AiAgent业务流程、系统架构、库表设计说明
一、本章目标
了解 AI Agent 的构建要素,结合 Spring AI 的硬编码方式分析 Agent 的创建流程,剖析各个模块的作用,并在此基础上设计元素拆分及对应的库表结构。
通过本节内容,我们能够掌握如何将这些硬编码的流程转化为基于数据库表配置的动态化构建方式。借助动态化构建机制,即可按需配置多样化的 Agent 服务,以满足不同的业务需求。尤其是在当前 MCP 快速发展的背景下,具备一套自动化的 Agent 体系显得尤为关键。
本节主要站在开发视角,来讲解如何架构和开发系统。
二、Agent 介绍
AI 智能体是一类利用人工智能实现目标,并能代表用户完成任务的软件系统。它具备推理、规划和记忆等能力,具有一定的自主性,能够自主学习、适应环境并作出决策。
这些能力主要得益于生成式 AI 与基础模型的多模态特性。AI 智能体能够同时处理文本、语音、视频、音频和代码等多模态信息,并开展对话、推
理、学习与决策。它们可以随着时间不断进化,简化事务与业务流程,同时还能与其他智能体协作,协同执行更加复杂的工作流。
Spring AI 框架支持基于大语言模型的 AI Agent 构建与实现。AI Agent 作为一种整合多种技术的智能实体,其实现通常依赖于 Tools、MCP、Memory、RAG(检索增强生成)等组件。但需要注意的是,AI Agent 的实现并非必须依赖全部组件,合理选择与组合即可完成相应功能。
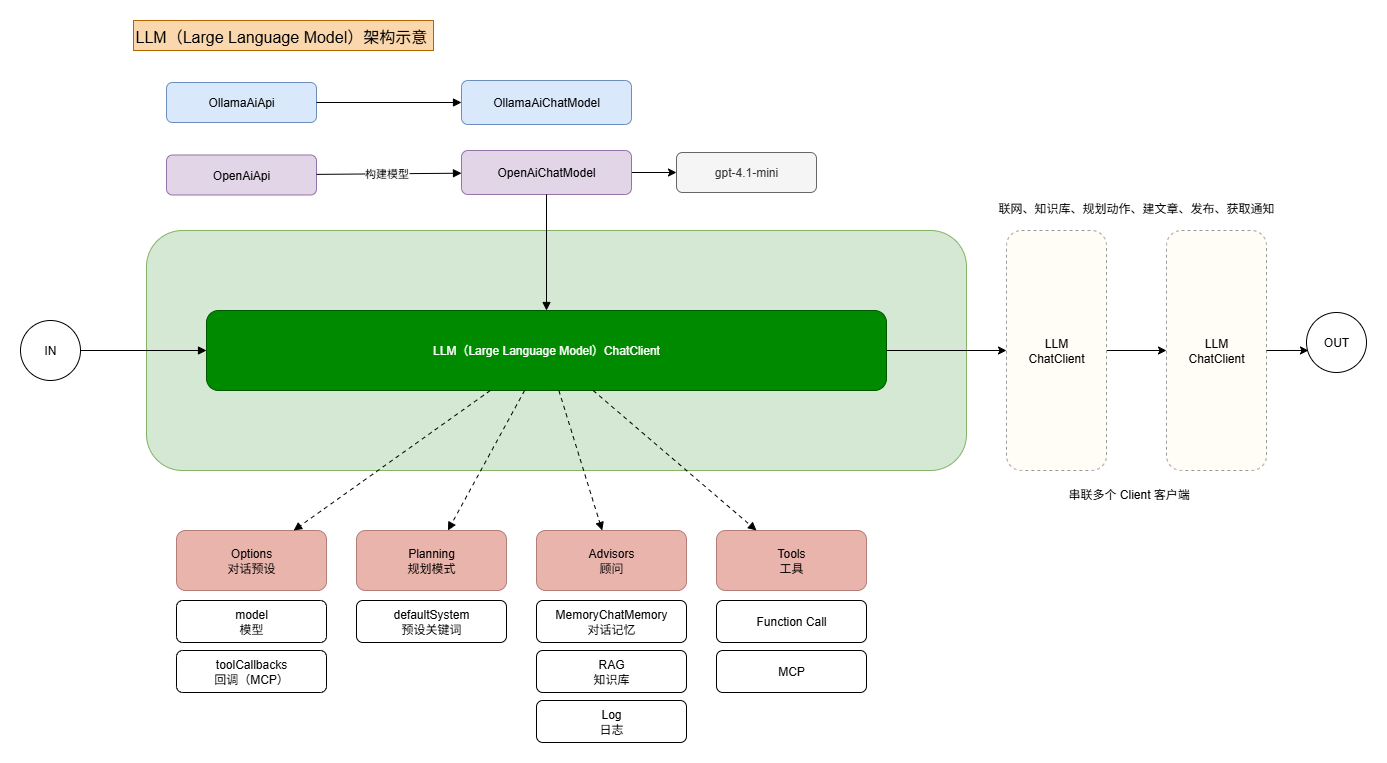
如图所示,以 ChatClient 为核心,配置 AI 模型、对话预热、规划模式、顾问以及工具等要素,完成 LLM ChatClient 的构建。这些注入的元素属性,共同驱动了 Agent 功能的实现。
在会话过程中,从输入端到输出端,可以顺序执行多个 ChatClient。通过这种方式,不同配置的 ChatClient 能够发挥各自的作用,协同推动最终目标的达成。
对话预设:该节点在 ChatModel 中配置,可指定对话使用的 AI 模型,也可设置 MCP。ChatModel 支持流式对话,并可作为依赖注入到 ChatClient 中使用。
规划模式:基于预设关键词,使流程能够明确以哪些关键信息为驱动进行运行。
顾问角色:Spring AI 提供了一种更优雅的外部元素访问信息的方式,即 顾问访问。借助顾问功能,可增强对话能力,包括上下文记忆、知识库检索、日志处理等。
工具加载:此处主要采用 MCP,这是当前业界最为流行的方式之一。
三、Agent 代码
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class AiAgentTest {
@Before
public void init_client() {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.openAiApi(OpenAiApi.builder()
.baseUrl("https://api.openai.com/")
.apiKey("sk-lIqVNiHon00O6veJ15Cc57DaF5Dd401f93B3A107B4B3677e")
.completionsPath("v1/chat/completions")
.embeddingsPath("v1/embeddings")
.build())
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4.1")
.toolCallbacks(
FunctionToolCallback.builder("test",
(Function<TestFunctionInput, String>) testFunctionInput -> {
log.info("函数请求:{}", testFunctionInput.getInput());
return "仙人球今天入职啦!";
})
.description("仙人球")
.inputType(TestFunctionInput.class)
.build())
.toolCallbacks(new SyncMcpToolCallbackProvider(sseMcpClient01(), sseMcpClient02()).getToolCallbacks())
.build())
.build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("""
你是一个 AI Agent 智能体,可以根据用户输入信息生成文章,并发送到 CSDN 平台以及完成微信公众号消息通知,今天是 {current_date}。
你擅长使用Planning模式,帮助用户生成质量更高的文章。
你的规划应该包括以下几个方面:
1. 分析用户输入的内容,生成技术文章。
2. 提取,文章标题(需要含带技术点)、文章内容、文章标签(多个用英文逗号隔开)、文章简述(100字)将以上内容发布文章到CSDN
3. 获取发送到 CSDN 文章的 URL 地址。
4. 微信公众号消息通知,平台:CSDN、主题:为文章标题、描述:为文章简述、跳转地址:从发布文章到CSDN获取 URL 地址
""")
.defaultToolCallbacks(new SyncMcpToolCallbackProvider(sseMcpClient01(), sseMcpClient02()))
.defaultAdvisors(
new PromptChatMemoryAdvisor(new InMemoryChatMemory()),
new RagAnswerAdvisor(vectorStore, SearchRequest.builder()
.topK(5)
.filterExpression("knowledge == '知识库名称'")
.build()),
new SimpleLoggerAdvisor()
)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4.1")
.toolCallbacks(
FunctionToolCallback.builder("test",
(Function<TestFunctionInput, String>) testFunctionInput -> {
log.info("函数请求:{}", testFunctionInput.getInput());
return "仙人球今天入职啦!";
})
.description("仙人球")
.inputType(TestFunctionInput.class)
.build())
.build())
.build();
}
public McpSyncClient sseMcpClient02() {
HttpClientSseClientTransport sseClientTransport = HttpClientSseClientTransport.builder("http://192.168.1.218:8101").build();
McpSyncClient mcpSyncClient = McpClient.sync(sseClientTransport).requestTimeout(Duration.ofMinutes(180)).build();
var init = mcpSyncClient.initialize();
System.out.println("SSE MCP Initialized: " + init);
return mcpSyncClient;
}
public McpSyncClient stdioMcpClient() {
// based on
// https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem
var stdioParams = ServerParameters.builder("npx")
.args("-y", "@modelcontextprotocol/server-filesystem", "/Users/Dell/Desktop", "/Users/Dell/Desktop")
.build();
var mcpClient = McpClient.sync(new StdioClientTransport(stdioParams))
.requestTimeout(Duration.ofSeconds(10)).build();
var init = mcpClient.initialize();
System.out.println("Stdio MCP Initialized: " + init);
return mcpClient;
}
@Test
public void test_client02() {
String userInput = "生成一篇文章";
System.out.println("\n>>> QUESTION: " + userInput);
System.out.println("\n>>> ASSISTANT: " + chatClient
.prompt(userInput)
.system(s -> s.param("current_date", LocalDate.now().toString()))
.advisors(a -> a
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, "chatId-101")
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.call().content());
}
@Test
public void test_clien03() {
String userInput = "有哪些工具可以使用";
System.out.println("\n>>> QUESTION: " + userInput);
System.out.println("\n>>> ASSISTANT: " + chatClient
.prompt(userInput)
.system(s -> s.param("current_date", LocalDate.now().toString()))
.advisors(a -> a
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, "chatId-101")
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.call().content());
}
}首先,这部分代码可以视为 AI Agent 自动化构建的雏形。整个流程涵盖了模型的创建、工具(MCP)的加载、预设话术的配置、顾问角色对上下文记忆与知识库的处理、客户端的构建,以及最终的客户端验证。
我们的目标,是将这些原本依赖硬编码的实现进行解耦,转化为 数据库配置 + 程序化自动处理 的方式,来完成各个 Bean 对象的构建与使用。通过这种机制,我们可以灵活配置任意一套 Agent 服务,例如指定是否接入知识库、是否启用 MCP、以及选择相应的预设话术,从而满足不同业务场景的需求。
更进一步,这类 Agent 服务不仅可以串联多个 Agent,还能结合 自动化任务(Job)驱动 与 人工对话交互,以支持日常功能的高效运行。
想象一下,有了这样的体系,AI Agent 将能够帮助我们完成大量日常工作,例如:系统监控与巡检、异常问题的根因分析、日常活动的自动化运营、需求与代码的前置分析、自动化客户端对话等。
四、Agent 流程
1. 功能流程
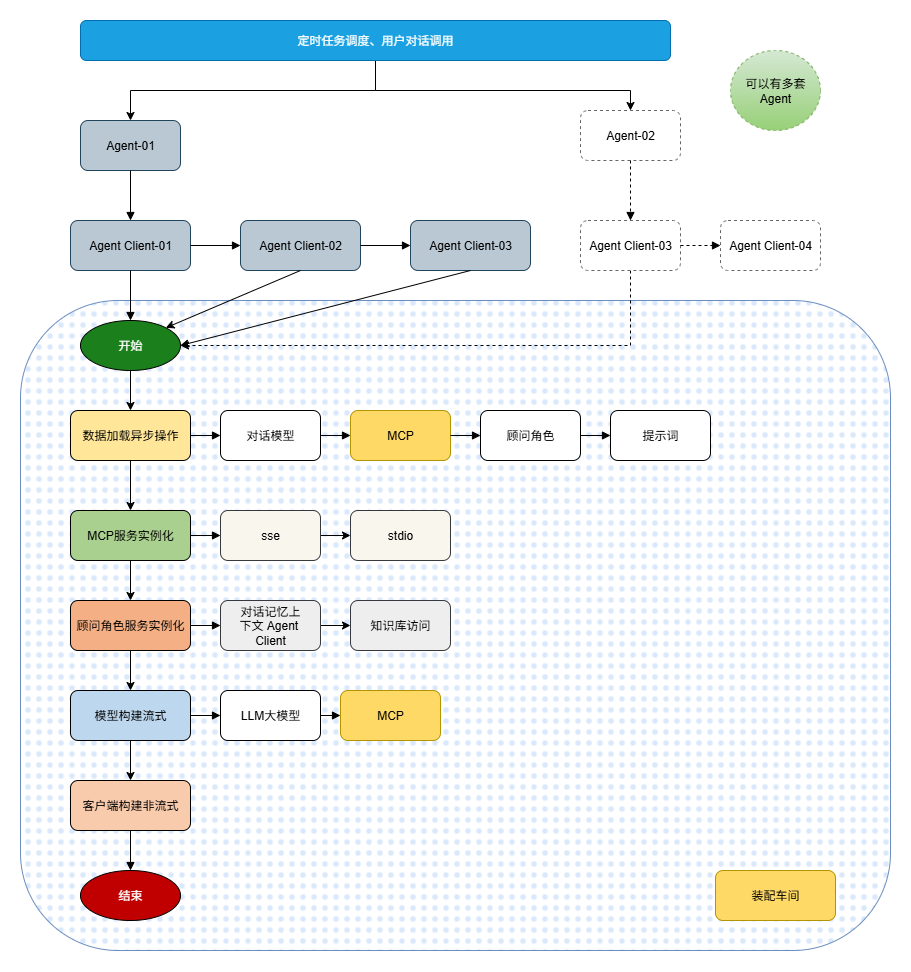
如图所示,我们将整个代码的构建过程进行了拆分:上半部分负责 Agent 功能的编排与触达,下半部分则是 各个 Agent Client 的预热与装配流程。
这种装配方式基于数据库表的配置,在应用程序启动时,或通过管理后台的人工触发来完成 Agent Client 的构建。
构建过程包括:数据异步加载、MCP 服务实例化、顾问角色处理、模型构建以及客户端构建。
2. 代码流程
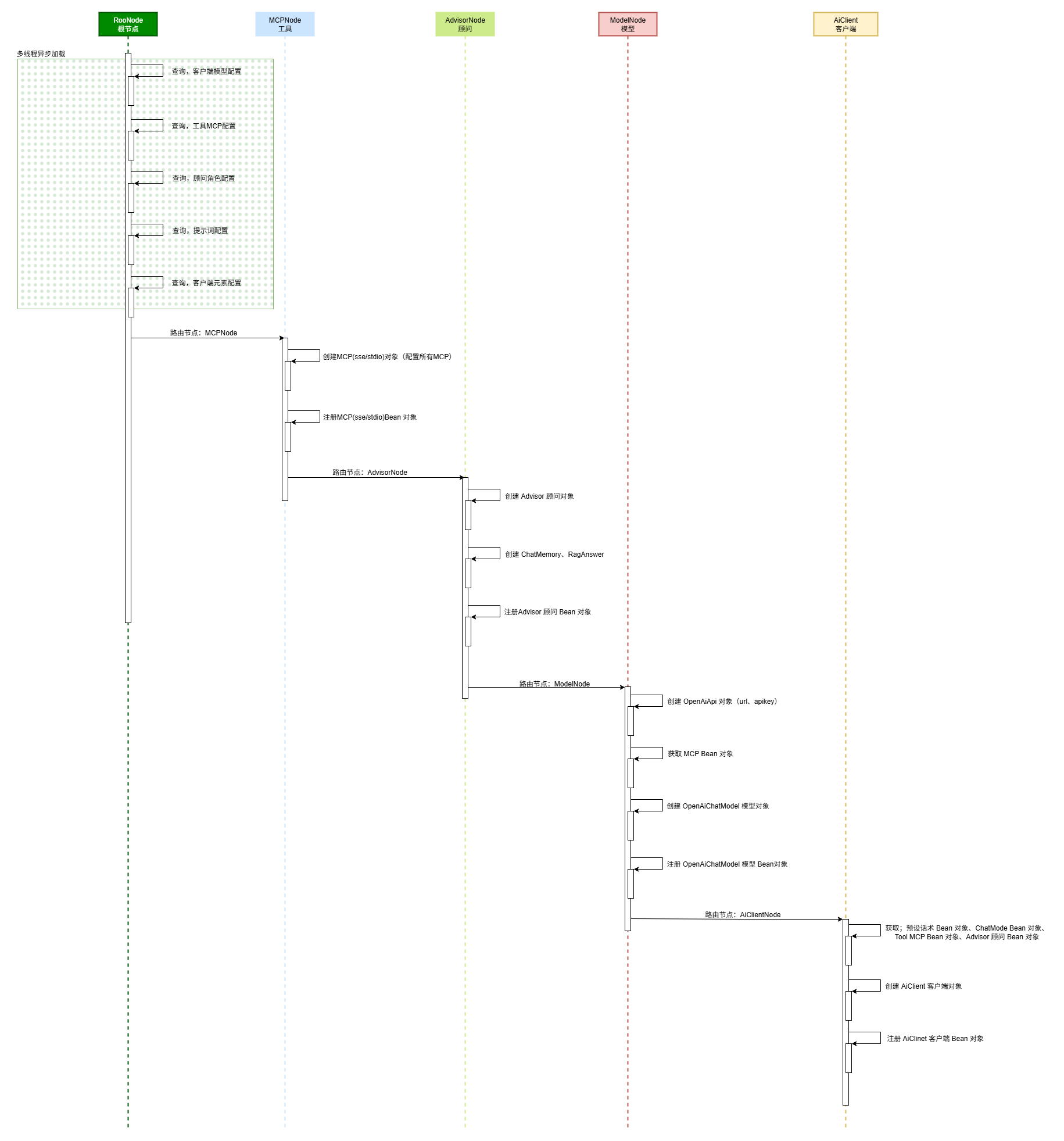
- 如图所示,这是 Agent 动态化创建的核心流程。流程首先以多线程方式完成数据加载,随后依次创建 MCP 工具、顾问角色与对话模型,最后构建 Client 客户端。
五、Agent 库表
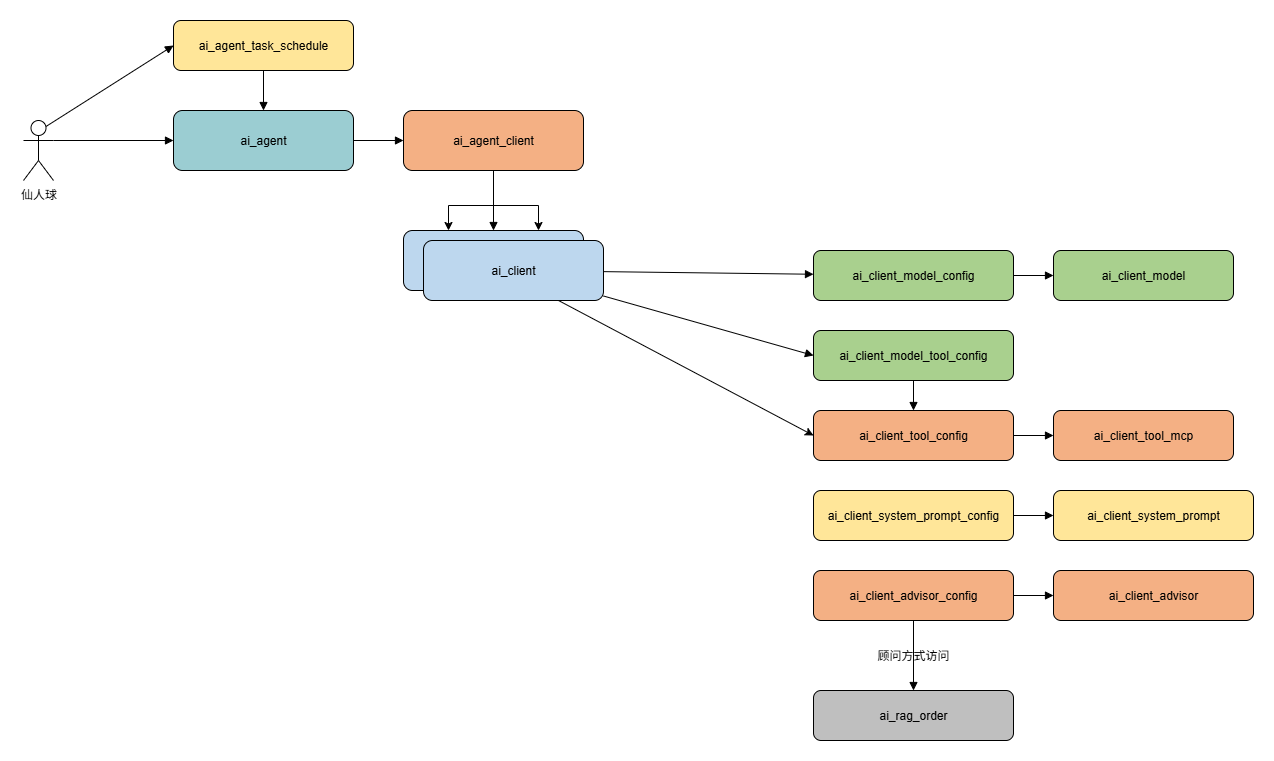
如图所示,系统共设计了 14 张数据库表,用于支撑自动化 AI Agent 的构建与运行。其结构划分如下:
1. 核心配置
- ai_agent_task_schedule:智能体任务调度配置表
- ai_agent:AI 智能体配置表
- ai_agent_client:智能体与客户端的关联表
- ai_client:AI 客户端配置表
2. 模型配置组
- ai_client_model:客户端模型定义表
- ai_client_model_config:模型参数配置表
- ai_client_model_tool_config:模型与工具的配置表
3. 工具配置组
- ai_client_tool_config:客户端工具配置表
- ai_client_tool_mcp:MCP 工具配置表
4. 顾问配置组
- ai_client_advisor:顾问角色配置表
- ai_client_advisor_config:顾问参数与扩展配置表
5. 提示词配置
- ai_client_system_prompt:系统提示词定义表
- ai_client_system_prompt_config:系统提示词参数配置表
6. 知识库配置
- ai_rag_order:RAG(检索增强生成)知识库配置表
六、Agent 工程
如图所示,整个系统的工程结构采用 六边形架构,主要分为六个部分:api、app、domain、infrastructure、trigger、types。目前各大互联网公司也在积极落地 DDD(领域驱动设计),相较于早期阶段,如今 DDD 已形成更加清晰和成熟的规范(参考资料:DDD 指南)。
核心分层说明
- Domain(核心领域层)
负责处理 Agent 的预热、对话、知识库以及任务相关操作。未来所有与 Agent 强相关的逻辑都会维护在该领域层中,以保证领域模型的统一与完整性。 - Trigger(触发器层)
主要职责是对外提供接口,供外部系统调用。当涉及到一些简单的 CRUD 操作时,可以在 Trigger 层直接调用基础设施层的数据服务,而无需通过 Domain 层进行冗余的对象封装,从而提高效率。