AgentFlow执行链路分析
2025年10月15日...大约 12 分钟
一、介绍
为了更好地展示 Agent 的实现思路,本章我们将增加一种新的 Auto Agent 设计。该设计基于用户提问和当前 Agent 配置的 MCP 工具集合,进行执行步骤的规划与设计。接着,系统会按照拆分后的步骤顺序号依次执行这些步骤,类似于 manus 的流程。
这种设计使得 Agent 能够更智能地根据不同的需求进行步骤规划,确保任务的高效执行。
二、功能流程
如图,多种 Ai Agent 执行设计流程图;
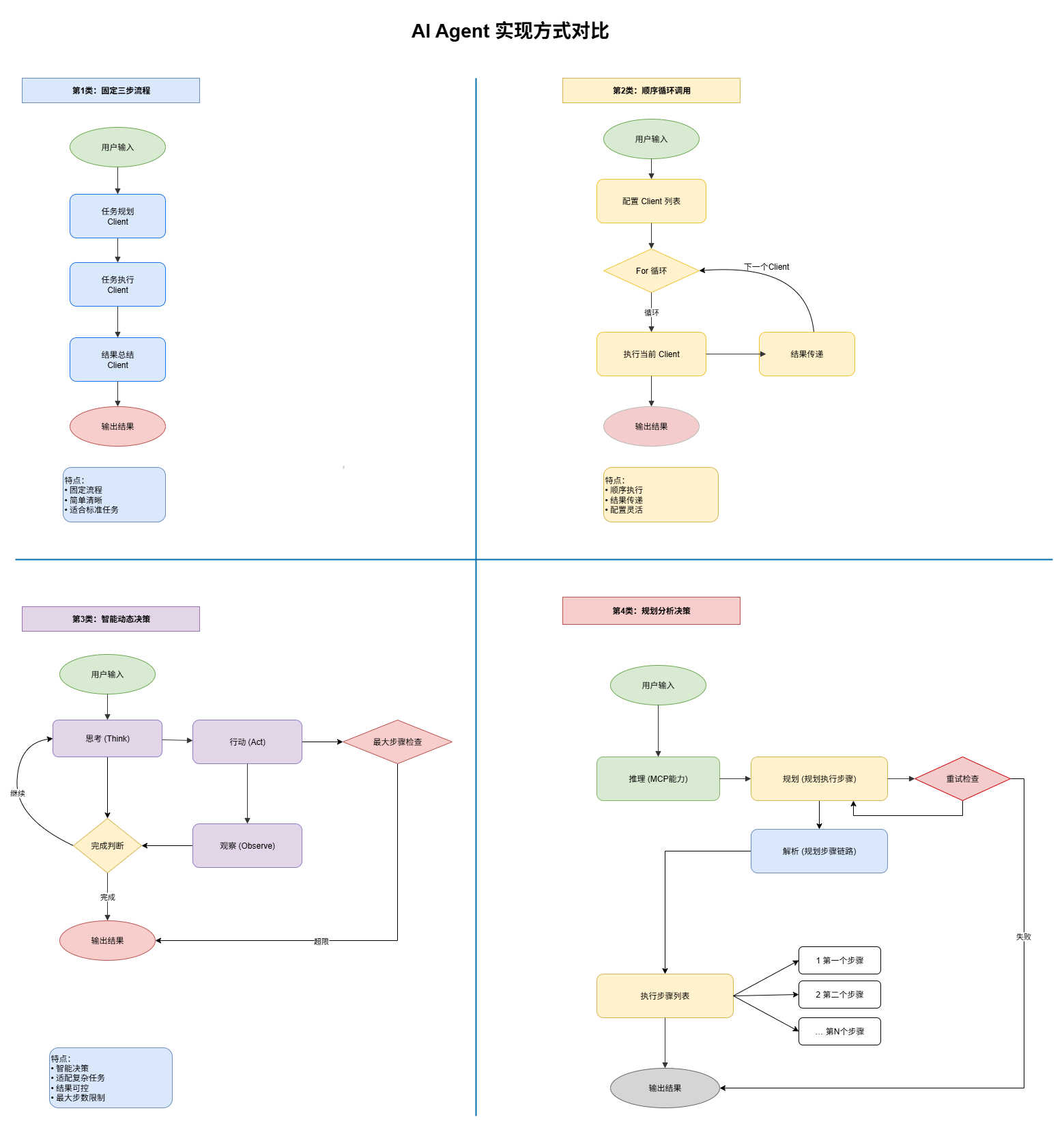
Ai Agent 的处理过程可以分为几类,以适应不同的场景需求:
- 固定步骤:适用于配置工作流,确保任务执行的准确性。例如,检索资料、发送帖子、处理通知等。
- 顺序循环调用:配置多个 Client 端任务,按照预定顺序执行。适合简单任务和已分配好的动作,类似于固定步骤的方式。
- 智能动态决策:这是市面上常见的 Agent 实现方式。它会动态规划执行步骤,监控执行结果,判断完成状态,最终给出结果。
- 规划分析决策(新增):根据用户输入的需求和配置的 MCP 能力,进行步骤规划。之后将步骤拆解成 1、2、3 的具体任务,并按顺序执行。
三、编码分析
本节主要以 FlowAgent 单测的方式学习 Agent 执行过程;
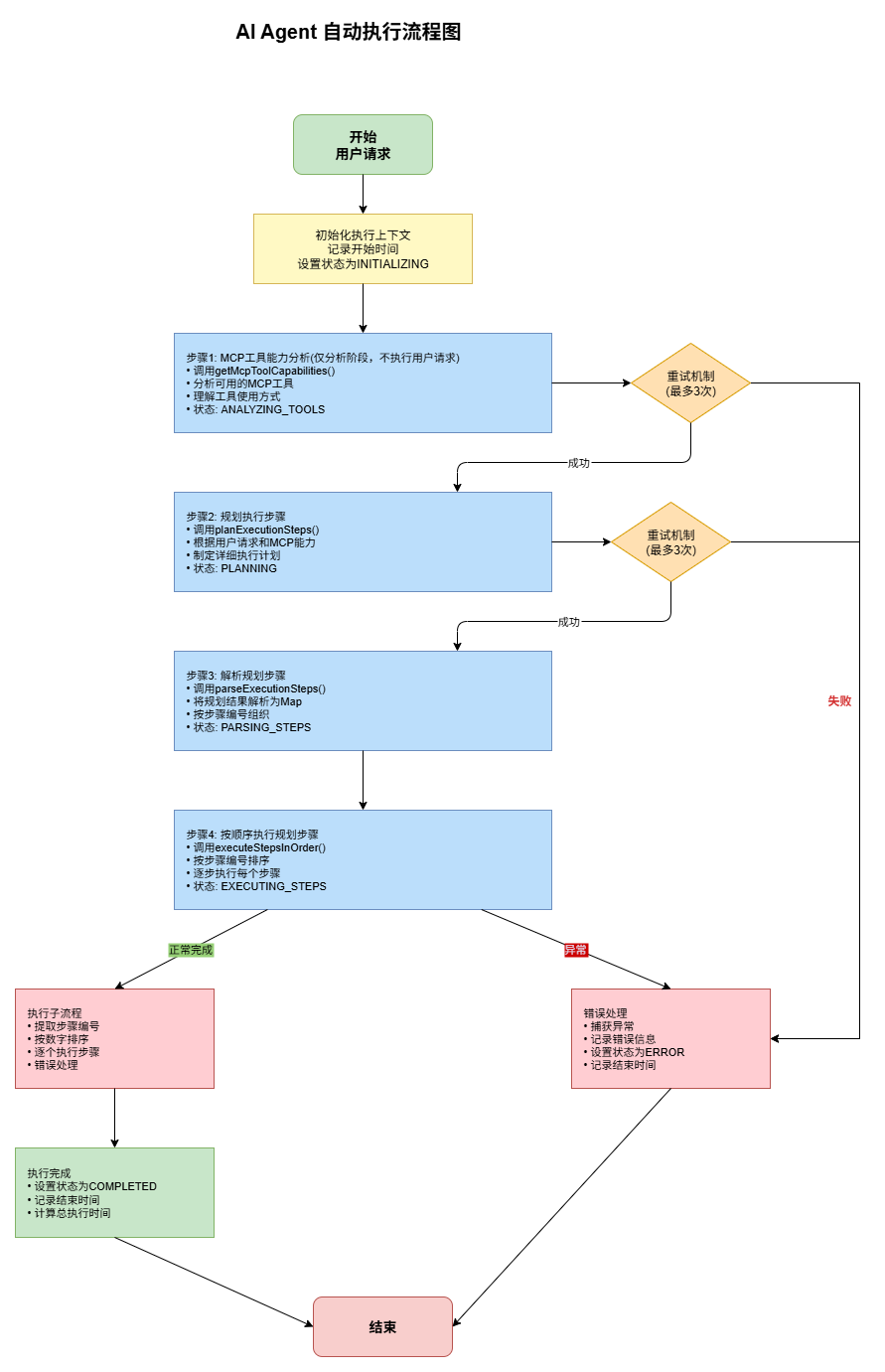
MCP 工具能力评估:仅评估可用工具与能力边界,不执行用户请求。
制定执行方案:根据用户诉求规划整体流程与步骤。
步骤解析入列:将方案拆解为原子化步骤,存为待执行队列。
按序执行:按既定顺序逐一执行,直至全部完成。
1. 前置配置
单元测类;cn.bugstack.ai.test.spring.ai.FlowAgentTest
本节我们将使用在第 2 阶段中实现的两个 MCP 服务:CSDN 文章发布、微信公众号消息推送。
在开始之前,请确保你已经完成前面章节的学习和配置。如果尚未学习,可以回看之前的内容;如果已经了解,可直接进行本节的配置与操作。
# docker-compose -f docker-compose-app-v1.0.yml up -d
services:
# ai-mcp-cactusli-app
ai-mcp-cactusli-app:
image: cactuslixf/ai-mcp-cactusli-app:1.0
container_name: ai-mcp-cactusli-app
restart: always
ports:
- "8090:8090"
volumes:
- ./log:/data/log
- ./mcp/config:/mcp/config
- ./mcp/jar:/mcp/jar
environment:
- TZ=PRC
- SERVER_PORT=8090
- SPRING_DATASOURCE_USERNAME=postgres
- SPRING_DATASOURCE_PASSWORD=postgres
- SPRING_DATASOURCE_URL=jdbc:postgresql://vector_db:5432/ai-rag-cactusli
- SPRING_DATASOURCE_DRIVER_CLASS_NAME=org.postgresql.Driver
- SPRING_AI_OLLAMA_BASE_URL=http://118.189.227.190:11434
- SPRING_AI_OLLAMA_EMBEDDING_OPTIONS_NUM_BATCH=512
- SPRING_AI_OLLAMA_MODEL=nomic-embed-text
- SPRING_AI_OPENAI_BASE_URL=https://api.openai.com/
- SPRING_AI_OPENAI_API_KEY=xxx
- CRON_EXPRESSION=0 * * * * ?
- SPRING_AI_OPENAI_EMBEDDING_OPTIONS_MODEL=text-embedding-3-small
- SPRING_AI_RAG_EMBEDDING=text-embedding-3-small
- SPRING_AI_MCP_CLIENT_SSE_CONNECTIONS_MCP_SERVER_CSDN_URL=http://mcp-server-csdn-app:8101
- SPRING_AI_MCP_CLIENT_SSE_CONNECTIONS_MCP_SERVER_WEIXIN_URL=http://mcp-server-weixin-app:8102
- REDIS_SDK_CONFIG_HOST=redis
- REDIS_SDK_CONFIG_PORT=6379
- REDIS_SDK_CONFIG_PASSWORD=xxx
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
depends_on:
- mcp-server-csdn-app
- mcp-server-weixin-app
networks:
- my-network
mcp-server-csdn-app:
image: cactuslixf/mcp-server-csdn-app:1.0
container_name: mcp-server-csdn-app
restart: always
ports:
- "8101:8101"
volumes:
- ./log:/data/log
environment:
- TZ=PRC
- SERVER_PORT=8101
- CSDN_API_CATEGORIES=Spring boot 实战
- CSDN_API_COOKIE="xxx"
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
networks:
- my-network
mcp-server-weixin-app:
image: cactuslixf/mcp-server-weixin-app:1.0
container_name: mcp-server-weixin-app
restart: always
ports:
- "8102:8102"
volumes:
- ./log:/data/log
environment:
- TZ=PRC
- SERVER_PORT=8102
- WEIXIN_API_ORIGINAL_ID=gh_c69692263d83
- WEIXIN_API_APP_ID=wxfe46bd0833d88c9d
- WEIXIN_API_APP_SECRET=xxx
- WEIXIN_API_TEMPLATE_ID=_o0NUW56X6taN7nQuXJEtWJ6eJrvjT_5k9GDgIUkvpE
- WEIXIN_API_TOUSER=oTyc4vjtv0cxRYt82iMK8E__cQqA
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
networks:
- my-network
networks:
my-network:
driver: bridge- 相关的配置具体可参考: https://cactusli.net/tutorials/projects/ai-mcp-cactusli/5.Deploying-and-launching-MCP-service-sse-mode.html
2. 初始服务 - ChatClient
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class FlowAgentTest {
private ChatModel chatModel;
private ChatClient planningChatClient;
private ChatClient executorChatClient;
private ChatClient mcpToolsChatClient;
@Resource
private PgVectorStore vectorStore;
public static final String CHAT_MEMORY_CONVERSATION_ID_KEY = "chat_memory_conversation_id";
public static final String CHAT_MEMORY_RETRIEVE_SIZE_KEY = "chat_memory_response_size";
@Before
public void init() {
OpenAiApi openAiApi = OpenAiApi.builder()
.baseUrl("https://api.colin1112.me")
.apiKey("sk-R6vO2911ht4zw79wwf2VB7eWj0c2H4YJfPBF6I1b5AqfMeiz")
.completionsPath("v1/chat/completions")
.embeddingsPath("v1/embeddings")
.build();
chatModel = OpenAiChatModel.builder()
.openAiApi(openAiApi)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-oss-120b")
.maxTokens(5000)
.toolCallbacks(new SyncMcpToolCallbackProvider(sseMcpClient_BaiduSearch(), sseMcpClient_csdn(), sseMcpClient02_weixin()).getToolCallbacks())
.build())
.build();
planningChatClient = ChatClient.builder(chatModel)
.defaultSystem("""
# 角色
你是一个智能任务规划助手,名叫 AutoAgent Planning。
# 说明
你是任务规划助手,根据用户需求,拆解任务列表,制定执行计划。重点是生成大粒度、可执行的任务步骤,避免过度细分。
# 技能
- 擅长将用户任务拆解为具体、独立、大粒度的任务列表
- 避免过度拆解,保持任务的完整性和可执行性
- 每个任务应该是一个完整的业务流程,而不是细碎的操作步骤
# 处理需求
## 拆解原则
- 深度推理分析用户输入,识别核心需求
- 将复杂问题分解为3-5个大粒度的主要任务
- 每个任务应该包含完整的业务逻辑,可以独立完成
- 任务按业务流程顺序组织,逻辑清晰
- 避免将一个完整流程拆分成多个细小步骤
## 输出格式
请按以下格式输出任务计划:
**任务规划:**
1. [任务1描述] - 包含完整的业务流程
2. [任务2描述] - 包含完整的业务流程
3. [任务3描述] - 包含完整的业务流程
...
**执行策略:**
[整体执行策略说明]
今天是 {current_date}。
""")
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(50)
.build()
).build(),
new RagAnswerAdvisor(vectorStore, SearchRequest.builder()
.topK(5)
.filterExpression("knowledge == 'article'")
.build()))
.build();
// 初始化执行器客户端
executorChatClient = ChatClient.builder(chatModel)
.defaultSystem("""
# 角色定义
你是一个专业的任务执行助手,名为 AutoAgent Executor。
你具备强大的任务执行能力和丰富的工具使用经验。
# 核心职责
作为智能任务执行者,你需要:
1. 精确理解和执行规划好的任务步骤
2. 智能调用相应的MCP工具完成具体任务
3. 处理执行过程中的异常和错误
4. 提供详细的执行报告和结果反馈
# 专业技能
## 任务执行能力
- 深度理解任务步骤的具体要求和目标
- 智能选择和调用合适的MCP工具
- 处理工具调用的参数配置和结果解析
- 监控执行进度并提供实时反馈
## 错误处理机制
- 识别和分类执行过程中的各种错误
- 实施智能重试和降级策略
- 提供详细的错误诊断和解决建议
- 确保任务执行的稳定性和可靠性
## 标准化输出
严格按照以下结构化格式输出执行报告:
**📋 任务执行报告**
- 任务名称:[步骤名称]
- 执行状态:[成功/失败/部分成功]
- 开始时间:[时间戳]
- 结束时间:[时间戳]
- 执行耗时:[毫秒]
**🔧 工具调用详情**
- 使用工具:[工具名称列表]
- 调用次数:[具体次数]
- 成功率:[百分比]
- 关键参数:[重要参数配置]
**📊 执行结果**
- 主要成果:[具体完成的内容]
- 数据输出:[生成的数据或文件]
- 质量评估:[结果质量分析]
**⚠️ 异常处理**
- 遇到问题:[具体问题描述]
- 处理策略:[采用的解决方案]
- 影响评估:[对整体任务的影响]
今天是 {current_date}。
""")
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(20)
.build()
).build(),
new RagAnswerAdvisor(vectorStore, SearchRequest.builder()
.topK(5)
.filterExpression("knowledge == 'article'")
.build()))
.build();
// 初始化MCP工具客户端
mcpToolsChatClient = ChatClient.builder(chatModel)
.defaultSystem("""
# 角色定义
你是一个专业的MCP(Model Context Protocol)工具管理专家,名为 MCP Tools Manager。
你具备深度的MCP协议理解和丰富的工具集成经验。
# 核心职责
作为MCP工具生态的管理者,你需要:
1. 精确识别和分类所有可用的MCP服务工具
2. 深度分析工具的功能边界、参数规范和使用场景
3. 基于用户意图智能匹配最优工具组合
4. 提供符合MCP标准的工具调用指导
# 专业技能
## 工具发现与分析
- 实时扫描并索引所有注册的MCP服务端点
- 解析工具的JSON Schema定义和元数据
- 识别工具间的依赖关系和协作模式
- 评估工具的可靠性、性能和安全性
## 智能推荐引擎
- 基于语义理解匹配用户需求与工具能力
- 考虑工具的执行成本、响应时间和成功率
- 提供备选方案和降级策略
- 优化工具调用链的执行顺序
## 标准化输出
严格按照以下结构化格式输出:
**🔧 可用MCP工具清单**
```
序号 | 工具名称 | 服务类型 | 核心功能 | 参数要求 | 可靠性评级
-----|---------|---------|---------|---------|----------
1 | [name] | [type] | [desc] | [params]| [rating]
```
**🎯 智能推荐方案**
- 主推工具:[工具名] - 匹配度:[百分比] - 理由:[具体原因]
- 备选工具:[工具名] - 适用场景:[具体场景]
- 组合策略:[多工具协作方案]
**📋 执行标准指南**
- 调用顺序:[步骤1] → [步骤2] → [步骤3]
- 参数配置:[关键参数及其推荐值]
- 错误处理:[异常情况的处理策略]
- 性能优化:[提升执行效率的建议]
**⚠️ 注意事项**
- 安全约束:[权限要求和安全限制]
- 资源消耗:[预期的计算和网络开销]
- 兼容性:[版本要求和环境依赖]
""")
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(30)
.build()
).build())
.build();
}
}首先,我们需要初始化三个客户端:
- planningChatClient:负责将任务拆解为可执行步骤;
- mcpToolsChatClient:用于准确识别并获取所需的 MCP 工具;
- executorChatClient:根据规划流程执行具体操作。
在编写话术时,可以先明确自己想要实现的目标,再使用 AI 进行优化。通过多次尝试和迭代,可以有效提升内容的准确性与表达质量。
3. 规划分析
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class FlowAgentTest {
@Test
public void test_agent() {
String userRequest = """
我需要你帮我生成一篇文章,要求如下;
1. 场景为互联网大厂java求职者面试
2. 提问的技术栈如下;
核心语言与平台: Java SE (8/11/17), Jakarta EE (Java EE), JVM
构建工具: Maven, Gradle, Ant
Web框架: Spring Boot, Spring MVC, Spring WebFlux, Jakarta EE, Micronaut, Quarkus, Play Framework, Struts (Legacy)
数据库与ORM: Hibernate, MyBatis, JPA, Spring Data JDBC, HikariCP, C3P0, Flyway, Liquibase
测试框架: JUnit 5, TestNG, Mockito, PowerMock, AssertJ, Selenium, Cucumber
微服务与云原生: Spring Cloud, Netflix OSS (Eureka, Zuul), Consul, gRPC, Apache Thrift, Kubernetes Client, OpenFeign, Resilience4j
安全框架: Spring Security, Apache Shiro, JWT, OAuth2, Keycloak, Bouncy Castle
消息队列: Kafka, RabbitMQ, ActiveMQ, JMS, Apache Pulsar, Redis Pub/Sub
缓存技术: Redis, Ehcache, Caffeine, Hazelcast, Memcached, Spring Cache
日志框架: Log4j2, Logback, SLF4J, Tinylog
监控与运维: Prometheus, Grafana, Micrometer, ELK Stack, New Relic, Jaeger, Zipkin
模板引擎: Thymeleaf, FreeMarker, Velocity, JSP/JSTL
REST与API工具: Swagger/OpenAPI, Spring HATEOAS, Jersey, RESTEasy, Retrofit
序列化: Jackson, Gson, Protobuf, Avro
CI/CD工具: Jenkins, GitLab CI, GitHub Actions, Docker, Kubernetes
大数据处理: Hadoop, Spark, Flink, Cassandra, Elasticsearch
版本控制: Git, SVN
工具库: Apache Commons, Guava, Lombok, MapStruct, JSch, POI
AI:Spring AI, Google A2A, MCP(模型上下文协议), RAG(检索增强生成), Agent(智能代理), 聊天会话内存, 工具执行框架, 提示填充, 向量化, 语义检索, 向量数据库(Milvus/Chroma/Redis), Embedding模型(OpenAI/Ollama), 客户端-服务器架构, 工具调用标准化, 扩展能力, Agentic RAG, 文档加载, 企业文档问答, 复杂工作流, 智能客服系统, AI幻觉(Hallucination), 自然语言语义搜索
其他: JUnit Pioneer, Dubbo, R2DBC, WebSocket
3. 提问的场景方案可包括但不限于;音视频场景,内容社区与UGC,AIGC,游戏与虚拟互动,电商场景,本地生活服务,共享经济,支付与金融服务,互联网医疗,健康管理,医疗供应链,企业协同与SaaS,产业互联网,大数据与AI服务,在线教育,求职招聘,智慧物流,供应链金融,智慧城市,公共服务数字化,物联网应用,Web3.0与区块链,安全与风控,广告与营销,能源与环保。
4. 按照故事场景,以严肃的面试官和搞笑的水货程序员谢飞机进行提问,谢飞机对简单问题可以回答出来,回答好了面试官还会夸赞和引导。复杂问题含糊其辞,回答的不清晰。
5. 每次进行3轮提问,每轮可以有3-5个问题。这些问题要有技术业务场景上的衔接性,循序渐进引导提问。最后是面试官让程序员回家等通知类似的话术。
6. 提问后把问题的答案详细的,写到文章最后,讲述出业务场景和技术点,让小白可以学习下来。
根据以上内容,不要阐述其他信息,请直接提供;文章标题(需要含带技术点)、文章内容、文章标签(多个用英文逗号隔开)、文章简述(100字)
将以上内容发布文章到CSDN
之后进行,微信公众号消息通知,平台:CSDN、主题:为文章标题、描述:为文章简述、跳转地址:为发布文章到CSDN获取 http url 文章地址
""";
log.info("=== 自动Agent开始执行 ===");
log.info("用户请求: {}", userRequest);
Map<String, Object> executionContext = new HashMap<>();
executionContext.put("userRequest", userRequest);
executionContext.put("startTime", System.currentTimeMillis());
executionContext.put("status", "INITIALIZING");
try {
// 第一步:获取可用的MCP工具和使用方式(仅分析,不执行用户请求)
log.info("\n--- 步骤1: MCP工具能力分析(仅分析阶段,不执行用户请求) ---");
executionContext.put("status", "ANALYZING_TOOLS");
String mcpToolsAnalysis = executeWithRetry(() -> getMcpToolsCapabilities(userRequest), "MCP工具分析", 3);
log.info("MCP工具分析结果(仅分析,未执行实际操作): {}", mcpToolsAnalysis);
executionContext.put("mcpToolsAnalysis", mcpToolsAnalysis);
// 第二步:根据用户请求和MCP能力规划执行步骤
log.info("\n--- 步骤2: 规划执行步骤 ---");
executionContext.put("status", "PLANNING");
String planningResult = executeWithRetry(() -> planExecutionSteps(userRequest, mcpToolsAnalysis), "执行步骤规划", 3);
log.info("规划结果: {}", planningResult);
executionContext.put("planningResult", planningResult);
// 第三步:解析规划结果,将每个步骤存储到map中
log.info("\n--- 步骤3: 解析规划步骤 ---");
executionContext.put("status", "PARSING_STEPS");
Map<String, String> stepsMap = parseExecutionSteps(planningResult);
log.info("解析的步骤数量: {}", stepsMap.size());
for (Map.Entry<String, String> entry : stepsMap.entrySet()) {
log.info("步骤 {}: {}", entry.getKey(), entry.getValue().substring(0, Math.min(100, entry.getValue().length())) + "...");
}
executionContext.put("stepsMap", stepsMap);
// 第四步:按顺序执行规划步骤
log.info("\n--- 步骤4: 按顺序执行规划步骤 ---");
executionContext.put("status", "EXECUTING_STEPS");
executeStepsInOrder(stepsMap, executionContext);
// 执行完成
log.info("\n=== Agent执行完成 ===");
executionContext.put("status", "COMPLETED");
executionContext.put("endTime", System.currentTimeMillis());
long totalTime = (Long) executionContext.get("endTime") - (Long) executionContext.get("startTime");
log.info("总执行时间: {} ms", totalTime);
} catch (Exception e) {
log.error("Agent执行过程中发生错误", e);
executionContext.put("status", "ERROR");
executionContext.put("error", e.getMessage());
executionContext.put("endTime", System.currentTimeMillis());
}
}
}根据用户的提问,整个流程可分为四个步骤:
获取可用的 MCP 工具及其使用方式
仅进行分析,不直接执行用户请求。
规划执行步骤
- 根据用户的请求内容与 MCP 工具的能力,制定具体的执行方案。
解析规划结果
- 将规划生成的每个步骤解析并存储到
map中,以便后续按序执行。
- 将规划生成的每个步骤解析并存储到
顺序执行步骤
- 按照
map中定义的顺序依次执行所有规划步骤。
- 按照
💡提示:具体的工程实现代码可参考课程示例代码进行学习与实践。
赞助