搭建AiAgent案例
一、介绍
在项目中我们引入了 Spring AI 1.0.0 框架,并通过编写测试案例的方式来理解 AI Agent 的工作模式。
在软件设计方案中,通常有一个共识:结果驱动,优先搭建可运行的最小执行单元。这与软件设计原则及 康威定律 的观点一致——大型系统往往会被拆解为多个小型系统,而场景问题被划分得越细小,就越容易被理解和解决。
因此,我们选择以 测试案例 为切入点,先行验证 AI Agent 的工作机制与可执行方案。随后,再基于这些案例去设计更为详细的业务流程与数据库表结构,从而确保整体方案既具备可行性,又能平滑演进。
二、功能流程
如图,为整个 Ai Agent 的工作模型;
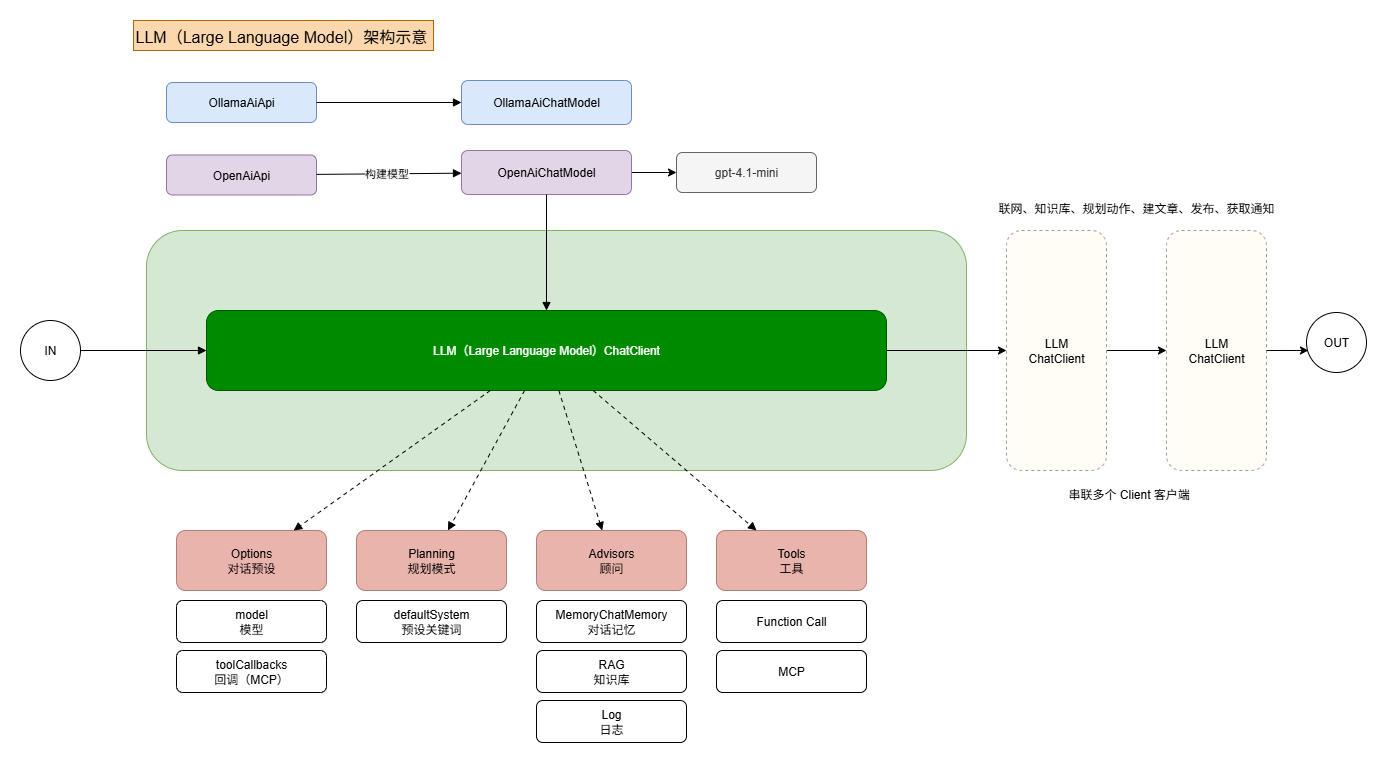
概念:
AI Agent 是一种整合多种技术手段的智能实体,其实现依赖 Tools、MCP、Memory、RAG(Retrieval-Augmented Generation,检索增强生成) 等技术组件进行构建。同时,每一个 Agent Client 之间还可以建立连接与通信,从而进一步增强整体智能体的能力。方案:
在本方案中,我们基于 Spring AI 框架,通过编码的方式将 模型、关键词、顾问角色以及工具 注入到 LLM 客户端中,最终构建出具备对话能力的 LLM 智能体。
三、框架介绍
Spring AI 官方文档:https://docs.spring.io/spring-ai/reference/index.html
<!-- spring ai 1.0.0 https://central.sonatype.com/artifact/org.springframework.ai/spring-ai-bom -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>四、工程实现
1. 工程结构
2. 前置说明
2.1 MCP安装
整个 AI RAG、MCP、Agent 技术文章是一个循序渐进的体系。前面的 RAG 与 MCP 部分,都是为当前 Agent 阶段的整体串联与应用做铺垫。因此,在本节的 Agent 学习中,前面文章所涉及的 MCP 模块 同样会被再次使用,并与其他组件协同完成智能体的构建与运行。你可以把 mcp 服务进行云服务器部署,之后本文就可以对接了。
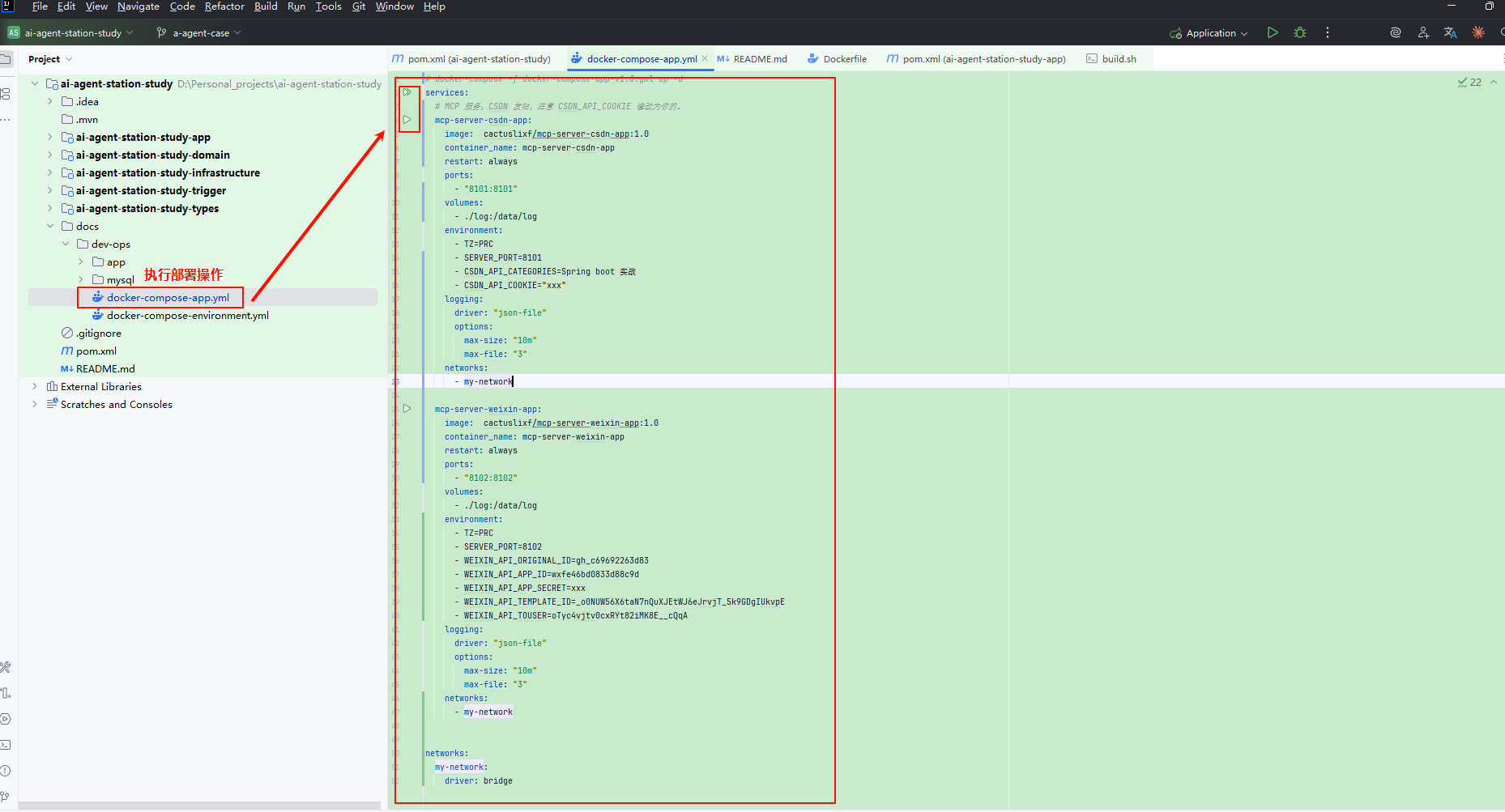
首先,在课程代码 a-agent-case 分支下,dev-ops 部署脚本中提供了两个 MCP 服务 的部署方案。
在使用部署脚本前,需要先完成参数配置:
- CSDN 服务:需配置
cookie信息。 - Weixin 服务:需配置连接参数。
完成参数配置后,可将整个 dev-ops 脚本放置到已安装 Docker 的云服务器上执行,即可完成部署。
2.2 环境安装
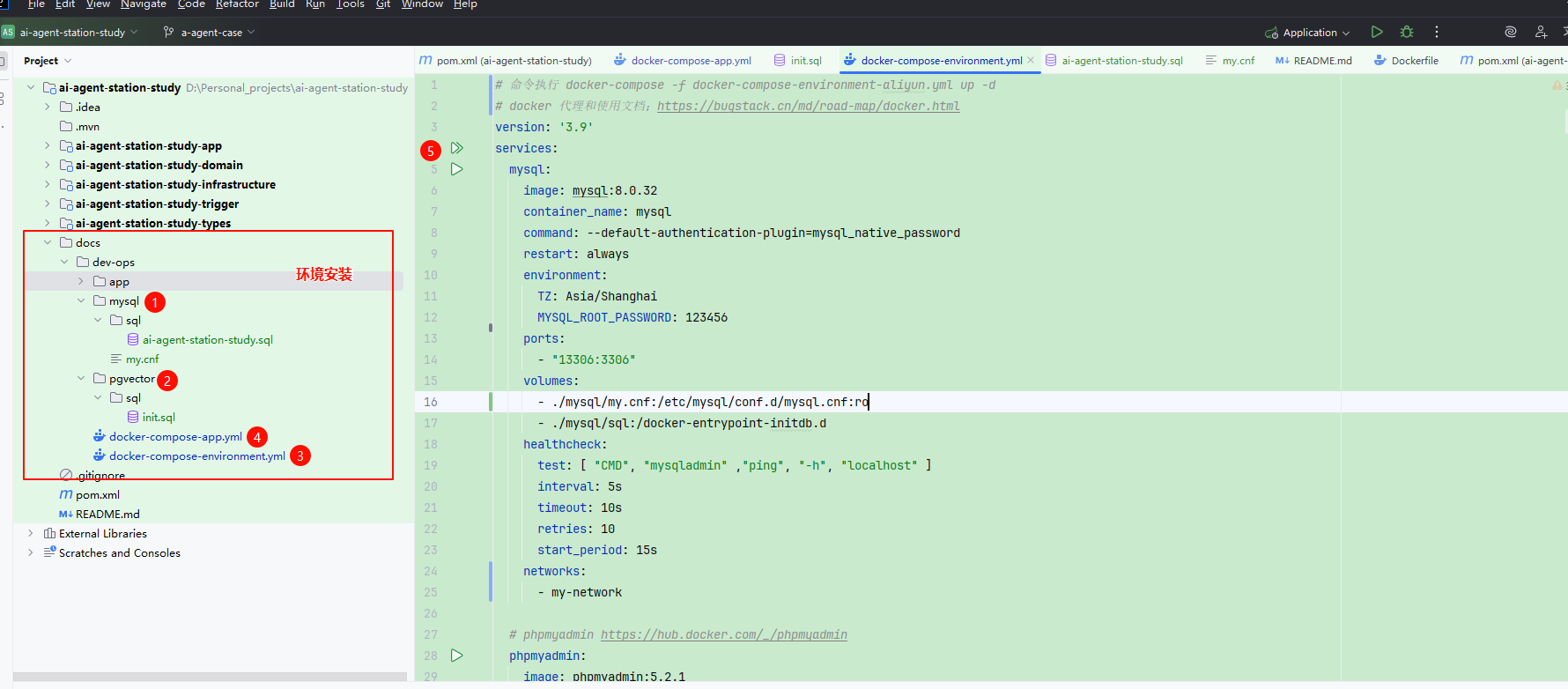
本地安装;Window wsl2 安装 Docker 部署。如果点击绿色按钮执行失败,可以在 powershell 执行命令。Mac Docker,可以直接执行安装操作。
3. 引入Spring AI
3.1 根目录引入框架清单 bom
<!-- spring ai 1.0.1 https://central.sonatype.com/artifact/org.springframework.ai/spring-ai-bom/1.0.1 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>3.2 app 模块下,引入ai框架
<!-- spring ai v1.0.1 start -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- spring ai v1.0.1 stop -->目前的 Spring AI 框架结构非常规整,整体顺序为:Starter → Autoconfig → Model。在实际使用中,只需引入对应的 Starter,即可完成 AI 模型的使用,因为其内部已封装了配置、连接与启动的流程。
在本项目中,我们暂时只需要用到以下组件:
- OpenAI 模型
- PGVector 向量库
- MCP 通信客户端
- 知识库工具包
4. yml 配置
server:
port: 8091
# 线程池配置
thread:
pool:
executor:
config:
core-pool-size: 20
max-pool-size: 50
keep-alive-time: 5000
block-queue-size: 5000
policy: CallerRunsPolicy
# 数据库配置;启动时配置数据库资源信息
spring:
datasource:
username: postgres
password: postgres
url: jdbc:postgresql://192.168.1.23:5432/ai-rag-knowledge
driver-class-name: org.postgresql.Driver
type: com.zaxxer.hikari.HikariDataSource
hikari:
pool-name: Retail_HikariCP
minimum-idle: 15 #最小空闲连接数量
idle-timeout: 180000 #空闲连接存活最大时间,默认600000(10分钟)
maximum-pool-size: 25 #连接池最大连接数,默认是10
auto-commit: true #此属性控制从池返回的连接的默认自动提交行为,默认值:true
max-lifetime: 1800000 #此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
connection-timeout: 30000 #数据库连接超时时间,默认30秒,即30000
connection-test-query: SELECT 1
ai:
vectorstore:
pgvector:
table-name: vector_store_openai
openai:
base-url: https://api.openai.com/
api-key: sk-svcacct-xxxxxx
model: gpt-4.1-mini-2025-04-14
embedding:
base-url: https://api1.oaipro.com/
api-key: sk-xxxxxxx
options:
model: text-embedding-3-small
dimensions: 1536
# MyBatis 配置【如需使用记得打开】
#mybatis:
# mapper-locations: classpath:/mybatis/mapper/*.xml
# config-location: classpath:/mybatis/config/mybatis-config.xml
# 日志
logging:
level:
root: info
config: classpath:logback-spring.xml- 地址:
ai-agent-station-study->ai-agent-station-study-app->application-dev.yml修改配置。 - 配置你的数据库地址
url: jdbc:postgresql://192.168.1.23:15432/ai-rag-knowledge和 ai 下的 openai 对应的 api-key
5. 功能测试
5.1 API 验证
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class OpenAiTest {
@Value("classpath:data/dog.png")
private Resource imageResource;
@Value("classpath:data/file.txt")
private Resource textResource;
@Value("classpath:data/article-prompt-words.txt")
private Resource articlePromptWordsResource;
@Autowired
private OpenAiChatModel openAiChatModel;
@Autowired
private PgVectorStore pgVectorStore;
private final TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
@Test
public void test_call() {
ChatResponse response = openAiChatModel.call(new Prompt(
"1+1",
OpenAiChatOptions.builder()
.model("gpt-5")
.build()));
log.info("测试结果(call):{}", JSON.toJSONString(response));
}
@Test
public void test_call_images() {
UserMessage userMessage = UserMessage.builder()
.text("请描述这张图片的主要内容,并说明图中物品的可能用途。")
.media(org.springframework.ai.content.Media.builder()
.mimeType(MimeType.valueOf(MimeTypeUtils.IMAGE_PNG_VALUE))
.data(imageResource)
.build())
.build();
ChatResponse response = openAiChatModel.call(new Prompt(
userMessage,
OpenAiChatOptions.builder()
.model("gpt-4.1-mini-2025-04-14")
.build()));
log.info("测试结果(images):{}", JSON.toJSONString(response));
}
@Test
public void test_stream() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Flux<ChatResponse> stream = openAiChatModel.stream(new Prompt(
"1+1",
OpenAiChatOptions.builder()
.model("gpt-4.1-mini-2025-04-14")
.build()));
stream.subscribe(
chatResponse -> {
AssistantMessage output = chatResponse.getResult().getOutput();
log.info("测试结果(stream): {}", JSON.toJSONString(output));
},
Throwable::printStackTrace,
() -> {
countDownLatch.countDown();
log.info("测试结果(stream): done!");
}
);
countDownLatch.await();
}
@Test
public void upload() {
// textResource、articlePromptWordsResource
// TikaDocumentReader reader = new TikaDocumentReader(textResource);
TikaDocumentReader reader = new TikaDocumentReader(articlePromptWordsResource);
List<Document> documents = reader.get();
List<Document> documentSplitterList = tokenTextSplitter.apply(documents);
// documentSplitterList.forEach(doc -> doc.getMetadata().put("knowledge", "知识库名称-v1"));
documentSplitterList.forEach(doc -> doc.getMetadata().put("knowledge", "article-prompt-words"));
pgVectorStore.accept(documentSplitterList);
log.info("上传完成");
}
@Test
public void chat() {
String message = "仙人球今年几岁";
String SYSTEM_PROMPT = """
Use the information from the DOCUMENTS section to provide accurate answers but act as if you knew this information innately.
If unsure, simply state that you don't know.
Another thing you need to note is that your reply must be in Chinese!
DOCUMENTS:
{documents}
""";
SearchRequest request = SearchRequest.builder()
.query(message)
.topK(5)
.filterExpression("knowledge == '知识库名称-v1'")
.build();
List<Document> documents = pgVectorStore.similaritySearch(request);
String documentsCollectors = null == documents ? "" : documents.stream().map(Document::getText).collect(Collectors.joining());
Message ragMessage = new SystemPromptTemplate(SYSTEM_PROMPT).createMessage(Map.of("documents", documentsCollectors));
ArrayList<Message> messages = new ArrayList<>();
messages.add(new UserMessage(message));
messages.add(ragMessage);
ChatResponse chatResponse = openAiChatModel.call(new Prompt(
messages,
OpenAiChatOptions.builder()
.model("gpt-4.1-mini-2025-04-14")
.build()));
log.info("测试结果:{}", JSON.toJSONString(chatResponse));
}
}- 常用的 API 以这样几个方法验证,test_call、test_call_images、test_stream、upload、chat 可以分别测试使用。
5.2 Ai Agent 测试
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class AiAgentTest {
private ChatModel chatModel;
private OpenAiEmbeddingModel embeddingModel;
private ChatClient chatClient;
@Resource
private PgVectorStore vectorStore;
public static final String CHAT_MEMORY_CONVERSATION_ID_KEY = "chat_memory_conversation_id";
public static final String CHAT_MEMORY_RETRIEVE_SIZE_KEY = "chat_memory_response_size";
@Before
public void init() {
OpenAiApi openAiApi = OpenAiApi.builder()
.baseUrl("https://chat.199228.xyz/")
.apiKey("sk-n328iNqW8xxxxx")
.completionsPath("v1/chat/completions")
.build();
OpenAiApi embeddingApi = OpenAiApi.builder()
.baseUrl("https://api1.oaipro.com/")
.apiKey("sk-Ez4RmTBQa8pxxxxxx") // 同样的 key 或者不同 key
.embeddingsPath("v1/embeddings")
.build();
chatModel = OpenAiChatModel.builder()
.openAiApi(openAiApi)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4o")
.toolCallbacks(new SyncMcpToolCallbackProvider(stdioMcpClient(), sseMcpClient01(), sseMcpClient02()).getToolCallbacks())
.build())
.build();
embeddingModel = new OpenAiEmbeddingModel(
embeddingApi,
MetadataMode.EMBED,
OpenAiEmbeddingOptions.builder()
.model("text-embedding-3-small")
.build(),
RetryUtils.DEFAULT_RETRY_TEMPLATE);
chatClient = ChatClient.builder(chatModel)
.defaultSystem("""
你是一个 AI Agent 智能体,可以根据用户输入信息生成文章,并发送到 CSDN 平台以及完成微信公众号消息通知,今天是 {current_date}。
你擅长使用Planning模式,帮助用户生成质量更高的文章。
你的规划应该包括以下几个方面:
1. 分析用户输入的内容,生成技术文章。
2. 提取,文章标题(需要含带技术点)、文章内容、文章标签(多个用英文逗号隔开)、文章简述(100字)将以上内容发布文章到CSDN
3. 获取发送到 CSDN 文章的 URL 地址。
4. 微信公众号消息通知,平台:CSDN、主题:为文章标题、描述:为文章简述、跳转地址:从发布文章到CSDN获取 URL 地址
""")
// .defaultToolCallbacks(new SyncMcpToolCallbackProvider(stdioMcpClient(), sseMcpClient01(), sseMcpClient02()).getToolCallbacks())
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(100)
.build()
).build(),
new RagAnswerAdvisor(vectorStore, SearchRequest.builder()
.topK(5)
.filterExpression("knowledge == '知识库名称-v1'")
.build()),
SimpleLoggerAdvisor.builder().build())
.build();
}
@Test
public void test_chat_model_stream_01() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Prompt prompt = Prompt.builder()
.messages(new UserMessage(
"""
有哪些工具可以使用
"""))
.build();
// 非流式,chatModel.call(prompt)
Flux<ChatResponse> stream = chatModel.stream(prompt);
stream.subscribe(
chatResponse -> {
AssistantMessage output = chatResponse.getResult().getOutput();
log.info("测试结果: {}", JSON.toJSONString(output));
},
Throwable::printStackTrace,
() -> {
countDownLatch.countDown();
System.out.println("Stream completed");
}
);
countDownLatch.await();
}
@Test
public void test_chat_model_call() {
Prompt prompt = Prompt.builder()
.messages(new UserMessage(
"""
有哪些工具可以使用
"""))
.build();
ChatResponse chatResponse = chatModel.call(prompt);
log.info("测试结果(call):{}", JSON.toJSONString(chatResponse));
}
@Test
public void test_02() {
String userInput = "仙人球今年几岁?";
System.out.println("\n>>> QUESTION: " + userInput);
System.out.println("\n>>> ASSISTANT: " + chatClient
.prompt()
.system(s -> s.param("current_date", LocalDate.now().toString()))
.user(userInput)
.call().content());
}
@Test
public void test_client03() {
ChatClient chatClient01 = ChatClient.builder(chatModel)
.defaultSystem("""
你是一个专业的AI提示词优化专家。请帮我优化以下prompt,并按照以下格式返回:
# Role: [角色名称]
## Profile
- language: [语言]
- description: [详细的角色描述]
- background: [角色背景]
- personality: [性格特征]
- expertise: [专业领域]
- target_audience: [目标用户群]
## Skills
1. [核心技能类别]
- [具体技能]: [简要说明]
- [具体技能]: [简要说明]
- [具体技能]: [简要说明]
- [具体技能]: [简要说明]
2. [辅助技能类别]
- [具体技能]: [简要说明]
- [具体技能]: [简要说明]
- [具体技能]: [简要说明]
- [具体技能]: [简要说明]
## Rules
1. [基本原则]:
- [具体规则]: [详细说明]
- [具体规则]: [详细说明]
- [具体规则]: [详细说明]
- [具体规则]: [详细说明]
2. [行为准则]:
- [具体规则]: [详细说明]
- [具体规则]: [详细说明]
- [具体规则]: [详细说明]
- [具体规则]: [详细说明]
3. [限制条件]:
- [具体限制]: [详细说明]
- [具体限制]: [详细说明]
- [具体限制]: [详细说明]
- [具体限制]: [详细说明]
## Workflows
- 目标: [明确目标]
- 步骤 1: [详细说明]
- 步骤 2: [详细说明]
- 步骤 3: [详细说明]
- 预期结果: [说明]
## Initialization
作为[角色名称],你必须遵守上述Rules,按照Workflows执行任务。
请基于以上模板,优化并扩展以下prompt,确保内容专业、完整且结构清晰,注意不要携带任何引导词或解释,不要使用代码块包围。
""")
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(100)
.build()
).build(),
new RagAnswerAdvisor(vectorStore, SearchRequest.builder()
.topK(5)
.filterExpression("knowledge == 'article-prompt-words'")
.build())
)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4o")
.build())
.build();
String content = chatClient01
.prompt("生成一篇文章")
.system(s -> s.param("current_date", LocalDate.now().toString()))
.advisors(a -> a
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, "chatId-101")
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.call().content();
System.out.println("\n>>> ASSISTANT: " + content);
ChatClient chatClient02 = ChatClient.builder(chatModel)
.defaultSystem("""
你是一个 AI Agent 智能体,可以根据用户输入信息生成文章,并发送到 CSDN 平台以及完成微信公众号消息通知,今天是 {current_date}。
你擅长使用Planning模式,帮助用户生成质量更高的文章。
你的规划应该包括以下几个方面:
1. 分析用户输入的内容,生成技术文章。
2. 提取,文章标题(需要含带技术点)、文章内容、文章标签(多个用英文逗号隔开)、文章简述(100字)将以上内容发布文章到CSDN
3. 获取发送到 CSDN 文章的 URL 地址。
4. 微信公众号消息通知,平台:CSDN、主题:为文章标题、描述:为文章简述、跳转地址:为发布文章到CSDN获取 URL地址 CSDN文章链接 https 开头的地址。
""")
// .defaultTools(new SyncMcpToolCallbackProvider(sseMcpClient01(), sseMcpClient02()))
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(100)
.build()
).build(),
new SimpleLoggerAdvisor()
)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4o")
.build())
.build();
String userInput = "生成一篇文章,要求如下 \r\n" + content;
System.out.println("\n>>> QUESTION: " + userInput);
System.out.println("\n>>> ASSISTANT: " + chatClient02
.prompt(userInput)
.system(s -> s.param("current_date", LocalDate.now().toString()))
.advisors(a -> a
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, "chatId-101")
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.call().content());
}
public McpSyncClient stdioMcpClient() {
// based on
// https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem
// windows -- > npx.cmd -y @modelcontextprotocol/server-filesystem C:\path\to\serve C:\path\to\workspace
// mac/linux --> npx -y @modelcontextprotocol/server-filesystem /path/to/serve /path/to/workspace
var stdioParams = ServerParameters.builder("npx.cmd")
.args("-y", "@modelcontextprotocol/server-filesystem", "C:\\Users\\Dell\\Desktop", "C:\\Users\\Dell\\Desktop")
.build();
var mcpClient = McpClient.sync(new StdioClientTransport(stdioParams))
.requestTimeout(Duration.ofSeconds(10)).build();
var init = mcpClient.initialize();
System.out.println("Stdio MCP Initialized: " + init);
return mcpClient;
}
public McpSyncClient sseMcpClient01() {
HttpClientSseClientTransport sseClientTransport = HttpClientSseClientTransport.builder("http://192.168.1.23:8102").build();
McpSyncClient mcpSyncClient = McpClient.sync(sseClientTransport).requestTimeout(Duration.ofMinutes(180)).build();
var init = mcpSyncClient.initialize();
System.out.println("SSE MCP Initialized: " + init);
return mcpSyncClient;
}
public McpSyncClient sseMcpClient02() {
HttpClientSseClientTransport sseClientTransport = HttpClientSseClientTransport.builder("http://192.168.1.23:8101").build();
McpSyncClient mcpSyncClient = McpClient.sync(sseClientTransport).requestTimeout(Duration.ofMinutes(180)).build();
var init = mcpSyncClient.initialize();
System.out.println("SSE MCP Initialized: " + init);
return mcpSyncClient;
}
}在 AiAgentTest.init 初始化方法 中,会依次创建:
- openAiApi
- chatModel
- chatClient
并在此过程中完成 MCP 服务 与 顾问角色(访问知识库与上下文记忆)的初始化。这里使用的 MCP 服务,即为前面已部署的 CSDN 与 Weixin 两个基于 SSE 的 MCP 服务。
⚠️ 注意事项:
stdioMcpClient路径需要修改为你本机的实际路径,例如:C:\\Users\\Dell\\Desktop。- 本机需要安装 Node.js,可从 Node.js 官方网站 下载并安装。
接下来,需要分别验证以下几个测试方法:
- test_chat_model_stream_01
- test_chat_model_call
- test_02
- test_client03
完成上述验证后,即可为后续 库表设计 提供依据,并进一步指导 功能实现的细化。