入机制
@Value("${配置项}"):从配置文件中读取属性值,实现配置外部化。:10、:5等表示 默认值,当配置文件中没有对应属性时会使用默认值。- 这种方式比硬编码更灵活,便于在 开发 / 测试 / 生产 等不同环境下进行配置管理。
3. HikariCP 连接池优势
HikariCP 是当前性能最优的 Java 数据库连接池,Spring Boot 2.x 已默认使用。常用参数说明:
maximumPoolSize(10):设置最大连接数,支持高并发业务场景。minimumIdle(5):保持一定数量的空闲连接,提高连接获取速度。idleTimeout(30秒):空闲连接超过该时间会被释放,避免资源浪费。connectionTimeout(30秒):获取连接的最大等待时间,超过将抛出异常。maxLifetime(30分钟):单个连接的最大存活时间,防止出现长时间占用的连接问题。
2.3 MyBatis集成配置
@Bean("sqlSessionFactory")
public SqlSessionFactoryBean sqlSessionFactory(@Qualifier("mysqlDataSource") DataSource mysqlDataSource) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(mysqlDataSource);
// 设置MyBatis配置文件位置
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sqlSessionFactoryBean.setConfigLocation(resolver.getResource("classpath:/mybatis/config/mybatis-config.xml"));
// 设置Mapper XML文件位置
sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mybatis/mapper/*.xml"));
return sqlSessionFactoryBean;
}依赖注入的精确控制:
@Qualifier("mysqlDataSource"):明确指定注入名为"mysqlDataSource"的 Bean。
这样可以确保 MyBatis 使用 MySQL 数据源,避免与 PgVector 数据源 混淆。
配置文件管理:
SqlSessionFactoryBean:MyBatis 与 Spring 集成的核心工厂类。setConfigLocation:指定 MyBatis 主配置文件路径,用于加载全局设置、类型别名等。setMapperLocations:指定 Mapper XML 文件位置,支持通配符方式批量加载。
SqlSessionTemplate:
SqlSessionTemplate是 MyBatis-Spring 提供的 线程安全的 SqlSession 实现。- 它会自动管理
SqlSession的生命周期,开发者无需手动关闭连接。 - 同时与 Spring 事务管理 无缝集成,保证事务一致性与数据安全性。
2.4 PgVector向量数据源配置
@Bean("pgVectorDataSource")
public DataSource pgVectorDataSource(@Value("${spring.datasource.pgvector.driver-class-name}") String driverClassName,
@Value("${spring.datasource.pgvector.url}") String url,
@Value("${spring.datasource.pgvector.username}") String username,
@Value("${spring.datasource.pgvector.password}") String password,
@Value("${spring.datasource.pgvector.hikari.maximum-pool-size:5}") int maximumPoolSize,
@Value("${spring.datasource.pgvector.hikari.minimum-idle:2}") int minimumIdle,
@Value("${spring.datasource.pgvector.hikari.idle-timeout:30000}") long idleTimeout,
@Value("${spring.datasource.pgvector.hikari.connection-timeout:30000}") long connectionTimeout) {
// 连接池配置
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName(driverClassName);
dataSource.setJdbcUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
// 向量库专用连接池配置
dataSource.setMaximumPoolSize(maximumPoolSize);
dataSource.setMinimumIdle(minimumIdle);
dataSource.setIdleTimeout(idleTimeout);
dataSource.setConnectionTimeout(connectionTimeout);
// 向量库特殊配置
dataSource.setInitializationFailTimeout(1); // 确保在启动时连接数据库,设置为1ms,如果连接失败则快速失败
dataSource.setConnectionTestQuery("SELECT 1"); // 简单的连接测试查询
dataSource.setAutoCommit(true); // 自动提交事务
dataSource.setPoolName("PgVectorHikariPool"); // 连接池名称
return dataSource;
}
@Bean("pgVectorJdbcTemplate")
public JdbcTemplate pgVectorJdbcTemplate(@Qualifier("pgVectorDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}连接池优化策略:
- 连接数设置较小(最大 5 个):向量查询通常为计算密集型任务,对并发连接数量要求不高。设置较小的连接数既能满足需求,又能避免资源浪费。
- 针对 AI 查询场景优化:根据向量检索的特点,优先保证计算效率,而不是堆叠数据库连接。
快速失败机制:
setInitializationFailTimeout(1):设置为 1 毫秒,启用快速失败。当向量库不可用时,不会长时间阻塞等待,可以立即发现问题。setConnectionTestQuery("SELECT 1"):执行简单的心跳查询作为连接健康检查,确保连接池中的连接可用。
JdbcTemplate 的选择:
- 使用
JdbcTemplate而不是 MyBatis,更适合处理 向量操作的简单 SQL。 - 向量查询通常是直接的 SQL 操作,不涉及复杂的 ORM 映射。
- 性能更优:避免不必要的对象转换和映射开销,更高效地执行查询。
2.5 向量库配置
@Configuration
public class AiAgentConfig {
/**
* -- 删除旧的表(如果存在)
* DROP TABLE IF EXISTS public.vector_store_openai;
* <p>
* -- 创建新的表,使用UUID作为主键
* CREATE TABLE public.vector_store_openai (
* id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
* content TEXT NOT NULL,
* metadata JSONB,
* embedding VECTOR(1536)
* );
* <p>
* SELECT * FROM vector_store_openai
*/
@Bean("vectorStore")
public PgVectorStore pgVectorStore(@Value("${spring.ai.openai.embedding.base-url}") String baseUrl,
@Value("${spring.ai.openai.embedding.api-key}") String apiKey,
@Qualifier("pgVectorJdbcTemplate") JdbcTemplate jdbcTemplate) {
OpenAiApi openAiApi = OpenAiApi.builder()
.baseUrl(baseUrl)
.apiKey(apiKey)
.build();
OpenAiEmbeddingModel embeddingModel = new OpenAiEmbeddingModel(openAiApi);
return PgVectorStore.builder(jdbcTemplate, embeddingModel)
.vectorTableName("vector_store_openai")
.build();
}
@Bean
public TokenTextSplitter tokenTextSplitter() {
return new TokenTextSplitter();
}
}在 AiAgentConfig 文件中,配置了 pgVectorStore,因为这里要指定库表名称。这个表名 vector_store_openai 也就是工程 docs/dev-ops/pgvector/sql/init.sql 里初始化创建的表。如果没有这个表,那么你要通过语句,在向量库手动创建。
2.6 多数据源设计优势
- 数据隔离性
业务数据与向量数据完全分离,互不干扰,有效提升系统稳定性与安全性。 - 性能优化
针对不同数据类型和访问模式,分别优化连接池参数。例如:MySQL 适配高并发业务请求,PgVector 聚焦计算密集型向量查询。 - 技术栈适配
MySQL 使用 MyBatis ORM,便于复杂业务逻辑的实体映射;PgVector 使用 JdbcTemplate,更适合直接执行向量类 SQL 操作,各取所长。 - 扩展性强
架构具备良好的扩展性,可轻松新增其他类型数据源,如 Redis、MongoDB 等,支持更复杂的业务场景。 - 配置灵活
通过外部配置文件灵活调整参数,能够快速适配不同环境(开发、测试、生产)的需求。 - 故障隔离
单个数据源的异常不会影响其他数据源的正常使用,从而提升整体系统的鲁棒性。
这种 多数据源架构 在互联网企业中应用广泛:
- 一个应用往往需要同时连接 多套数据库、多套 Redis,以分摊数据和应用的压力。
- 掌握这种设计思路后,可以灵活应用到其他类似场景中。
- 甚至还可以将该配置模式 抽取为独立的技术组件,在多个项目中复用。
3. Mapper 配置
一个数据库表要供程序使用,通常需要配套的 PO 对象、DAO 接口,以及用于将二者与数据库语句映射的 Mapper 配置。这类表的配置操作高度重复,这里仅以 ai_agent 表 为示例展示,其他表可参考代码同样处理。
3.1 数据库表
CREATE TABLE `ai_client_tool_mcp` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`mcp_id` varchar(64) NOT NULL COMMENT 'MCP名称',
`mcp_name` varchar(50) NOT NULL COMMENT 'MCP名称',
`transport_type` varchar(20) NOT NULL COMMENT '传输类型(sse/stdio)',
`transport_config` varchar(1024) DEFAULT NULL COMMENT '传输配置(sse/stdio)',
`request_timeout` int DEFAULT '180' COMMENT '请求超时时间(分钟)',
`status` tinyint(1) DEFAULT '1' COMMENT '状态(0:禁用,1:启用)',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_mcp_id` (`mcp_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='MCP客户端配置表';基于数据库表有非常多的工具可以生成 PO、DAO、Mapper 文件,也可以使用AI来完成。这里就不再详细阐述了。
3.2 PO 对象
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class AiClientToolMcp {
/**
* 主键ID
*/
private Long id;
/**
* MCP名称
*/
private String mcpId;
/**
* MCP名称
*/
private String mcpName;
/**
* 传输类型(sse/stdio)
*/
private String transportType;
/**
* 传输配置(sse/stdio)
*/
private String transportConfig;
/**
* 请求超时时间(分钟)
*/
private Integer requestTimeout;
/**
* 状态(0:禁用,1:启用)
*/
private Integer status;
/**
* 创建时间
*/
private LocalDateTime createTime;
/**
* 更新时间
*/
private LocalDateTime updateTime;
}3.3 DAO 文件
@Mapper
public interface IAiClientToolMcpDao {
/**
* 插入MCP客户端配置
* @param aiClientToolMcp MCP客户端配置对象
* @return 影响行数
*/
int insert(AiClientToolMcp aiClientToolMcp);
/**
* 根据ID更新MCP客户端配置
* @param aiClientToolMcp MCP客户端配置对象
* @return 影响行数
*/
int updateById(AiClientToolMcp aiClientToolMcp);
/**
* 根据MCP ID更新MCP客户端配置
* @param aiClientToolMcp MCP客户端配置对象
* @return 影响行数
*/
int updateByMcpId(AiClientToolMcp aiClientToolMcp);
/**
* 根据ID删除MCP客户端配置
* @param id 主键ID
* @return 影响行数
*/
int deleteById(Long id);
/**
* 根据MCP ID删除MCP客户端配置
* @param mcpId MCP ID
* @return 影响行数
*/
int deleteByMcpId(String mcpId);
/**
* 根据ID查询MCP客户端配置
* @param id 主键ID
* @return MCP客户端配置对象
*/
AiClientToolMcp queryById(Long id);
/**
* 根据MCP ID查询MCP客户端配置
* @param mcpId MCP ID
* @return MCP客户端配置对象
*/
AiClientToolMcp queryByMcpId(String mcpId);
/**
* 查询启用的MCP客户端配置
* @return MCP客户端配置列表
*/
List<AiClientToolMcp> queryEnabledMcps();
/**
* 根据传输类型查询MCP客户端配置
* @param transportType 传输类型
* @return MCP客户端配置列表
*/
List<AiClientToolMcp> queryByTransportType(String transportType);
/**
* 查询所有MCP客户端配置
* @return MCP客户端配置列表
*/
List<AiClientToolMcp> queryAll();
}3.4 Mapper 映射
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.cactusli.ai.infrastructure.dao.IAiClientToolMcpDao">
<resultMap id="AiClientToolMcpMap" type="cn.cactusli.ai.infrastructure.dao.po.AiClientToolMcp">
<id column="id" property="id"/>
<result column="mcp_id" property="mcpId"/>
<result column="mcp_name" property="mcpName"/>
<result column="transport_type" property="transportType"/>
<result column="transport_config" property="transportConfig"/>
<result column="request_timeout" property="requestTimeout"/>
<result column="status" property="status"/>
<result column="create_time" property="createTime"/>
<result column="update_time" property="updateTime"/>
</resultMap>
<insert id="insert" parameterType="cn.cactusli.ai.infrastructure.dao.po.AiClientToolMcp" useGeneratedKeys="true" keyProperty="id">
INSERT INTO ai_client_tool_mcp (
mcp_id, mcp_name, transport_type, transport_config, request_timeout, status, create_time, update_time
) VALUES (
#{mcpId}, #{mcpName}, #{transportType}, #{transportConfig}, #{requestTimeout}, #{status}, #{createTime}, #{updateTime}
)
</insert>
<update id="updateById" parameterType="cn.cactusli.ai.infrastructure.dao.po.AiClientToolMcp">
UPDATE ai_client_tool_mcp SET
mcp_id = #{mcpId},
mcp_name = #{mcpName},
transport_type = #{transportType},
transport_config = #{transportConfig},
request_timeout = #{requestTimeout},
status = #{status},
update_time = #{updateTime}
WHERE id = #{id}
</update>
<update id="updateByMcpId" parameterType="cn.cactusli.ai.infrastructure.dao.po.AiClientToolMcp">
UPDATE ai_client_tool_mcp SET
mcp_name = #{mcpName},
transport_type = #{transportType},
transport_config = #{transportConfig},
request_timeout = #{requestTimeout},
status = #{status},
update_time = #{updateTime}
WHERE mcp_id = #{mcpId}
</update>
<delete id="deleteById" parameterType="java.lang.Long">
DELETE FROM ai_client_tool_mcp WHERE id = #{id}
</delete>
<delete id="deleteByMcpId" parameterType="java.lang.String">
DELETE FROM ai_client_tool_mcp WHERE mcp_id = #{mcpId}
</delete>
<select id="queryById" parameterType="java.lang.Long" resultMap="AiClientToolMcpMap">
SELECT id, mcp_id, mcp_name, transport_type, transport_config, request_timeout, status, create_time, update_time
FROM ai_client_tool_mcp
WHERE id = #{id}
</select>
<select id="queryByMcpId" parameterType="java.lang.String" resultMap="AiClientToolMcpMap">
SELECT id, mcp_id, mcp_name, transport_type, transport_config, request_timeout, status, create_time, update_time
FROM ai_client_tool_mcp
WHERE mcp_id = #{mcpId}
</select>
<select id="queryAll" resultMap="AiClientToolMcpMap">
SELECT id, mcp_id, mcp_name, transport_type, transport_config, request_timeout, status, create_time, update_time
FROM ai_client_tool_mcp
ORDER BY create_time DESC
</select>
<select id="queryByStatus" parameterType="java.lang.Integer" resultMap="AiClientToolMcpMap">
SELECT id, mcp_id, mcp_name, transport_type, transport_config, request_timeout, status, create_time, update_time
FROM ai_client_tool_mcp
WHERE status = #{status}
ORDER BY create_time DESC
</select>
<select id="queryByTransportType" parameterType="java.lang.String" resultMap="AiClientToolMcpMap">
SELECT id, mcp_id, mcp_name, transport_type, transport_config, request_timeout, status, create_time, update_time
FROM ai_client_tool_mcp
WHERE transport_type = #{transportType}
ORDER BY create_time DESC
</select>
<select id="queryEnabledMcps" resultMap="AiClientToolMcpMap">
SELECT id, mcp_id, mcp_name, transport_type, transport_config, request_timeout, status, create_time, update_time
FROM ai_client_tool_mcp
WHERE status = 1
ORDER BY create_time DESC
</select>
</mapper>四、测试验证
/**
* MCP客户端配置表 DAO 测试
* @description MCP客户端配置表数据访问对象测试
*/
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class AiClientToolMcpDaoTest {
@Resource
private IAiClientToolMcpDao aiClientToolMcpDao;
@Test
public void test_insert() {
AiClientToolMcp aiClientToolMcp = AiClientToolMcp.builder()
.mcpId("test_5006")
.mcpName("测试MCP工具")
.transportType("sse")
.transportConfig("{\"baseUri\":\"http://localhost:8080\",\"sseEndpoint\":\"/sse\"}")
.requestTimeout(180)
.status(1)
.createTime(LocalDateTime.now())
.updateTime(LocalDateTime.now())
.build();
int result = aiClientToolMcpDao.insert(aiClientToolMcp);
log.info("插入结果: {}, 生成ID: {}", result, aiClientToolMcp.getId());
}
@Test
public void test_updateById() {
AiClientToolMcp aiClientToolMcp = AiClientToolMcp.builder()
.id(1L)
.mcpId("test_5006")
.mcpName("更新后的测试MCP工具")
.transportType("stdio")
.transportConfig("{\"command\":\"npx\",\"args\":[\"-y\",\"test-mcp\"]}")
.requestTimeout(300)
.status(1)
.updateTime(LocalDateTime.now())
.build();
int result = aiClientToolMcpDao.updateById(aiClientToolMcp);
log.info("更新结果: {}", result);
}
@Test
public void test_updateByMcpId() {
AiClientToolMcp aiClientToolMcp = AiClientToolMcp.builder()
.mcpId("5001")
.mcpName("根据MCP ID更新的工具")
.transportType("sse")
.transportConfig("{\"baseUri\":\"http://updated.example.com\",\"sseEndpoint\":\"/sse\"}")
.requestTimeout(240)
.status(1)
.updateTime(LocalDateTime.now())
.build();
int result = aiClientToolMcpDao.updateByMcpId(aiClientToolMcp);
log.info("根据MCP ID更新结果: {}", result);
}
@Test
public void test_deleteById() {
int result = aiClientToolMcpDao.deleteById(1L);
log.info("删除结果: {}", result);
}
@Test
public void test_deleteByMcpId() {
int result = aiClientToolMcpDao.deleteByMcpId("test_5006");
log.info("根据MCP ID删除结果: {}", result);
}
@Test
public void test_queryById() {
AiClientToolMcp aiClientToolMcp = aiClientToolMcpDao.queryById(6L);
log.info("根据ID查询结果: {}", aiClientToolMcp);
}
@Test
public void test_queryByMcpId() {
AiClientToolMcp aiClientToolMcp = aiClientToolMcpDao.queryByMcpId("5001");
log.info("根据MCP ID查询结果: {}", aiClientToolMcp);
}
@Test
public void test_queryAll() {
List<AiClientToolMcp> aiClientToolMcpList = aiClientToolMcpDao.queryAll();
log.info("查询所有MCP工具配置数量: {}", aiClientToolMcpList.size());
aiClientToolMcpList.forEach(mcp -> log.info("MCP工具配置: {}", mcp));
}
@Test
public void test_queryByStatus() {
List<AiClientToolMcp> aiClientToolMcpList = aiClientToolMcpDao.queryByStatus(1);
log.info("根据状态查询结果数量: {}", aiClientToolMcpList.size());
aiClientToolMcpList.forEach(mcp -> log.info("启用的MCP工具配置: {}", mcp));
}
@Test
public void test_queryByTransportType() {
List<AiClientToolMcp> aiClientToolMcpList = aiClientToolMcpDao.queryByTransportType("sse");
log.info("根据传输类型查询结果数量: {}", aiClientToolMcpList.size());
aiClientToolMcpList.forEach(mcp -> log.info("SSE类型MCP工具配置: {}", mcp));
}
@Test
public void test_queryEnabledMcps() {
List<AiClientToolMcp> aiClientToolMcpList = aiClientToolMcpDao.queryEnabledMcps();
log.info("查询启用的MCP工具配置数量: {}", aiClientToolMcpList.size());
aiClientToolMcpList.forEach(mcp -> log.info("启用的MCP工具配置: {}", mcp));
}
}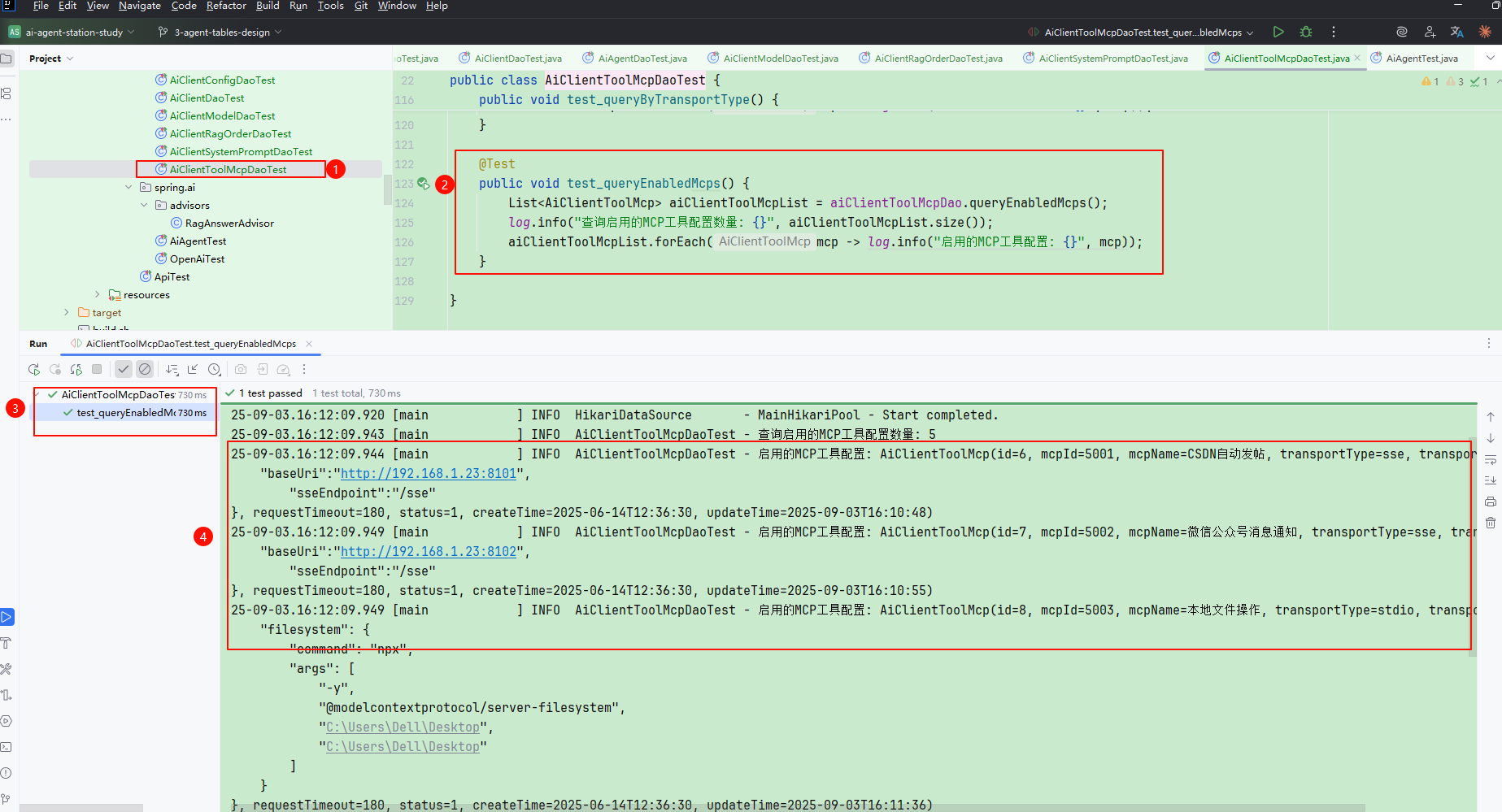
- 这里提供了多组测试方法,可用于逐一验证 DAO 工程 的正确性。
- 可以分别执行各个用例,以加深对各张库表的理解。
- 这些熟悉与练习将为后续编码打下基础,帮助你更好地把握库表设计与使用方式。