
SambaNova AI API 逆向实战:免费调用 DeepSeek-V3 等顶级开源模型
原创2025年10月16日...大约 10 分钟
前言:SambaNova Cloud 免费资源介绍
SambaNova Cloud 是一个提供免费 AI 模型调用服务的平台,主要特点:
- 新用户福利:注册即送 $5 免费额度
- 官方 API:平台自带标准 API 接口
- 关键发现:Playground 使用不计费,仅统计 API 调用量
支持的开源模型列表
该平台提供多个顶级开源大模型:
| 模型系列 | 具体型号 | 上下文长度 |
|---|---|---|
| DeepSeek | R1-0528, R1-Distill-Llama-70B, V3-0324, V3.1, V3.1-Terminus | 131K |
| Llama | 3.1-8B, 3.3-70B, 3.3-Swallow-70B-v0.4, 4-Maverick-17B-128E | 16K-131K |
| 其他 | Qwen3-32B, E5-Mistral-7B, Whisper-Large-v3, gpt-oss-120b | 4K-131K |
💡 核心思路:由于 Playground 不计费,我们可以逆向其接口,实现免费无限制调用。
第一步:接口分析与流量抓包
1.1 打开浏览器开发者工具
- 访问 SambaNova Playground
- 按
F12打开开发者工具 - 切换到 Network 标签页
- 在 Playground 中发送一条测试消息
1.2 定位关键请求
在网络请求列表中找到 /api/completion 请求:
请求 URL:
https://cloud.sambanova.ai/api/completion请求方法: POST
关键请求头:
Content-Type: application/jsonAccept: text/event-stream(流式响应)Cookie: access_token=<你的令牌>
第二步:提取 Access Token
2.1 从 Cookie 中获取令牌
在开发者工具的 Application → Cookies 中找到 access_token:
# 示例令牌格式 (已脱敏)
access_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiJ1c2VyQGV4YW1wbGUuY29tIiwiZXhwIjoxNzYxMDM2MjQ4fQ.xxxxxxxxxxxxxxxxxxxxx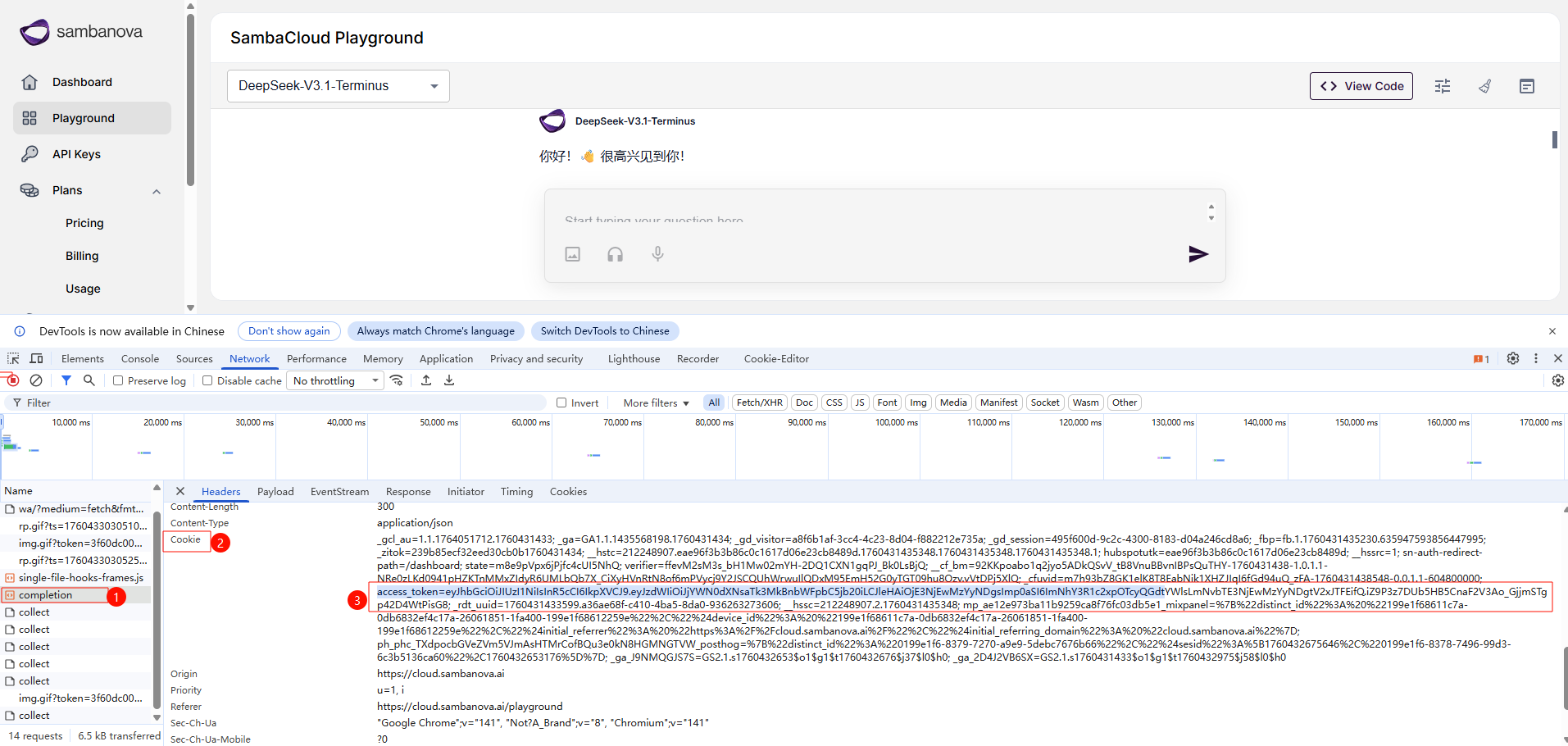
令牌有效期说明:
- JWT 令牌通常有效期为 7天
- 过期后需重新登录获取新令牌
- 建议定期刷新以保证服务稳定性
第三步:分析请求体结构
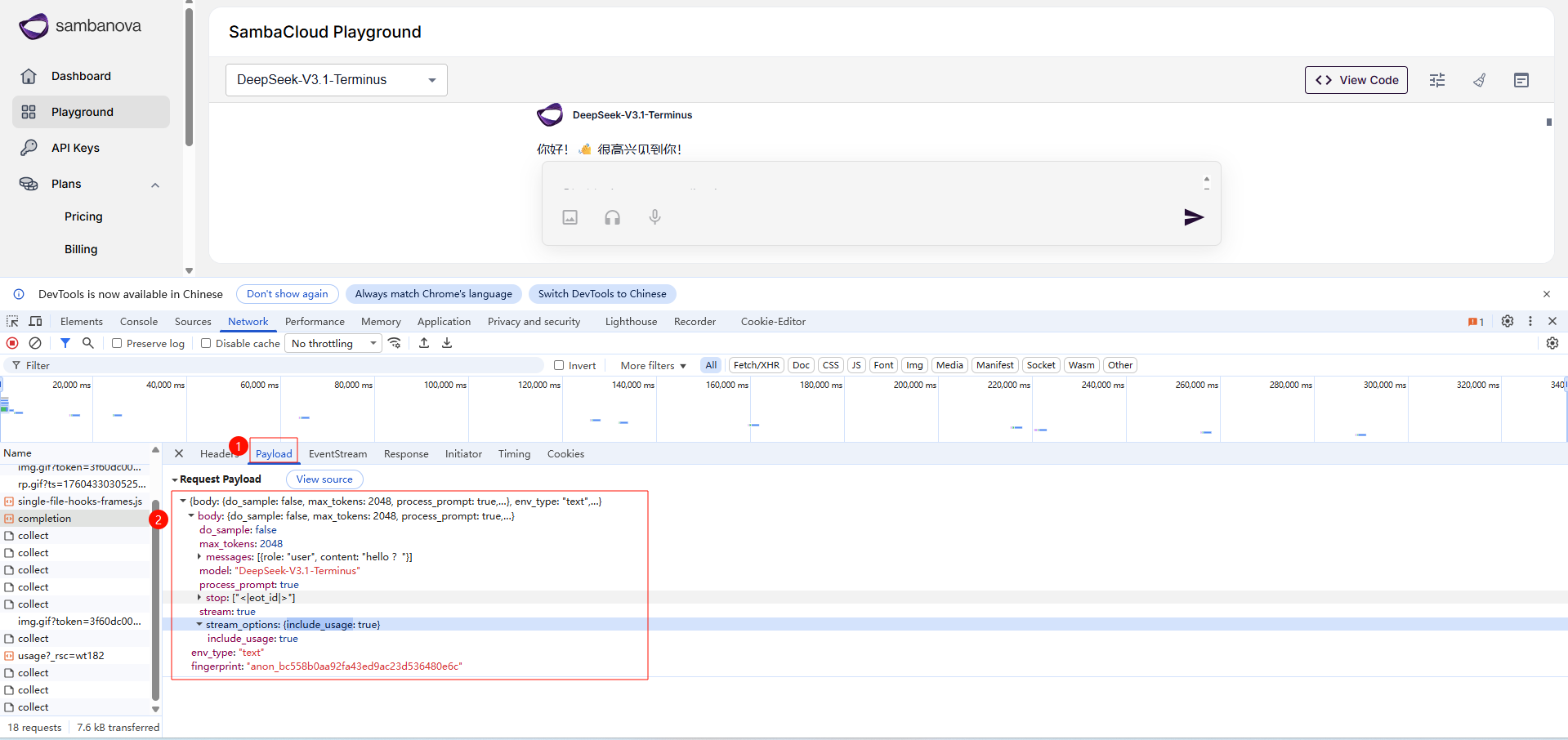
3.1 原始请求体格式
复制请求负载 (Request Payload) 并格式化:
{
"body": {
"do_sample": false,
"max_tokens": 2048,
"process_prompt": true,
"messages": [
{
"role": "user",
"content": "hello ?"
}
],
"stop": ["<|eot_id|>"],
"stream": true,
"stream_options": {
"include_usage": true
},
"model": "DeepSeek-V3.1-Terminus"
},
"env_type": "text",
"fingerprint": "anon_bc558b0aa92fa43ed9ac23d536480e6c"
}
关键参数说明
| 参数 | 说明 | 建议值 |
|---|---|---|
do_sample | 是否启用采样 (temperature > 0 时为 true) | false |
max_tokens | 最大生成 Token 数 | 2048-7168 |
stream | 是否流式输出 | true |
stop | 停止词列表 | `["< |
fingerprint | 匿名用户标识 | 固定值即可 |
第四步:cURL 请求测试
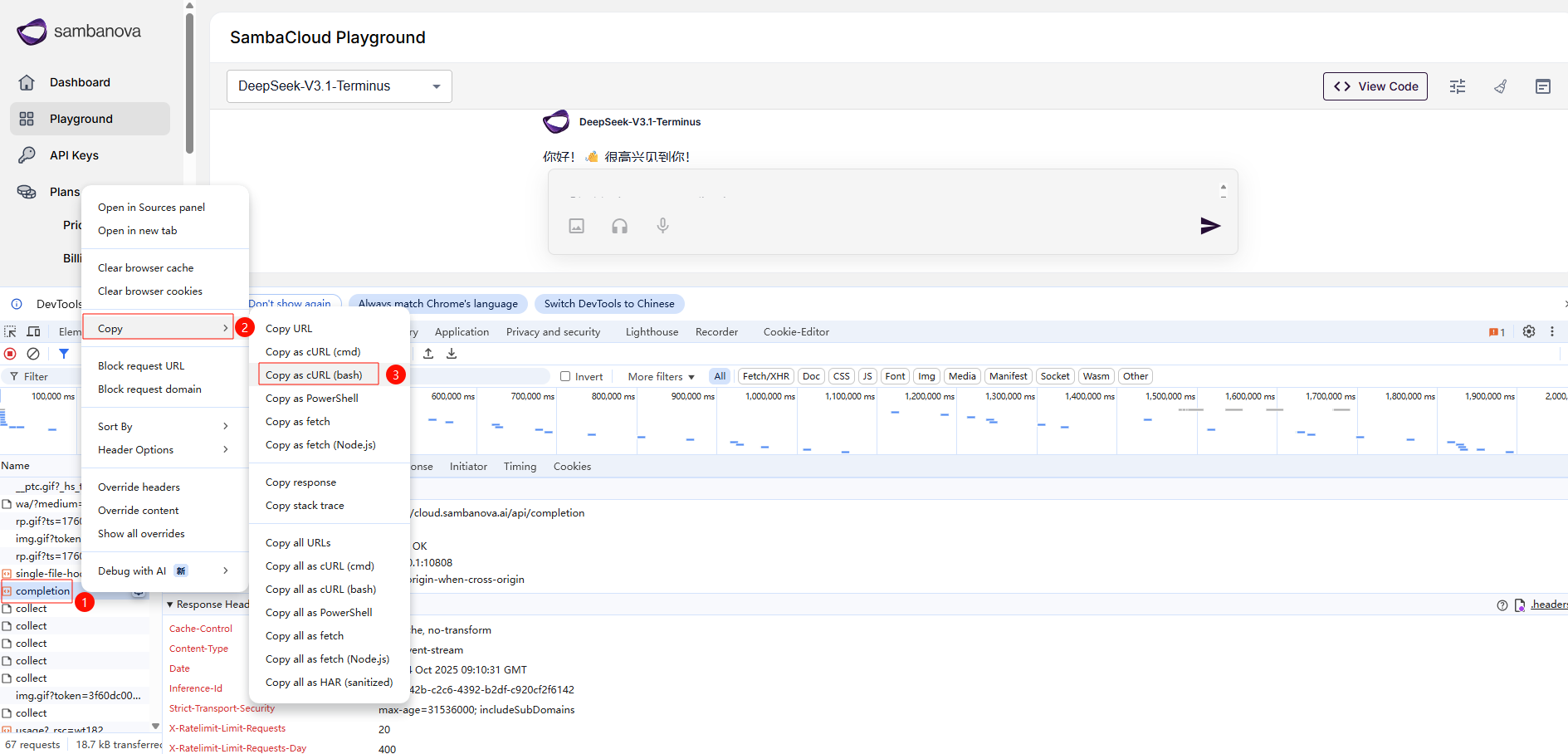
4.1 导出 cURL 命令
在开发者工具中右键点击请求 → Copy → Copy as cURL (bash)
4.2 简化后的测试命令
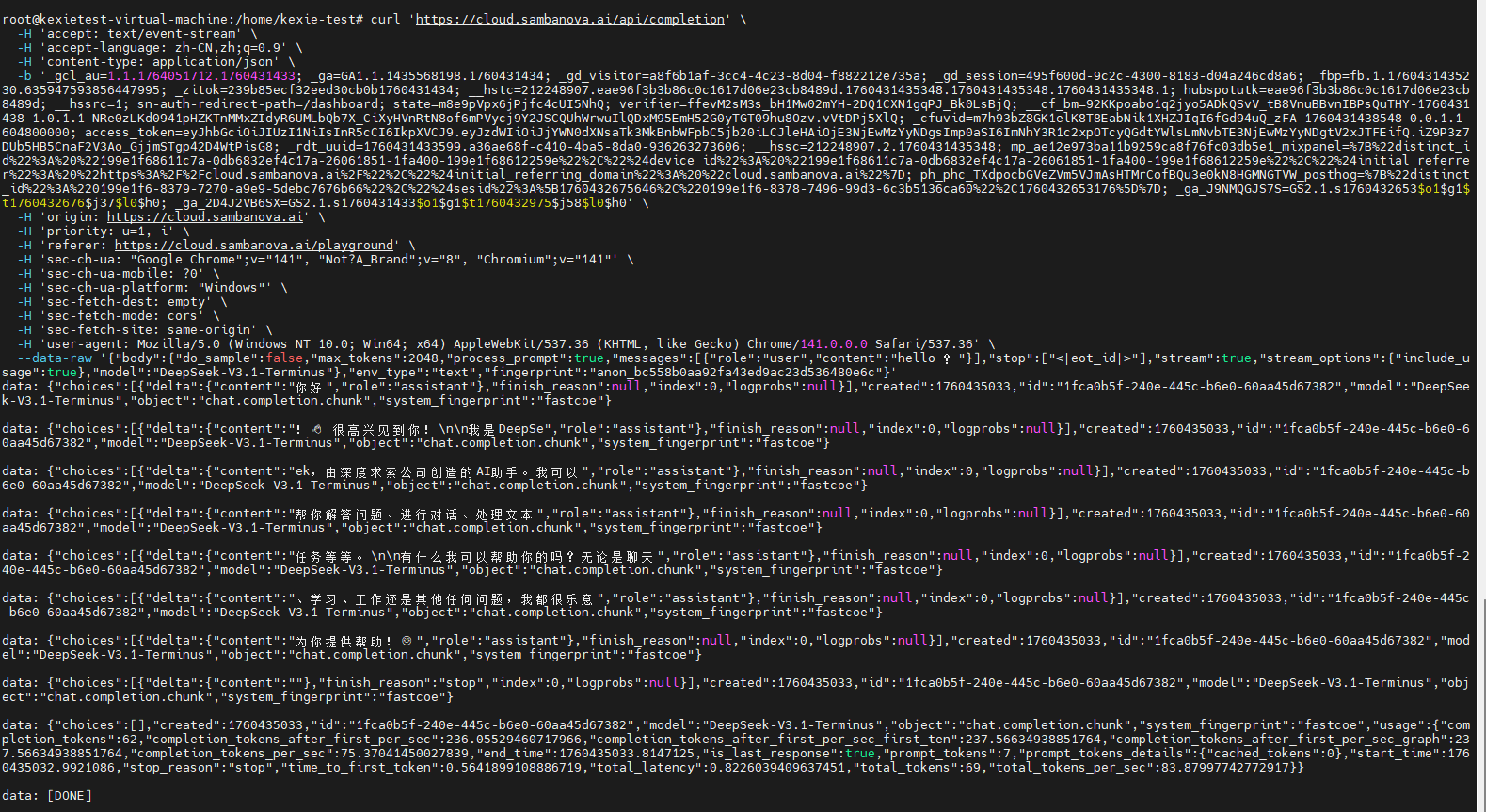
curl 'https://cloud.sambanova.ai/api/completion' \
-H 'accept: text/event-stream' \
-H 'content-type: application/json' \
-H 'cookie: access_token=<你的令牌>' \
--data-raw '{
"body": {
"do_sample": false,
"max_tokens": 2048,
"process_prompt": true,
"messages": [{"role": "user", "content": "你好"}],
"stop": ["<|eot_id|>"],
"stream": true,
"stream_options": {"include_usage": true},
"model": "DeepSeek-V3.1-Terminus"
},
"env_type": "text",
"fingerprint": "anon_bc558b0aa92fa43ed9ac23d536480e6c"
}'
第五步:FastAPI 封装实现
5.1 设计目标
将 SambaNova 接口封装成 OpenAI 兼容格式,方便集成到现有项目:
- 端点:
/v1/chat/completions - 认证:
Authorization: Bearer <access_token> - 请求/响应格式:完全兼容 OpenAI API
5.2 项目结构
sambanova-proxy/
├── main.py # FastAPI 主程序
├── requirements.txt # 依赖列表
└── README.md # 使用说明5.3 依赖安装
# requirements.txt
fastapi==0.115.0
uvicorn==0.32.0
requests==2.32.3
pydantic==2.9.2安装命令:
pip install -r requirements.txt第六步:完整服务端代码
6.1 核心实现 (main.py)
from fastapi import FastAPI, HTTPException, Request, Header
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing import List, Optional, Dict, Any, Union
import requests
import json
import uuid
import time
from datetime import datetime
import urllib3
import logging
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
app = FastAPI(title="SambaNova to OpenAI API by:HeYo", version="1.0.0")
# 添加CORS中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class Message(BaseModel):
role: str
content: str
class ChatCompletionRequest(BaseModel):
model: str = "DeepSeek-V3.1-Terminus"
messages: List[Message]
max_tokens: Optional[int] = 2048
temperature: Optional[float] = 0.7
top_p: Optional[float] = 1.0
stream: Optional[bool] = False
stop: Optional[Union[str, List[str]]] = None
class Choice(BaseModel):
index: int
message: Optional[Message] = None
delta: Optional[Dict[str, Any]] = None
finish_reason: Optional[str] = None
class Usage(BaseModel):
prompt_tokens: int
completion_tokens: int
total_tokens: int
class ChatCompletionResponse(BaseModel):
id: str
object: str = "chat.completion"
created: int
model: str
choices: List[Choice]
usage: Optional[Usage] = None
# 请求日志中间件
@app.middleware("http")
async def log_requests(request: Request, call_next):
logger.info(f"\n{'=' * 60}")
logger.info(f"收到请求: {request.method} {request.url}")
logger.info(f"Headers: {dict(request.headers)}")
logger.info(f"Content-Type: {request.headers.get('content-type', 'NOT SET')}")
# 读取并记录请求体
if request.method == "POST":
body = await request.body()
body_str = body.decode('utf-8') if body else 'EMPTY'
logger.info(f"Request Body: {body_str}")
response = await call_next(request)
logger.info(f"响应状态码: {response.status_code}")
logger.info(f"{'=' * 60}\n")
return response
def create_sambanova_payload(request: ChatCompletionRequest):
stop_tokens = ["<|eot_id|>"]
if request.stop:
if isinstance(request.stop, str):
stop_tokens.append(request.stop)
else:
stop_tokens.extend(request.stop)
return {
"body": {
"do_sample": request.temperature > 0,
"max_tokens": request.max_tokens,
"process_prompt": True,
"messages": [{"role": msg.role, "content": msg.content} for msg in request.messages],
"stop": stop_tokens,
"stream": request.stream,
"stream_options": {
"include_usage": True
} if request.stream else {},
"model": request.model
},
"env_type": "text",
"fingerprint": "anon_bc558b0aa92fa43ed9ac23d536480e6c"
}
def get_sambanova_headers(API_KEY):
return {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36",
'Accept': "text/event-stream",
'Accept-Encoding': "gzip, deflate, br, zstd",
'Content-Type': "application/json",
'sec-ch-ua-platform': "\"Windows\"",
'sec-ch-ua': "\"Google Chrome\";v=\"141\", \"Not?A_Brand\";v=\"8\", \"Chromium\";v=\"141\"",
'sec-ch-ua-mobile': "?0",
'origin': "https://cloud.sambanova.ai",
'sec-fetch-site': "same-origin",
'sec-fetch-mode': "cors",
'sec-fetch-dest': "empty",
'referer': "https://cloud.sambanova.ai/playground",
'accept-language': "zh-CN,zh;q=0.9",
'priority': "u=1, i",
'Cookie': f"access_token={API_KEY}"
}
async def stream_response(request: ChatCompletionRequest, API_KEY: str):
url = "https://cloud.sambanova.ai/api/completion"
payload = create_sambanova_payload(request)
headers = get_sambanova_headers(API_KEY)
try:
response = requests.post(
url,
data=json.dumps(payload),
headers=headers,
verify=False,
proxies={'http': None, 'https': None},
stream=True
)
response.raise_for_status()
completion_id = f"chatcmpl-{uuid.uuid4().hex}"
created = int(time.time())
initial_chunk = {
"id": completion_id,
"object": "chat.completion.chunk",
"created": created,
"model": request.model,
"choices": [{
"index": 0,
"delta": {"role": "assistant", "content": ""},
"finish_reason": None
}]
}
yield f"data: {json.dumps(initial_chunk)}\n\n"
# 转发流式响应
for line in response.iter_lines():
if line:
line_str = line.decode('utf-8')
yield f"{line_str}\n"
except Exception as e:
logger.error(f"流式响应错误: {str(e)}")
error_chunk = {
"id": f"chatcmpl-{uuid.uuid4().hex}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": request.model,
"choices": [{
"index": 0,
"delta": {},
"finish_reason": "error"
}],
"error": str(e)
}
yield f"data: {json.dumps(error_chunk)}\n\n"
yield "data: [DONE]\n\n"
async def non_stream_response(request: ChatCompletionRequest, API_KEY: str):
url = "https://cloud.sambanova.ai/api/completion"
payload = create_sambanova_payload(request)
payload["body"]["stream"] = False
headers = get_sambanova_headers(API_KEY)
try:
logger.info(f"发送请求到 SambaNova: {url}")
response = requests.post(
url,
data=json.dumps(payload),
headers=headers,
verify=False,
proxies={'http': None, 'https': None}
)
response.raise_for_status()
sambanova_response = response.json()
logger.info(f"SambaNova 响应: {json.dumps(sambanova_response, ensure_ascii=False)[:500]}")
# 提取响应内容
content = ""
if 'completion' in sambanova_response:
content = sambanova_response['completion']
elif 'choices' in sambanova_response and sambanova_response['choices']:
content = sambanova_response['choices'][0].get('message', {}).get('content', '')
# 构建响应
completion_response = ChatCompletionResponse(
id=f"chatcmpl-{uuid.uuid4().hex}",
created=int(time.time()),
model=request.model,
choices=[
Choice(
index=0,
message=Message(role="assistant", content=content),
finish_reason="stop"
)
],
usage=Usage(
prompt_tokens=len(' '.join([msg.content for msg in request.messages])) // 4,
completion_tokens=len(content) // 4,
total_tokens=(len(' '.join([msg.content for msg in request.messages])) + len(content)) // 4
)
)
return completion_response
except Exception as e:
logger.error(f"非流式响应错误: {str(e)}")
raise HTTPException(status_code=500, detail=f"SambaNova API error: {str(e)}")
@app.get("/")
async def hi():
return {"message": "SambaNova to OpenAI API by:Heyo", "status": "running"}
@app.post("/v1/chat/completions")
async def chat_completions(
raw_request: Request,
authorization: str = Header(None, alias="Authorization")
):
"""
聊天补全端点 - 兼容 OpenAI API 格式
"""
# 验证授权
if not authorization or not authorization.startswith("Bearer "):
logger.warning("授权失败: 缺少或无效的 Authorization header")
raise HTTPException(status_code=401, detail="KEY_ERROR: Missing or invalid Authorization header")
API_KEY = authorization[7:]
logger.info(f"API Key 提取成功: {API_KEY[:10]}...")
# 读取并解析请求体
try:
body = await raw_request.body()
if not body:
logger.error("请求体为空")
raise HTTPException(status_code=400, detail="Request body is empty")
body_json = json.loads(body.decode('utf-8'))
logger.info(f"解析请求体成功: {json.dumps(body_json, ensure_ascii=False)[:300]}")
# 验证并创建请求对象
chat_request = ChatCompletionRequest(**body_json)
logger.info(f"创建 ChatCompletionRequest 成功 - Model: {chat_request.model}, Stream: {chat_request.stream}")
except json.JSONDecodeError as e:
logger.error(f"JSON 解析错误: {str(e)}")
raise HTTPException(status_code=400, detail=f"Invalid JSON: {str(e)}")
except Exception as e:
logger.error(f"请求验证错误: {str(e)}")
raise HTTPException(status_code=422, detail=f"Request validation error: {str(e)}")
# 处理流式或非流式响应
try:
if chat_request.stream:
logger.info("返回流式响应")
return StreamingResponse(
stream_response(chat_request, API_KEY),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "*",
"Access-Control-Allow-Methods": "*"
}
)
else:
logger.info("返回非流式响应")
return await non_stream_response(chat_request, API_KEY)
except Exception as e:
logger.error(f"处理请求时出错: {str(e)}")
raise HTTPException(status_code=500, detail=f"Internal server error: {str(e)}")
@app.get("/v1/models")
async def list_models():
"""列出可用模型"""
return {
"object": "list",
"data": [
{
"id": "DeepSeek-R1-0528",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 7168
},
{
"id": "DeepSeek-R1-Distill-Llama-70B",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 4096
},
{
"id": "DeepSeek-V3-0324",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 7168
},
{
"id": "DeepSeek-V3.1",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 7168
},
{
"id": "DeepSeek-V3.1-Terminus",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 7168
},
{
"id": "E5-Mistral-7B-Instruct",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 4096,
"max_completion_tokens": 4096
},
{
"id": "Llama-3.3-Swallow-70B-Instruct-v0.4",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 3072
},
{
"id": "Llama-4-Maverick-17B-128E-Instruct",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 4096
},
{
"id": "Meta-Llama-3.1-8B-Instruct",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 16384,
"max_completion_tokens": 4096
},
{
"id": "Meta-Llama-3.3-70B-Instruct",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 3072
},
{
"id": "Qwen3-32B",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 32768,
"max_completion_tokens": 4096
},
{
"id": "Whisper-Large-v3",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 4096,
"max_completion_tokens": 4096
},
{
"id": "gpt-oss-120b",
"object": "model",
"created": int(time.time()),
"owned_by": "sambanova",
"context_length": 131072,
"max_completion_tokens": 131072
}
]
}
@app.get("/health")
async def health_check():
"""健康检查端点"""
return {
"status": "ok",
"timestamp": datetime.now().isoformat(),
"service": "SambaNova to OpenAI API"
}
if __name__ == "__main__":
import uvicorn
logger.info("启动 SambaNova to OpenAI API 服务...")
uvicorn.run(
app,
host="192.168.1.218",
port= 8470,
log_level="info",
# 启用 HTTP/2 支持
http="h11", # 或者 "auto" 让 uvicorn 自动选择
# 或者使用 httptools 可能对 HTTP/2 支持更好
)第七步:部署与测试
7.1 启动服务
# 方式一:直接运行
python main.py
# 方式二:使用 uvicorn (推荐生产环境)
uvicorn main:app --host 0.0.0.0 --port 8470 --reload7.2 非流式请求测试
curl http://localhost:8470/v1/chat/completions \
-H "Authorization: Bearer <你的access_token>" \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-V3.1-Terminus",
"messages": [
{"role": "user", "content": "用 Python 写一个快速排序"}
],
"stream": false
}'7.3 流式请求测试
curl http://localhost:8470/v1/chat/completions \
-H "Authorization: Bearer <你的access_token>" \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-V3.1-Terminus",
"messages": [
{"role": "user", "content": "解释什么是递归"}
],
"stream": true
}'7.4 Python 客户端示例
import openai
# 配置自定义端点
openai.api_base = "http://localhost:8470/v1"
openai.api_key = "你的access_token" # 使用 SambaNova 令牌
response = openai.ChatCompletion.create(
model="DeepSeek-V3.1-Terminus",
messages=[
{"role": "user", "content": "介绍一下 FastAPI 框架"}
],
stream=True
)
for chunk in response:
if 'choices' in chunk and len(chunk.choices) > 0:
delta = chunk.choices[0].delta
if 'content' in delta:
print(delta.content, end='')7.5 在可视化控制台中测试请求
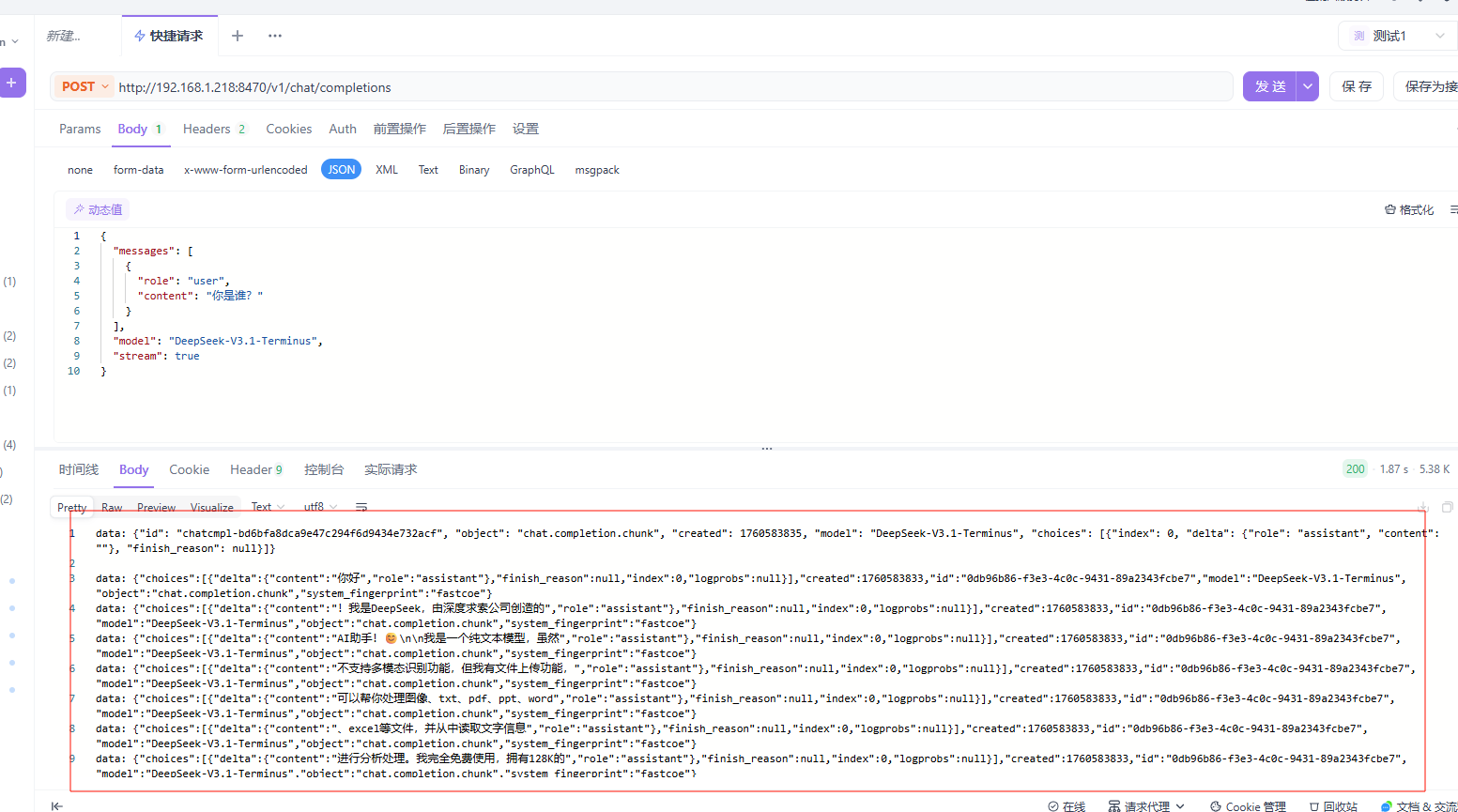
出现如图效果代表成功!
第八步:生产环境优化建议
8.1 安全加固
令牌加密存储
import os from cryptography.fernet import Fernet # 使用环境变量存储加密密钥 KEY = os.getenv("ENCRYPTION_KEY") cipher = Fernet(KEY) def encrypt_token(token: str) -> str: return cipher.encrypt(token.encode()).decode() def decrypt_token(encrypted: str) -> str: return cipher.decrypt(encrypted.encode()).decode()请求限流
from slowapi import Limiter from slowapi.util import get_remote_address limiter = Limiter(key_func=get_remote_address) app.state.limiter = limiter @app.post("/v1/chat/completions") @limiter.limit("60/minute") # 每分钟最多 60 次 async def chat_completions(...): pass
8.2 日志记录
import logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("api.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
@app.post("/v1/chat/completions")
async def chat_completions(...):
logger.info(f"收到请求 - 模型: {request.model}, 消息数: {len(request.messages)}")
# ... 处理逻辑8.3 Docker 容器化部署
Dockerfile:
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
EXPOSE 8470
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8470"]部署命令:
# 构建镜像
docker build -t sambanova-proxy .
# 运行容器
docker run -d \
--name sambanova-api \
-p 8470:8470 \
--restart unless-stopped \
sambanova-proxy总结与注意事项
✅ 实现功能
⚠️ 使用限制
- 令牌有效期:需定期刷新 access_token(约 7 天)
- IP 限制:频繁请求可能触发风控(建议添加延时)
- 模型可用性:部分模型可能因维护暂时不可用
- 仅供学习:本教程仅用于技术研究,请遵守平台服务条款
📚 扩展阅读
常见问题 FAQ
Q: 为什么我的请求返回 401 错误?
A: 检查 access_token 是否过期或格式错误,确保 Cookie 中包含有效令牌。
Q: 流式响应中断怎么办?
A: 可能是网络不稳定或令牌失效,建议添加重试机制和心跳检测。
Q: 如何获取更长的上下文支持?
A: 选择 DeepSeek-V3.1 等模型,上下文长度可达 131K Tokens。
Q: 能否商业使用?
A: 需遵守 SambaNova 平台服务条款,建议仅用于个人学习和测试。
赞助