搭建压测监控平台
本章介绍如何使用Docker 容器来搭建压力测试监控平台。
1. 安装容器及服务
1.1 安装Docker容器
利用脚本进行安装:
curl -sSL https://get.docker.com/ | sh
sudo chmod 777 /var/run/docker.sock关于Docker 相关内容请看 Docker命令记录
1.2 安装配置InfluxDB
1.2.1 启动InfluxDB
docker pull influxdb:latest启动InfluxDB的容器,并将端口 8083 和 8086 映射出来:
docker run -d --name influxdb \
-p 8086:8086 \
-p 8083:8083 \
-v /sg-work/influxDB/influxdb_data:/var/lib/influxdb \
influxdb:latest-d:在后台运行容器。
--name influxdb:为容器指定一个名称。
-p 8086:8086:将主机的 8086 端口映射到容器的 8086 端口。
-v influxdb_data:/var/lib/influxdb:将数据持久化到 Docker 卷中。
创建完成后在浏览器输入:http://192.168.1.20:8086/ 进入访问控制,创建用户、创建组织和桶。
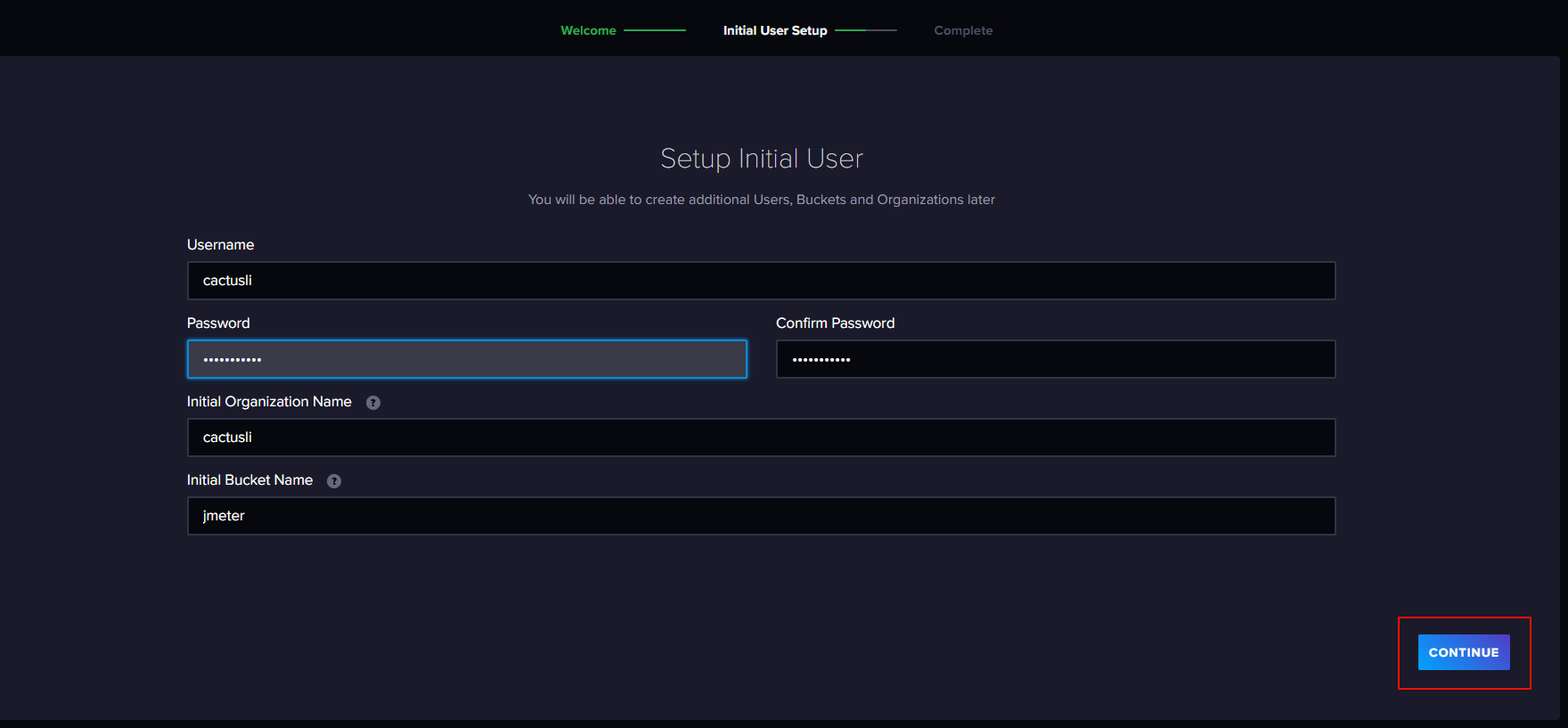
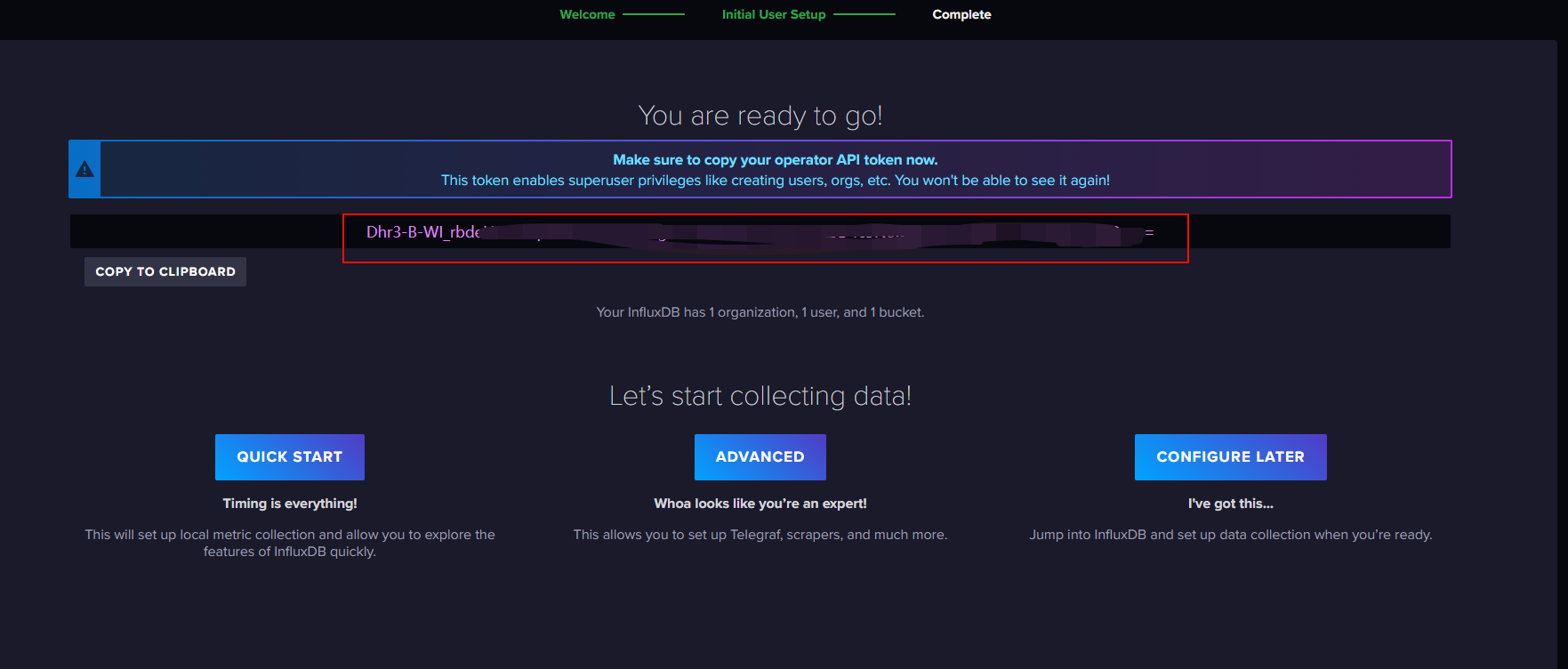
把密钥复制下来进行保存。
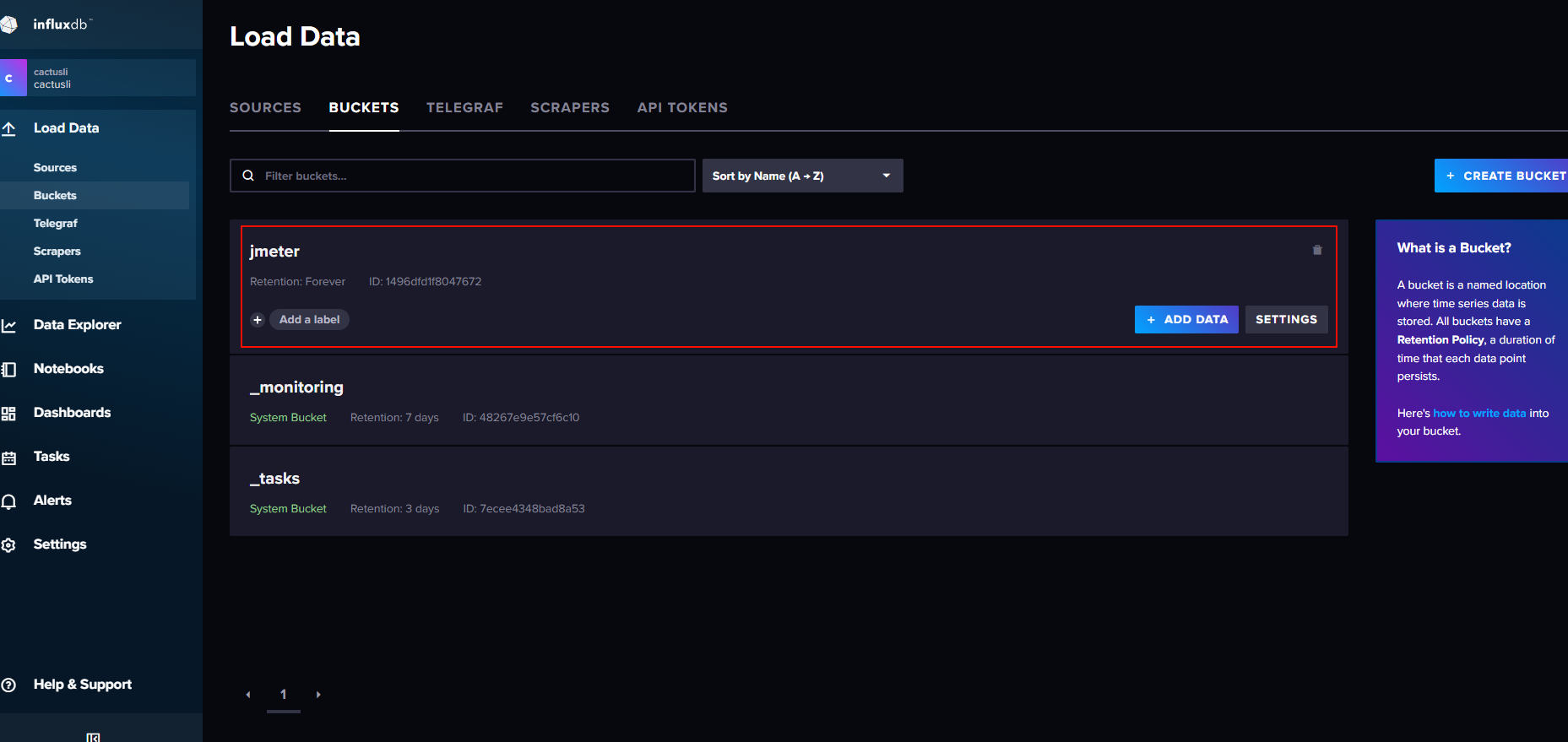
红框标记处就是在初始化用户时创建的桶。
1.2.2 安装 influx-cli 并创建 jmeter 数据库
创建相应目录,下载压缩包,解压包获取二进制运行文件 flux:
mkdir ../influx-cli && cd $_
# amd64
wget https://download.influxdata.com/influxdb/releases/influxdb2-client-2.7.5-linux-amd64.tar.gz
tar -xf influxdb2-client-2.7.5-linux-amd64.tar.gz创建 config 方便操作 InfluxDB,创建 jmeter 数据库。
官方文档:https://docs.influxdata.com/influxdb/v2/reference/cli/influx/config/create/
./influx config create --config-name influx-cli-config \
--host-url http://127.0.0.1:8086 \
--org cactusli \
--token 682j0djW8fYZre1Qv6Oczp1JlXmDqjpzSNXX2NIXRLkQfzksK9F98arSB3HSbTSYdVQhF5lbi0Wnwtj8u6yi4w== \
--active
# bucket-id桶的id 在控制面板中获取
./influx v1 dbrp create \
--bucket-id 1496dfd1f8047672 \
--db jmeter \
--rp jmeter \
--default
# 查询现有数据库
./influx v1 dbrp list
# 根据数据库ID删除数据库
./influx v1 dbrp delete --id 0e08848aa8d8b0001.2.3 配置JMeter脚本后置监听器
配置后置监听器,把 jmeter 性能测试数据写入 influxdb桶中,目前使用的 InfluxDB 2.x 版本,需要配置后端监听器支持 InfluxDB 2.x 的实现。
访问 Github 下载实现支持的 Jar, 然后放入到 /jmeter-xxx/lib/ext 目录下,最后重启 Jmeter,操作步骤如下。
下载地址:jmeter-influxdb2-listener-plugin
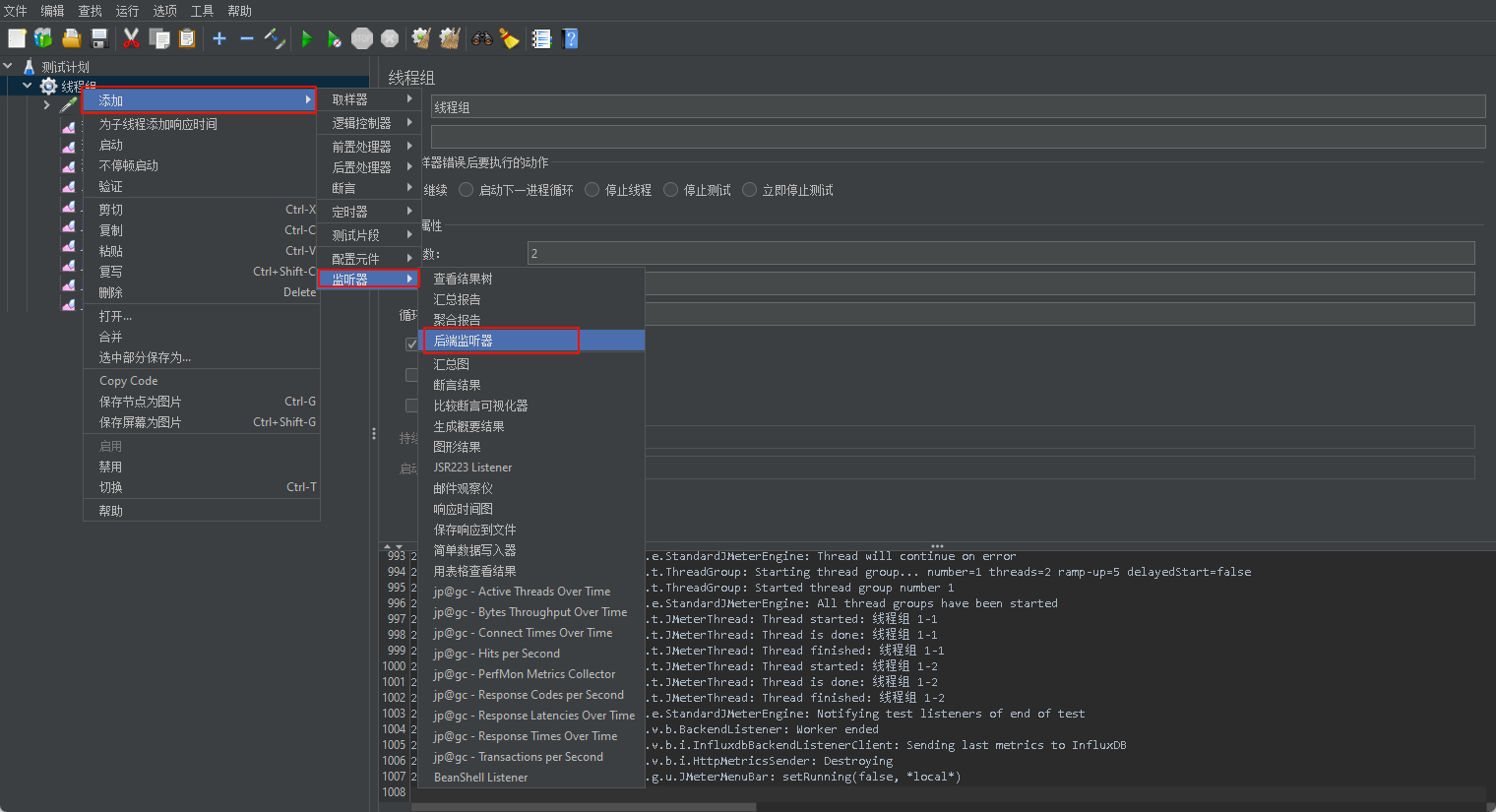
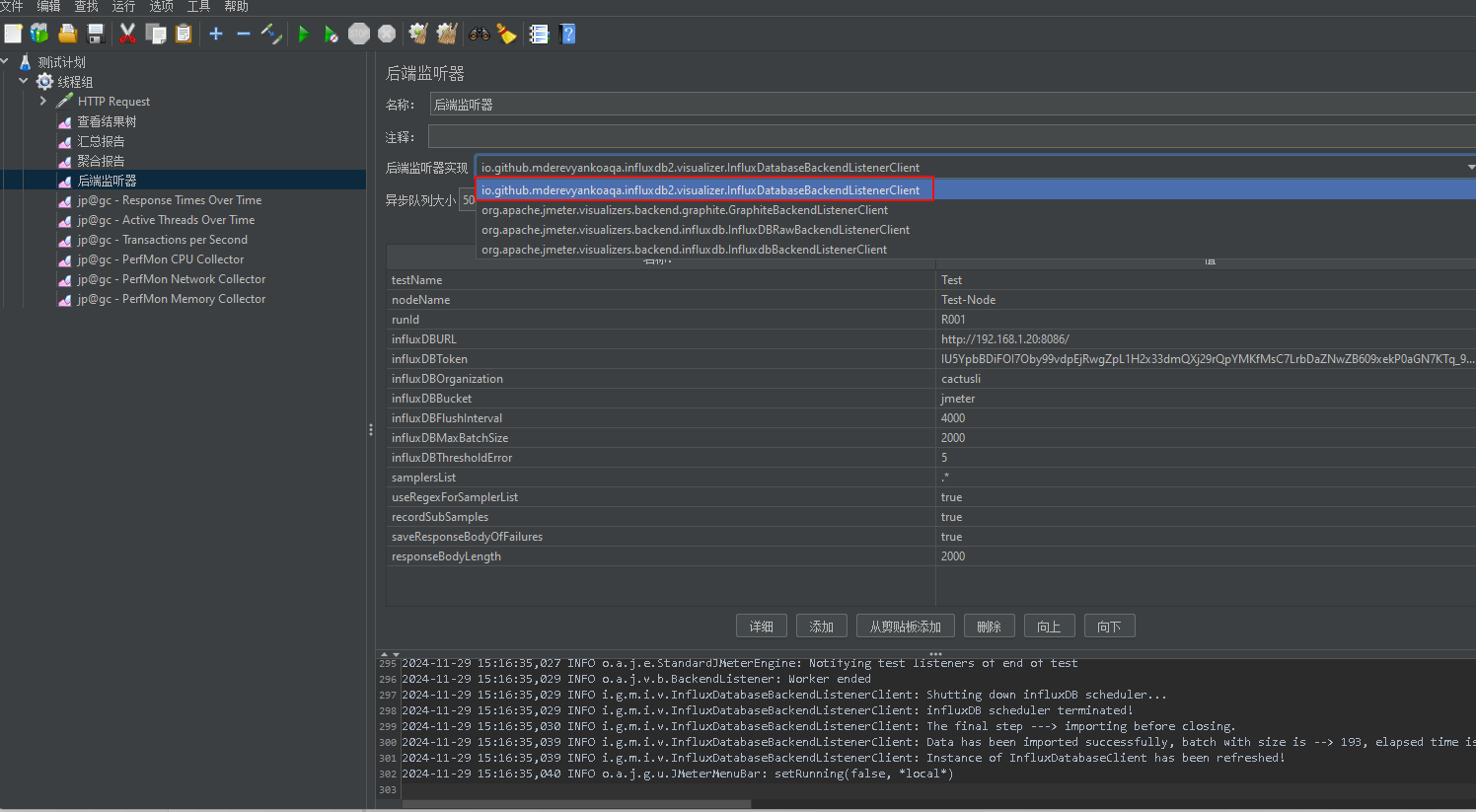
配置参数含义详细见:https://github.com/mderevyankoaqa/jmeter-influxdb2-listener-plugin
1.2.4 运行压测脚本验证
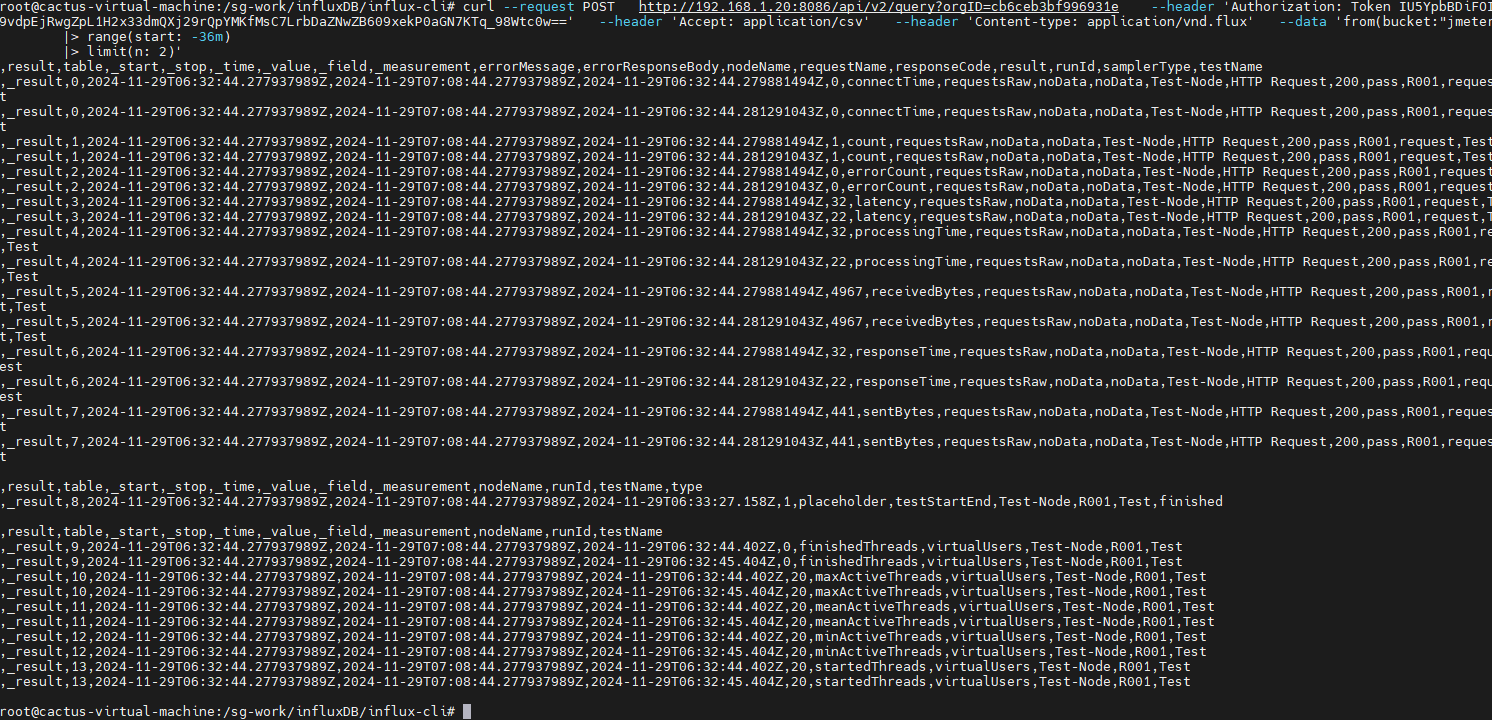
运行 Jmeter 脚本,然后再次在 influxdb 中查看数据,发现类似下面的数据说明输入导入成功:
# orgID是 通过 ./influx v1 dbrp list 命令查询出来的
curl --request POST \
http://192.168.1.20:8086/api/v2/query?orgID=cb6ceb3bf996931e \
--header 'Authorization: Token IU5YpbBDiFOI7Oby99vdpEjRwgZpL1H2x33dmQXj29rQpYMKfMsC7LrbDaZNwZB609xekP0aGN7KTq_98Wtc0w==' \
--header 'Accept: application/csv' \
--header 'Content-type: application/vnd.flux' \
--data 'from(bucket:"jmeter")
|> range(start: -35m)
|> limit(n: 2)'官方文档:https://docs.influxdata.com/influxdb/v2/query-data/execute-queries/influx-api/

可以查看到写入数据库中的最新数据:
删除指定范围的数据:
./influx delete \
--bucket jmeter \
--start 2024-11-28T00:00:00Z \
--stop 2025-11-30T00:00:00Z1.3 安装配Grafana
下载Grafana镜像:
docker pull grafana/grafana启动Grafana容器:
docker run -d --name grafana -p 3000:3000 grafana/grafana浏览器访问: http://192.168.1.20:3000/login
默认账户密码:admin / admin
选择添加数据源:
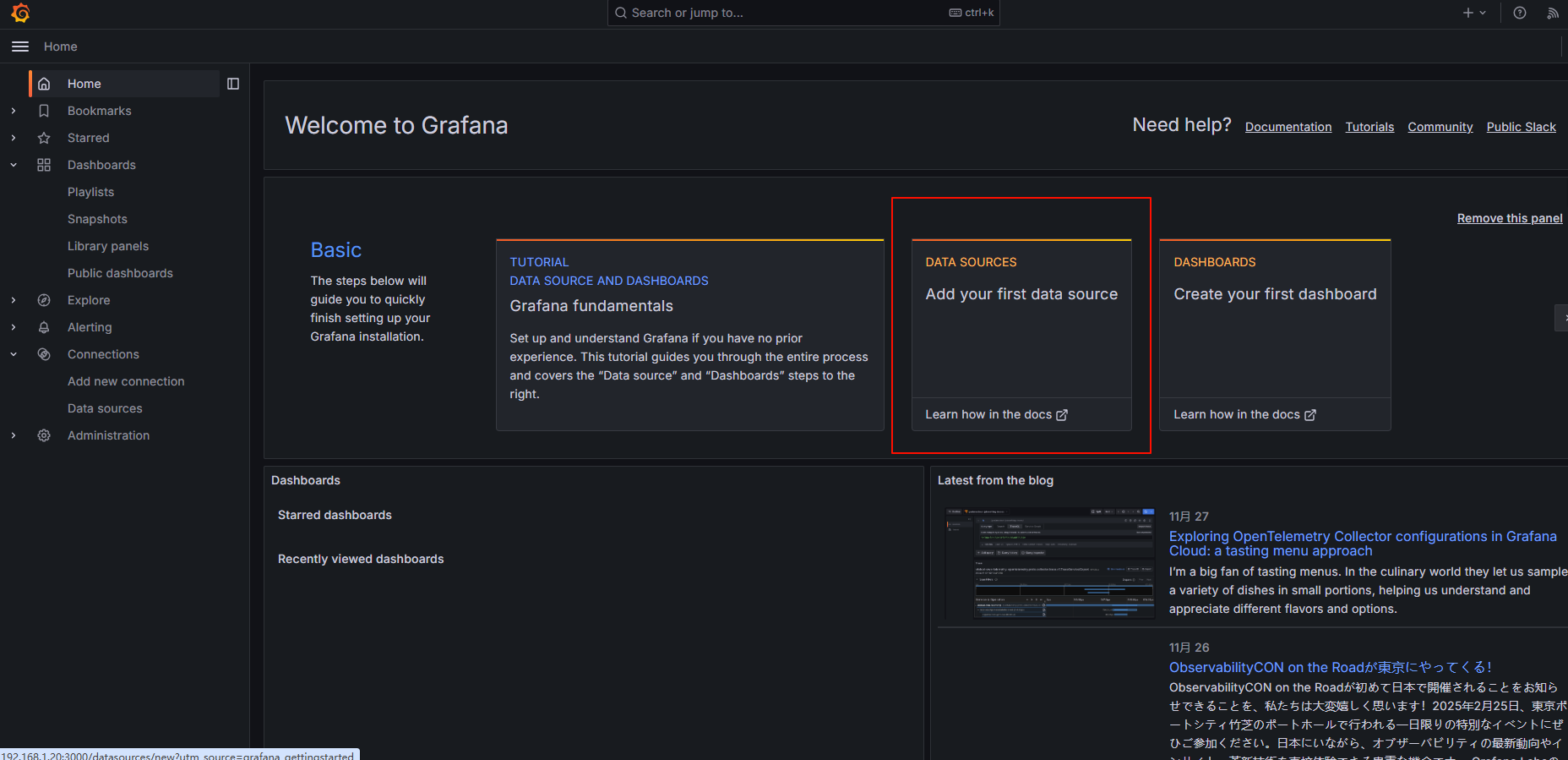
找到并选择 influxdb :
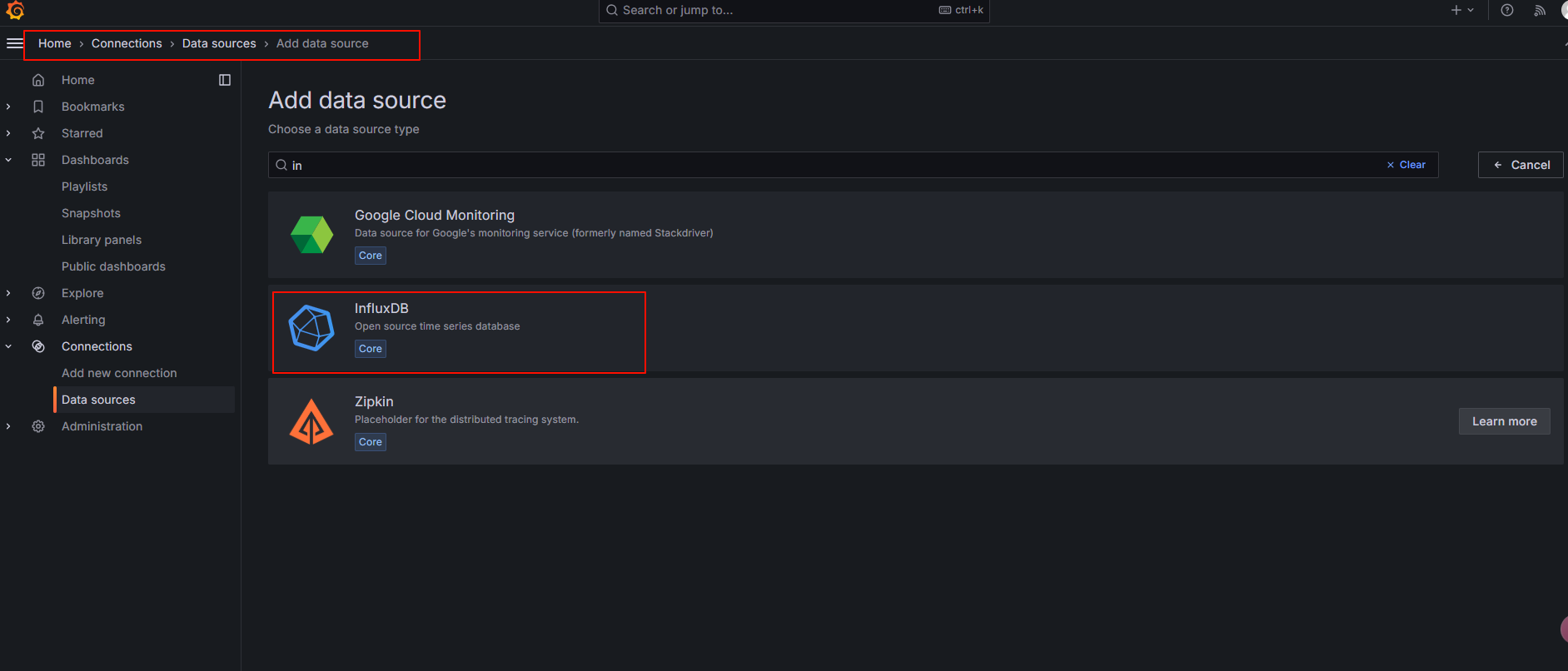
配置数据源:
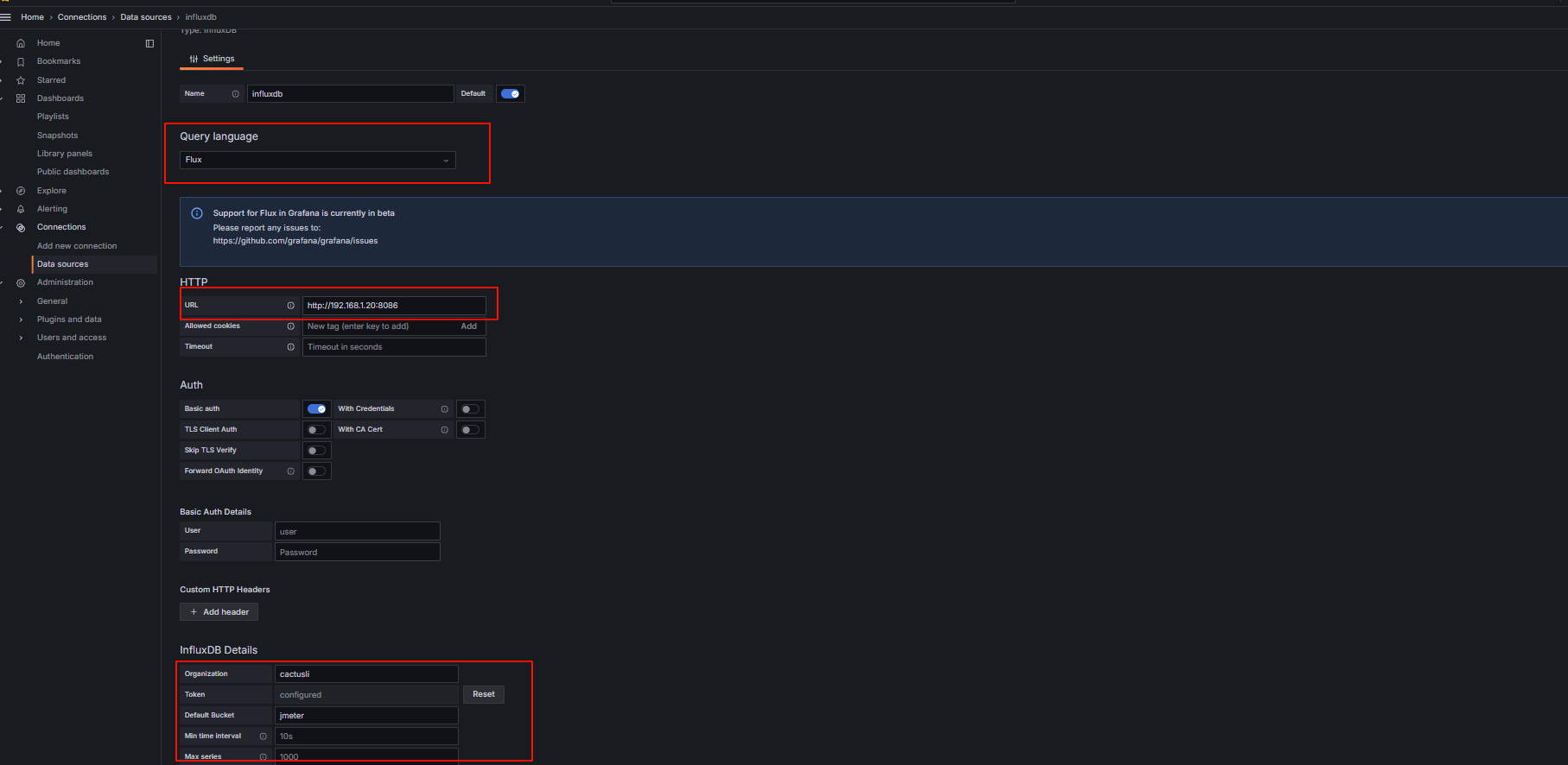
导入模板:
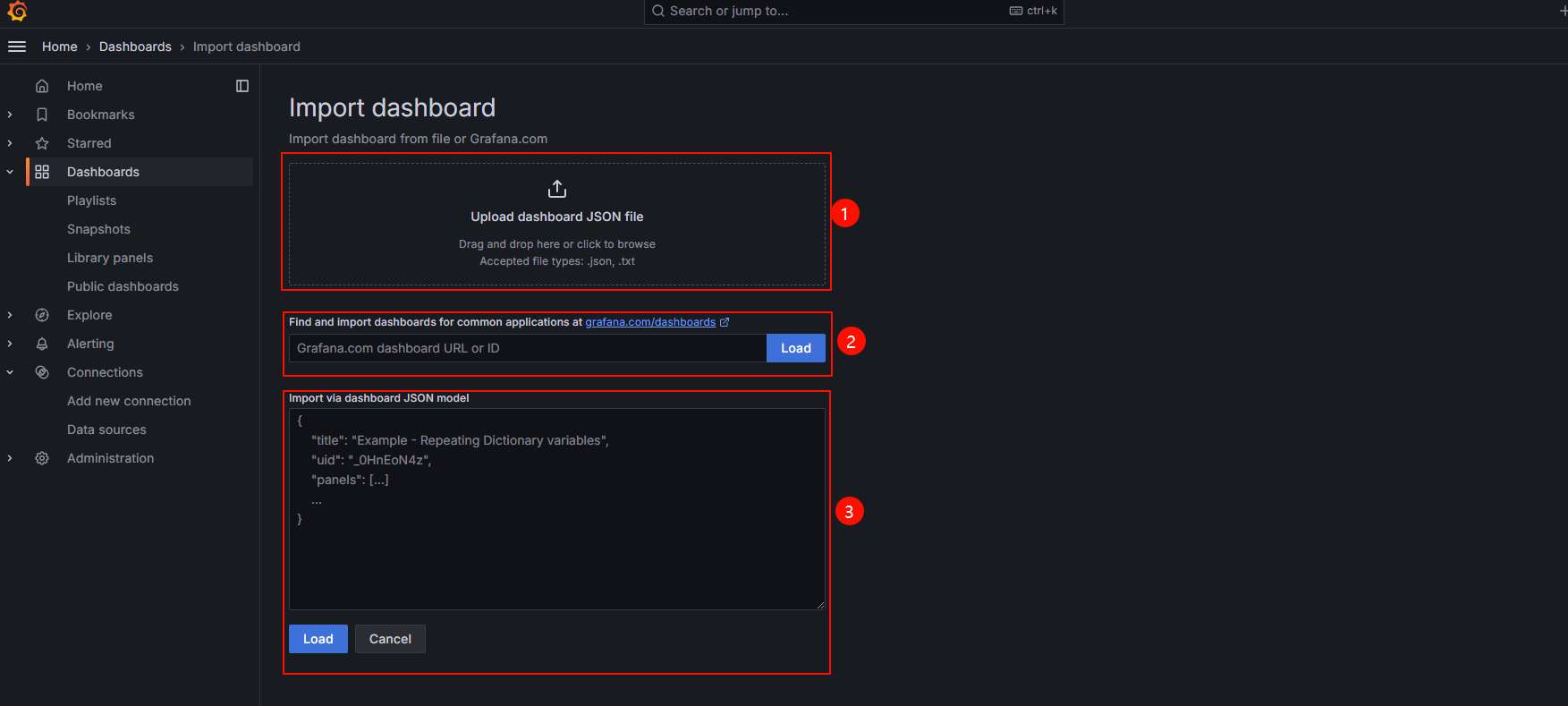
模板导入的3种方式:
- 直接上传模板json文件
- 直接输入模板id号
- 直接输入模板json内容
在Grafana的官网找到我们需要的展示模板:
- JMeter Report InfluxDB2.0
- dashboad-ID:17440
- JMeter Load Test (org.md.jmeter.influxdb2.visualizer) - influxdb v2.0 (Flux)
- dashboad-ID:13644
输入模板ID 13644进行 load, 选中创建的数据源进行导入。
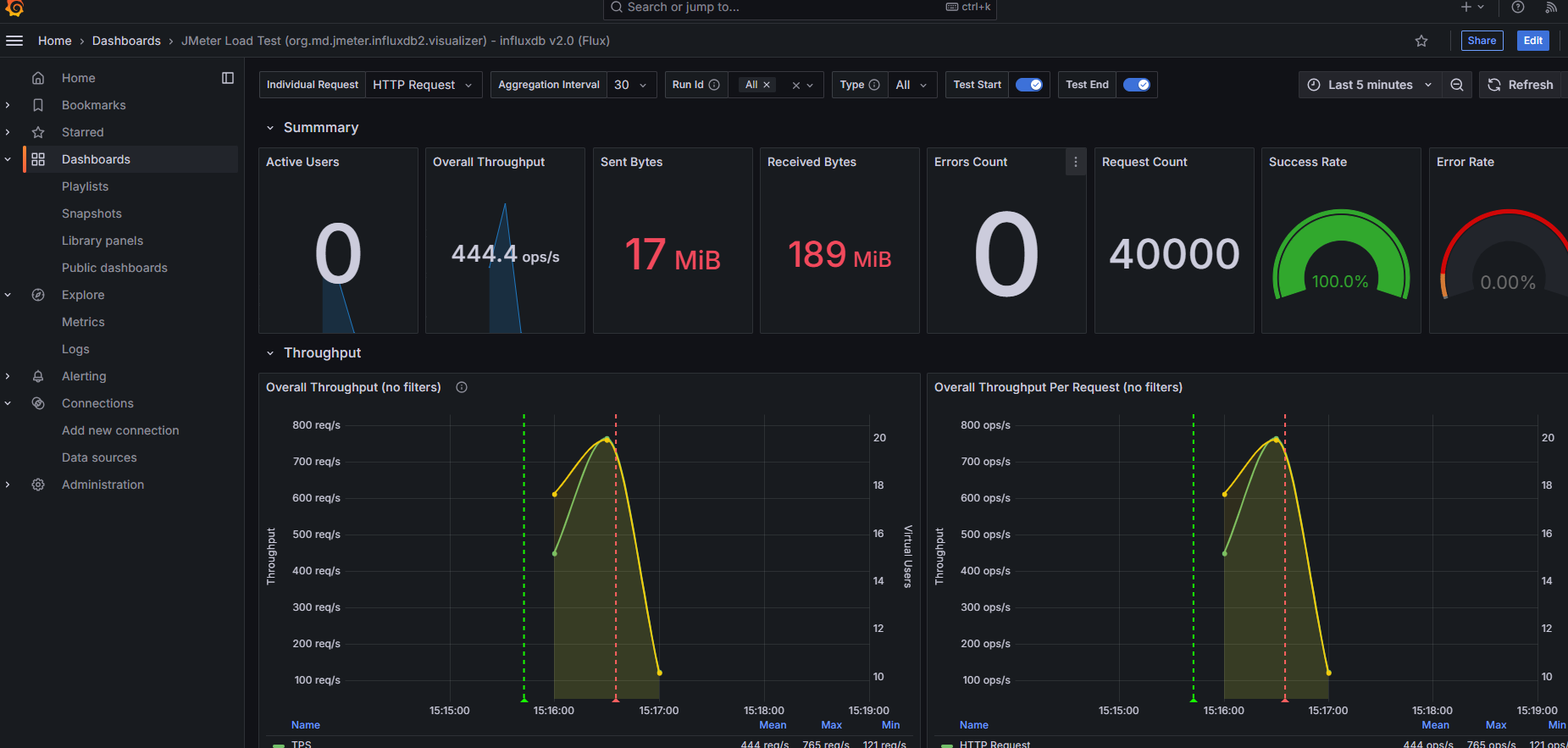
导入模板成功后就会看到如下界面:
1.4 安装安装 node_exporter
node-exporter使用Go语言编写,它主要用来监控主机系统的各项性能参数,可收集各种主机指标的库,还提供了textfile功能,用于自定义指标。
1.4.1 二进制安装
# 创建目录
mkdir node_exporter && cd node_exporter
# 下载二进制包
wget https://github.com/prometheus/node_exporter/releases/download/v1.8.2/node_exporter-1.8.2.linux-amd64.tar.gz
# 解压并进入目录
tar -xvf node_exporter-1.8.2.linux-amd64.tar.gz && cd node_exporter-1.8.2.linux-amd64
# 后台运行
nohup ./node_exporter > node.log 2>&1 &访问 :http://192.168.1.20:9100/metrics
1.4.2 Docker安装
官方不建议通过Docker方式部署node-exporter,因为它需要访问主机系统。 通过docker部署的方式,需要把任何非根安装点都绑定到容器中,并通过--path.rootfs参数指定。
docker run -d --net="host" --pid="host" -v "/:/host:ro,rslave" prom/node-exporter --path.rootfs=/host部署完成后,访问节点地址:http://ip:9100/metrics ,可看到node-exporter获取的指标。
1.4.3 配置node-exporter
node-exporter提供不少配置参数,可使用 --help 进行查看。 $ ./node_exporter --help
例如:通过--web.listen-address 改变监听的端口
./node_exporter --web.listen-address=":8080" &如果需要收集主机上面运行服务的状态,可启用systemd收集器。由于systemd指标较多,可以用--collector.systemd.unit-include参数配置只收集指定的服务,减少无用数据,该参数支持正则表达式匹配。如docker和ssh服务状态,
示例:./node_exporter --collector.systemd --collector.systemd.unit-include="(docker|sshd).service" &
如果只想启用需要的收集器,其他的全部禁用,可用如下格式配置
--collector.disable-defaults --collector.<name>1.5 安装Prometheus
Prometheus是一款近年来非常火热的容器监控系统,它使用go语言开发,设计思路来源于Google的Borgmom(一个监控容器平台的系统)。
产品由前谷歌SRE Matt T.Proudd发起开发,并在其加入SoundCloud公司后,与另一位工程师Julius Volz合伙推出,将其开源发布。
2016年,由Google发起的原生云基金会(Cloud Native Computing Foundation)将Prometheus纳入麾下,成为该基金会继Kubernetes后第二大开源项目。
Prometheus天然具有对容器的适配性,可非常方便的满足容器的监控需求,也可用来监控传统资源。近年来随着kubernetes容器平台的火爆,Prometheus的热度也在不断上升,大有超越老牌监控系统Zabbix成为No.1的趋势,目前已在众多公司得到广泛的使用。
1.5.1 二进制安装
创建目录:
mkdir prometheus && cd prometheus# 下载安装包
wget https://github.com/prometheus/prometheus/releases/download/v3.0.1/prometheus-3.0.1.linux-386.tar.gz
# 解压tar包并进入目录
tar -xvf prometheus-3.0.1.linux-386.tar.gz && cd prometheus-3.0.1.linux-386运行--version 检查版本
root@xx:/sg-work/prometheus/prometheus-3.0.1.linux-386# ./prometheus --version
prometheus, version 3.0.1 (branch: HEAD, revision: 1f56e8492c31a558ccea833027db4bd7f8b6d0e9)
build user: root@e249152d3bff
build date: 20241128-17:26:10
go version: go1.23.3
platform: linux/386
tags: netgo,builtinassets,stringlabels编辑配置文件:
vim /sg-work/prometheus/prometheus-3.0.1.linux-386/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']启动Prometheus,并指定配置文件:
nohup ./prometheus --config.file /sg-work/prometheus/prometheus-3.0.1.linux-386/prometheus.yml > prometheus.log 2>&1 &注意:Prometheus默认只保留15天的监控数据,可通过--storage.tsdb.retention选项控制时间序列的保留时间;--storage.tsdb.path选项可用于控制时间序列数据库位置,默认数据目录位于运行Prometheus的目录中。
1.5.2 Docker安装
docker的安装方式很简单,只需要一条命令即可
docker run --name prometheus -d -p 9090:9090 prom/prometheus如果要将配置文件与容器分离,可将prometheus.yml文件保存在本地目录 ,在启动时通过-v参数挂载到容器上面
mkdir prometheus && cd prometheus
vim /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']启动容器:
docker run --name prometheus -d -p 9090:9090 \
-v /sg-work/prometheus/prometheus-3.0.1.linux-386/prometheus.yml:/etc/prometheus/prometheus.yml \
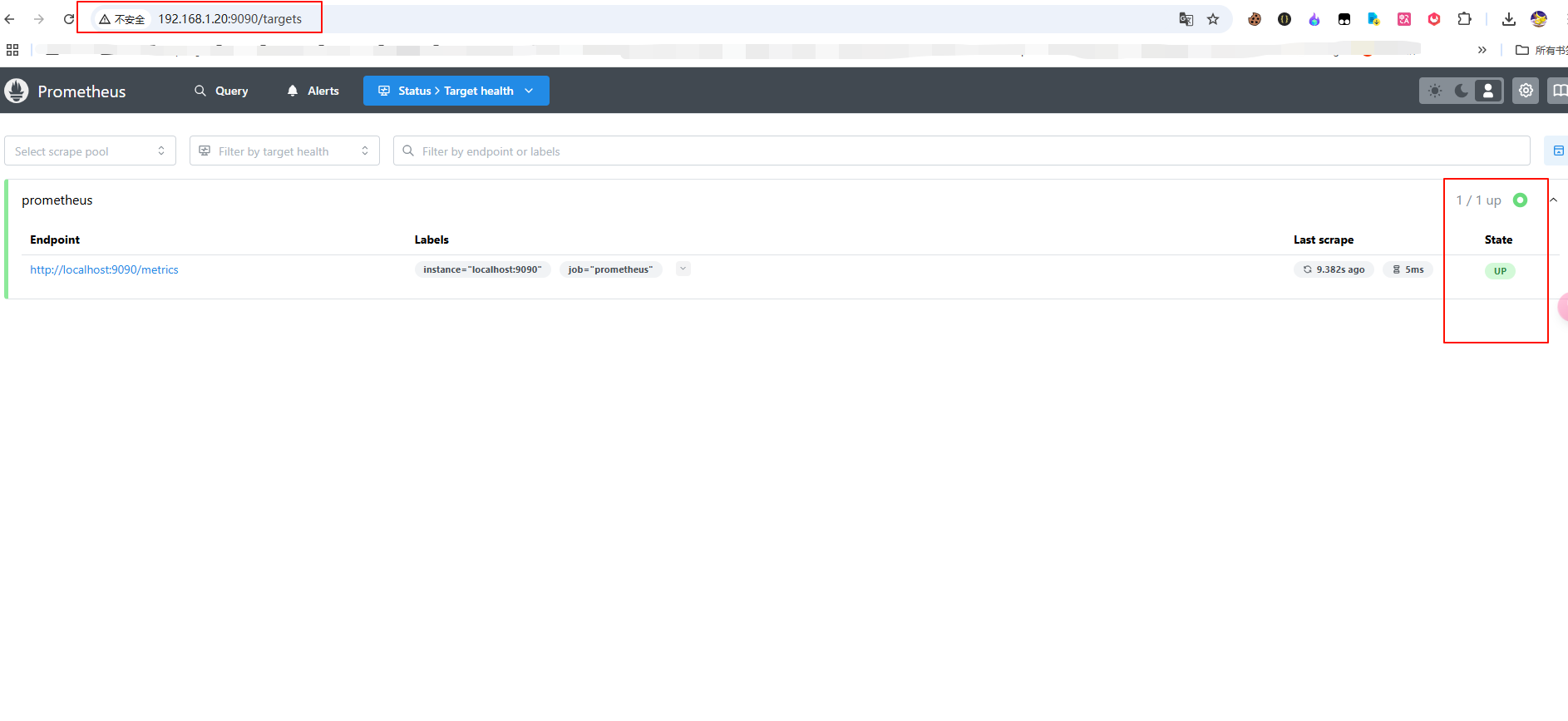
prom/prometheus启动完成后,打开浏览器,访问http://192.168.1.20:9090/targets 可看到系统界面。
1.6 在Grafana中配置Prometheus的数据源
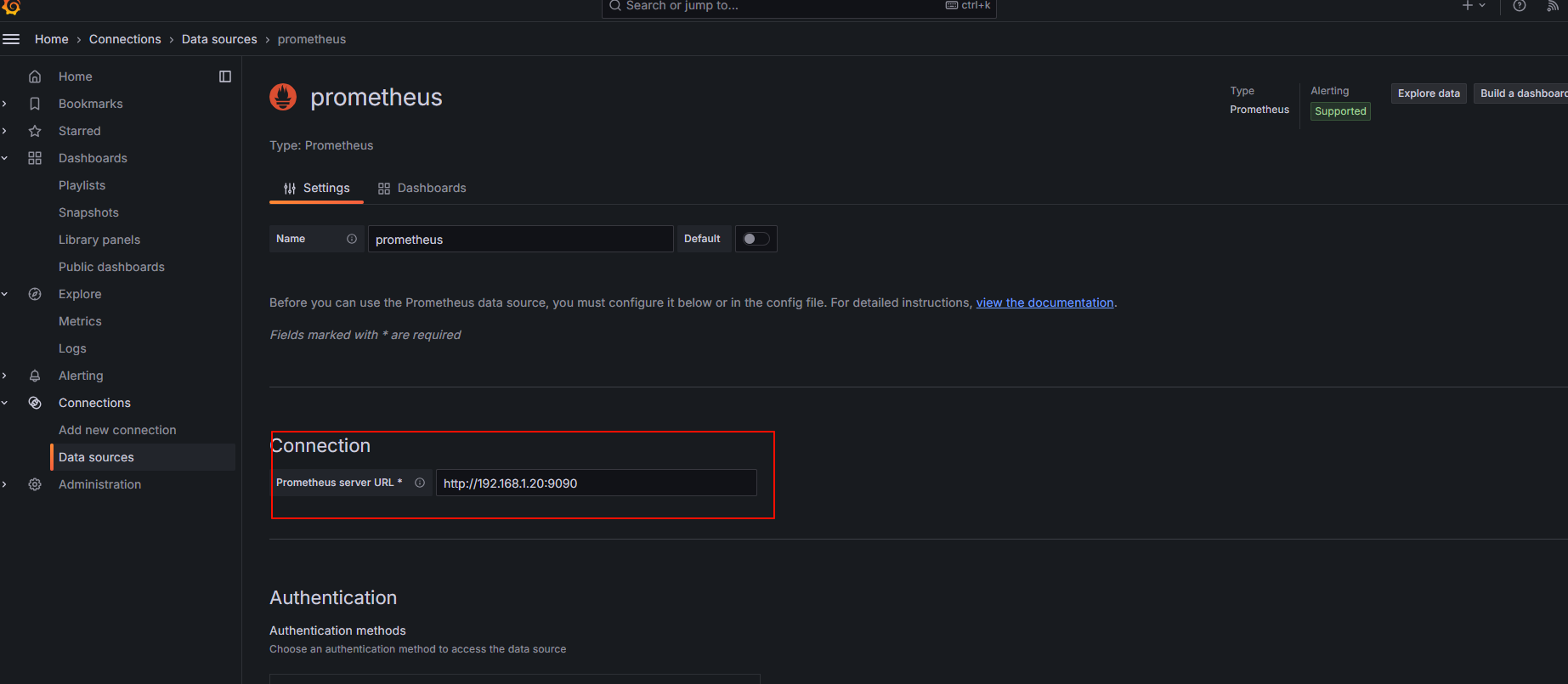
Grafana导入Linux展示模板 :
导入Linux系统dashboard
Node Exporter for Prometheus Dashboard based on 11074
- dashboard-ID: 15172
K8s Node Metrics / Multi Clusters (Node Exporter, Prometheus, Grafana11, 2024, EN)
- dashboard-ID: 22413
2. 梯度压测:分析接口性能瓶颈
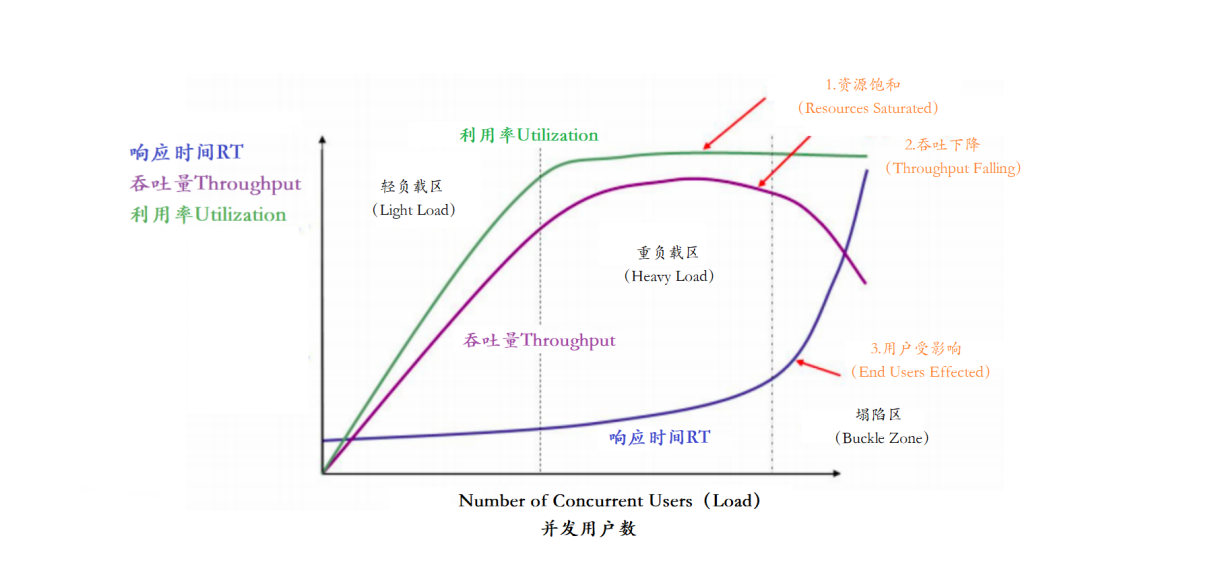
分析接口性能瓶颈,主要指标有【响应时间、并发用户数、吞吐量、资源使用率】她们之间存在一定的相关性,共同感应出性能的不同方面。
在 Jmeter 中执行一次测试接口如下:
http://218.249.73.244:48080/web-api/web/gateway/newsPage?userId=&pageNo=1&pageSize=10&status=6
响应时间30ms,响应数据包190.23kb,请求数据包19.49kb
2.1 模拟低延时场景
用户访问接口并发逐渐增加的过程,预计接口的响应时间为30ms.
线程梯度:5、10、15、20、25、30、35、40个线程
循环请求次数5000次
时间设置:Ramp-up period(inseconds)的值设为对应线程数
测试总时长:约等于30ms x 5000次 x 8 = 800s = 13.3分
测试时长(秒)=单次请求时间(秒)×请求次数×Ramp-up 时间的线程倍数
0.02×5000=100秒, 8×100=800秒=13.3分钟
配置断言:超过3s,响应状态码不为200,则为无效请求
2.2 压测机器环境配置
- 应用服务器配置:8C18G
- 外网-网络带宽100 Mbps (峰值)
- 内网-网络带宽基础1.5/最高10Gbit/s
- 集群规模:单节点
- 数据库服务器配置:8C16G
| 单位 | 全称 | 换算关系 |
|---|---|---|
| Mbps | Megabit per second | 网络速度的单位 |
| MB/s | Megabyte per second | 数据传输的单位 |
| 1 byte | 1 字节 | 等于 8 bits |
| 1 bit | 1 位 | 等于 0.125 bytes |
| 1 megabit | 1 兆位 | 等于 1,000,000 bits |
| 1 megabyte | 1 兆字节 | 等于 1,000,000 bytes |
| 1 megabit | 转换为 megabytes | 等于 0.125 megabytes |
| 1 Mbps | 转换为 MB/s | 等于 0.125 MB/s |
结论:
1 Gbit/s = 1 Gbps = 125 MB/s
1 Mbps = 0.125 MB/s
2.3 配置监听器
聚合报告
- 添加聚合报告,汇总统计结果。
查看结果树
- 添加“查看结果树”监听器,便于查看压测结果。
活动线程数
- 显示压力机中当前活动的线程数。
TPS统计分析
- 每秒事务数(Transactions Per Second,TPS)统计分析。
RT统计分析
- 响应时间(Response Time,RT)的统计分析。
配置监听器
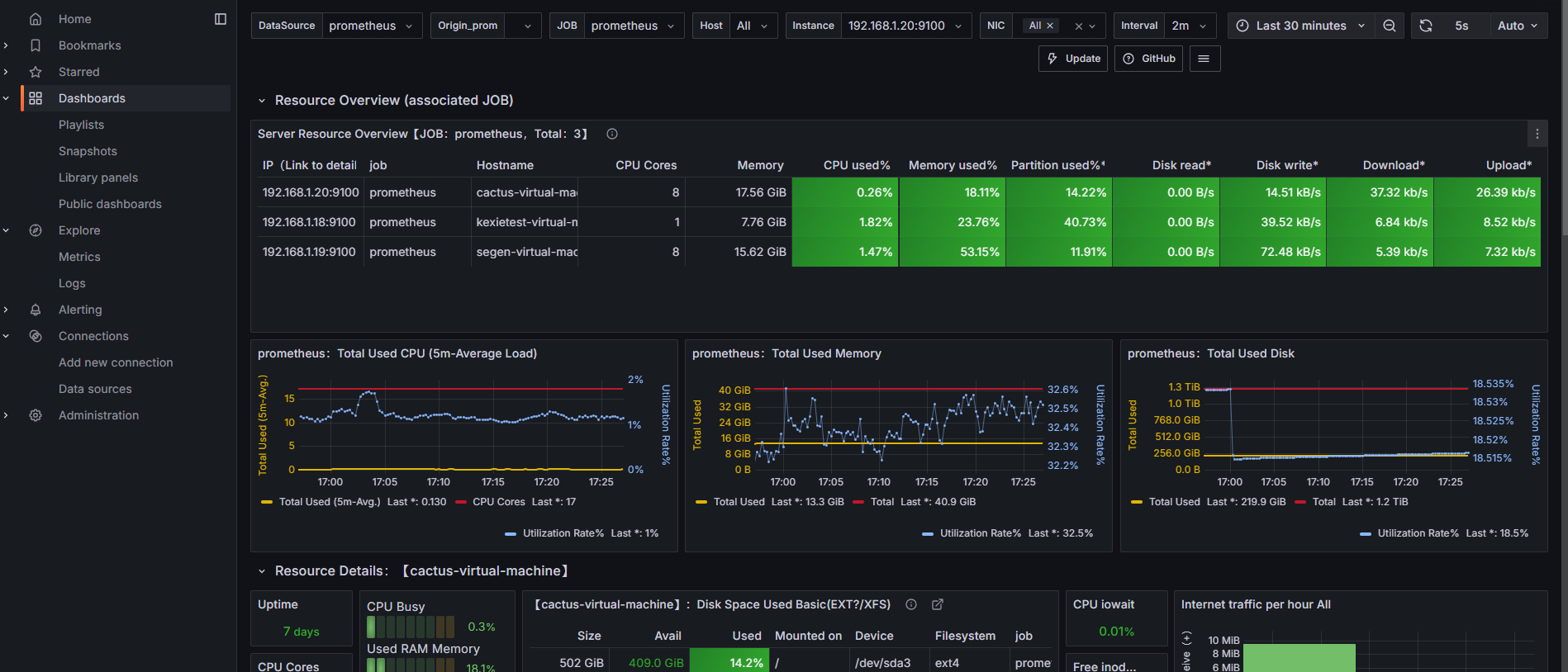
- 将压测信息汇总到 InfluxDB,并在 Grafana 中可视化展示。
压测监控平台:
- JMeter Dashboard:全面监控压测过程中的各项指标。
- 应用服务器监控:内存、网络、磁盘、系统负载情况等性能指标。
- MySQL服务器监控:内存、网络、磁盘、系统负载情况等性能指标。
2.4 性能瓶颈剖析
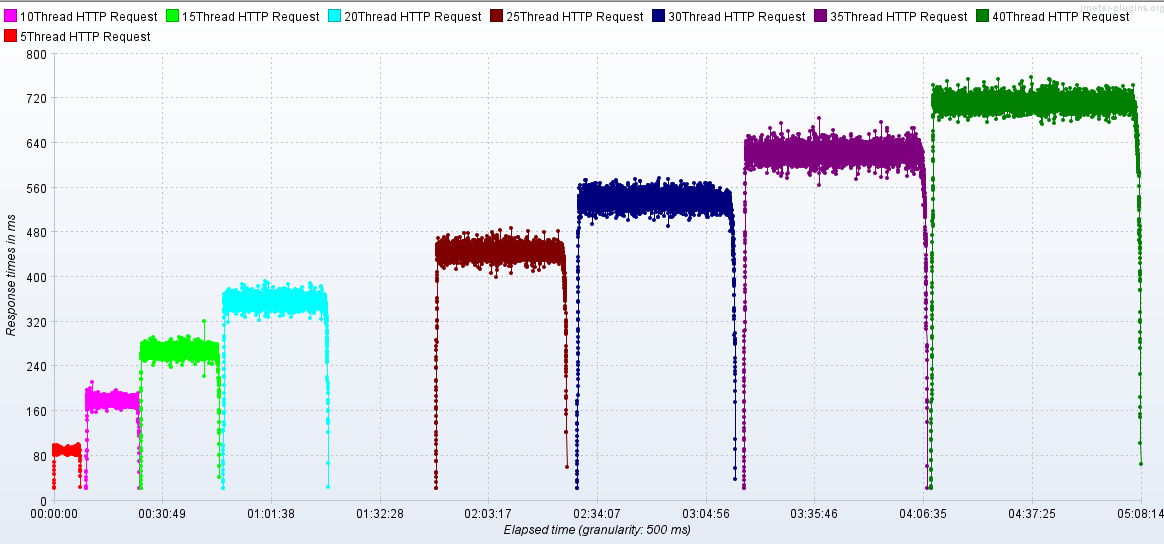
2.4.1 梯度压测,测出瓶颈
通过逐步提升压力,测试性能瓶颈:
| 线程数 | 循环次数 | 样本总数 |
|---|---|---|
| 5 | 5000 | 2.5 万个样本 |
| 10 | 5000 | 5 万个样本 |
| 15 | 5000 | 7.5 万个样本 |
| 20 | 5000 | 10 万个样本 |
| 25 | 5000 | 12.5 万个样本 |
| 30 | 5000 | 15 万个样本 |
| 35 | 5000 | 17.5 万个样本 |
| 40 | 5000 | 20 万个样本 |
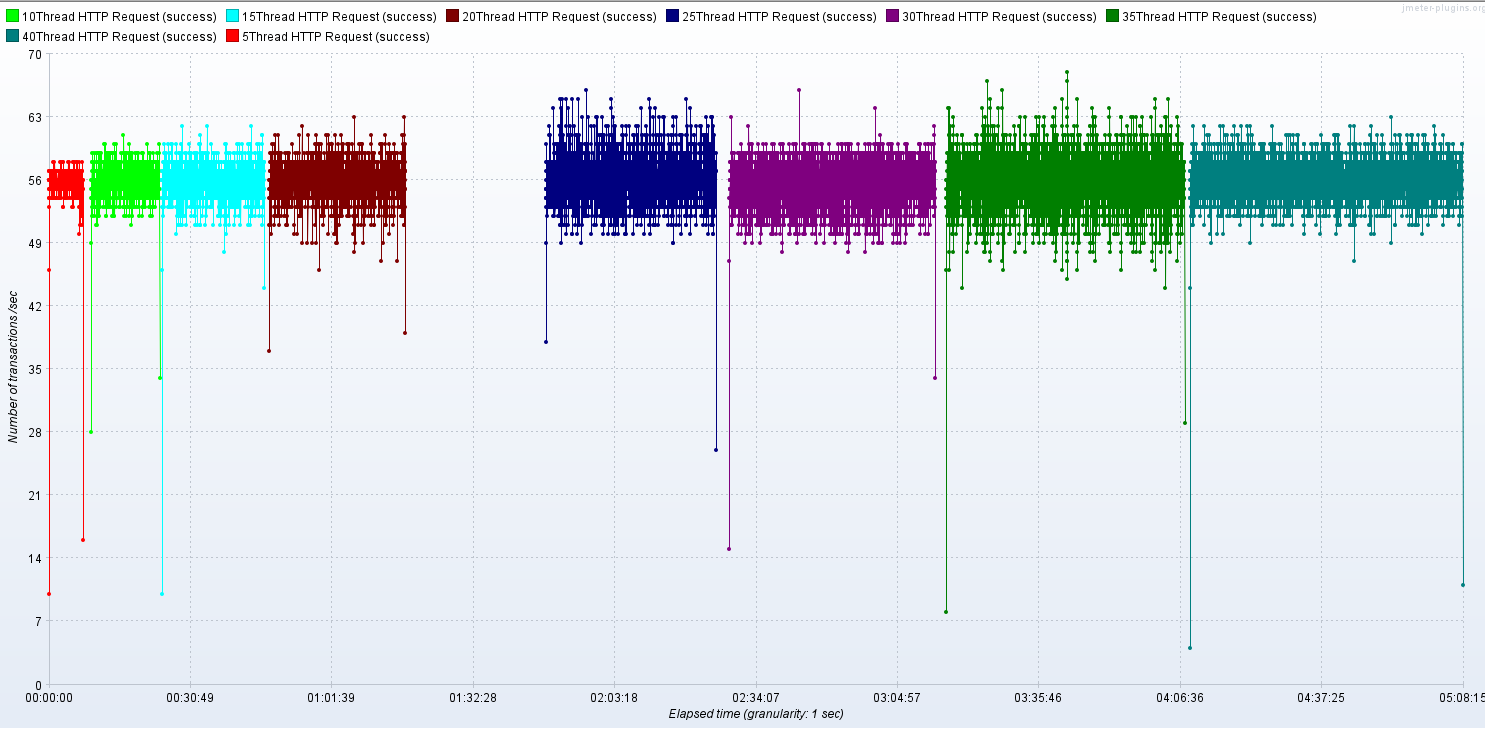
梯度压测后的聚合报告

Active Threads
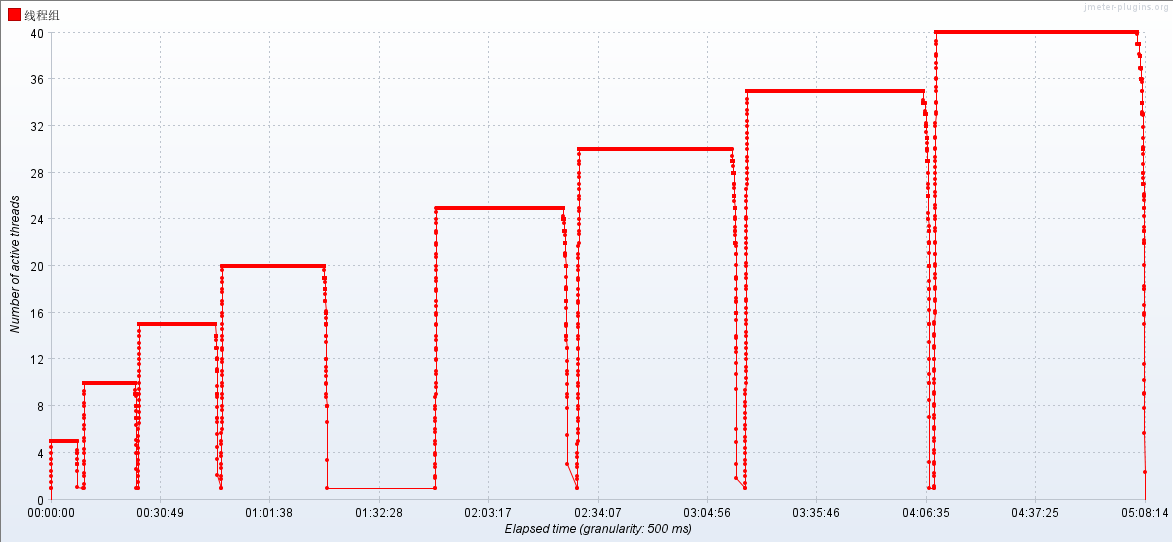
RT
TPS
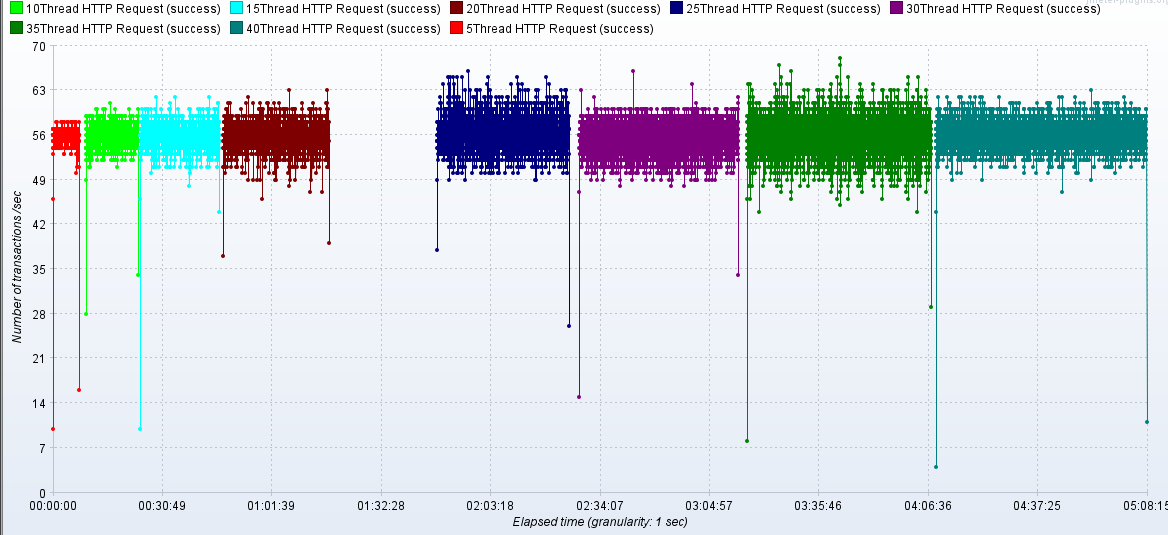
压测监控平台与JMeter压测结果一致
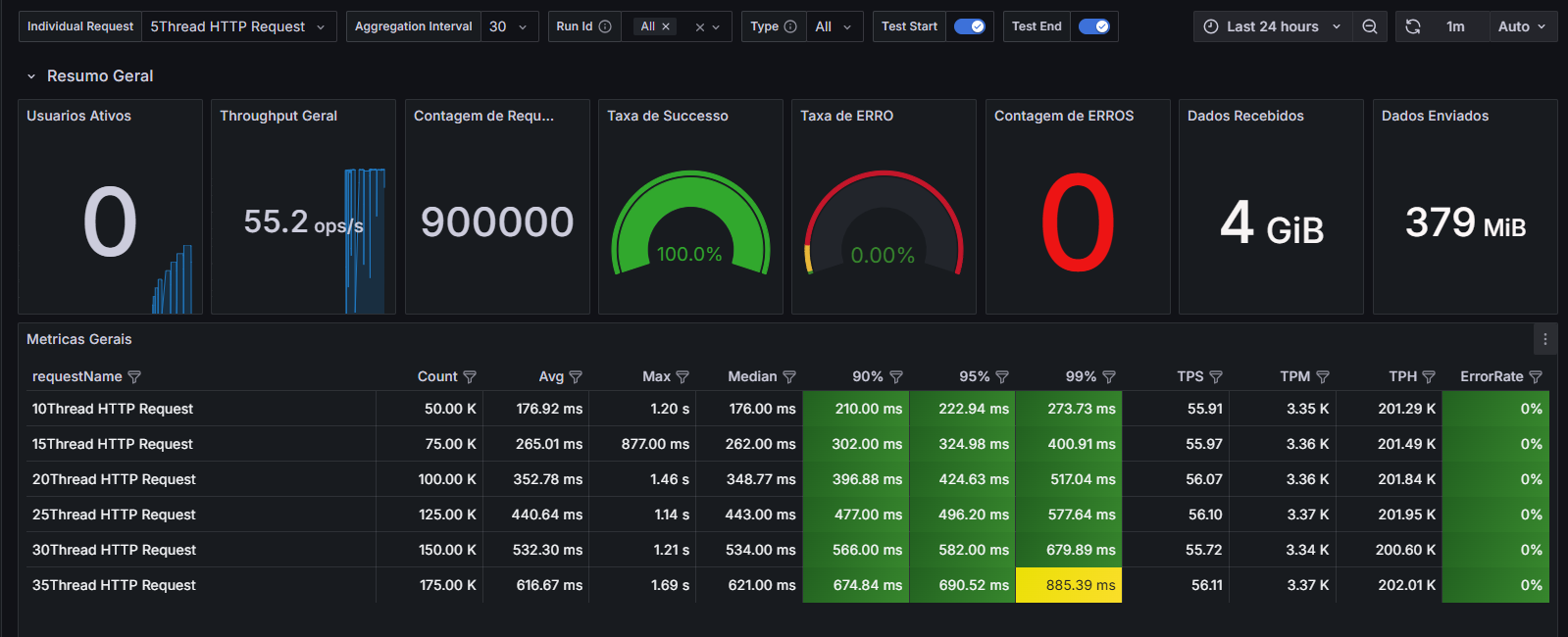
压测中服务器监控指标
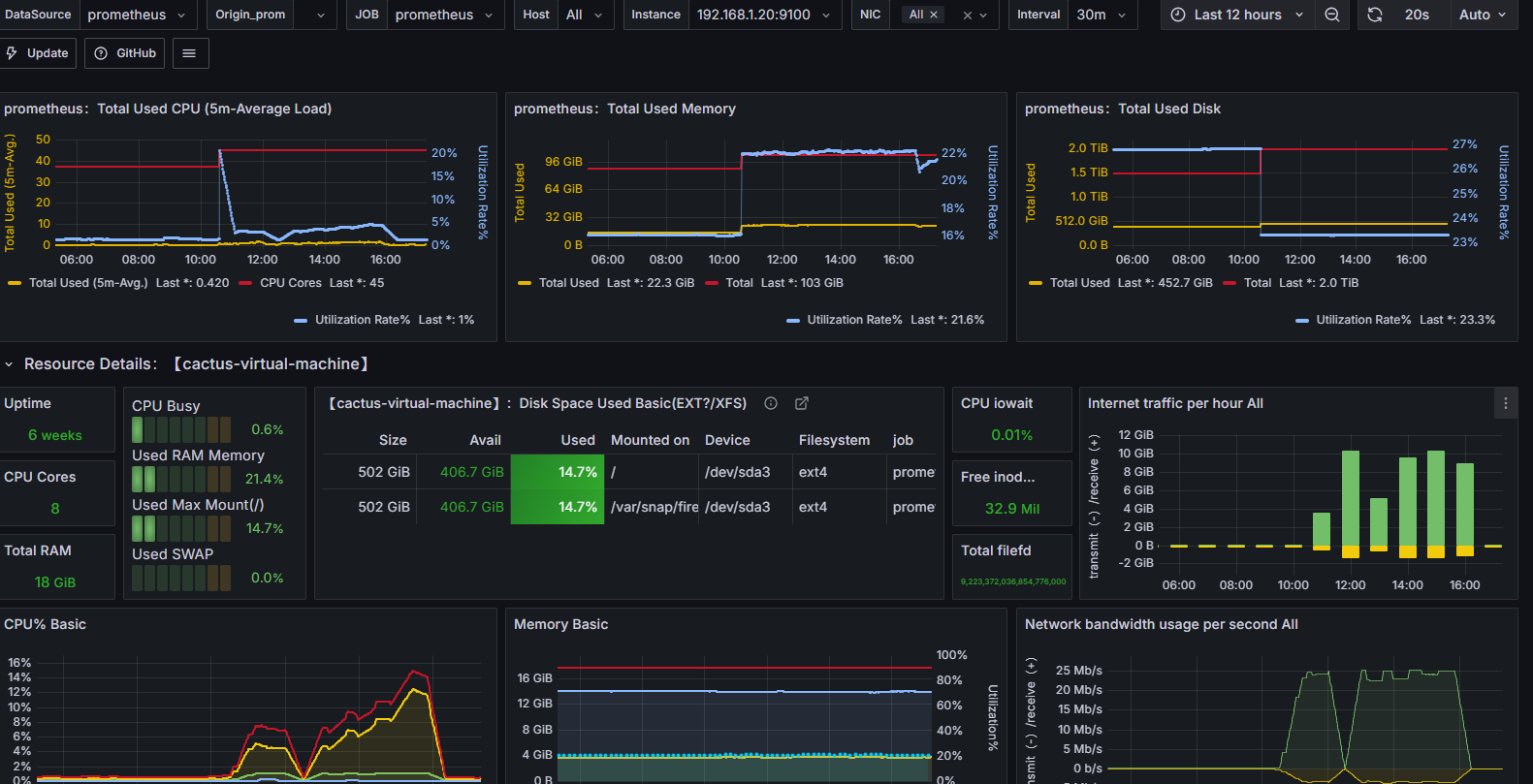
2.4.2 问题1:网络到达瓶颈
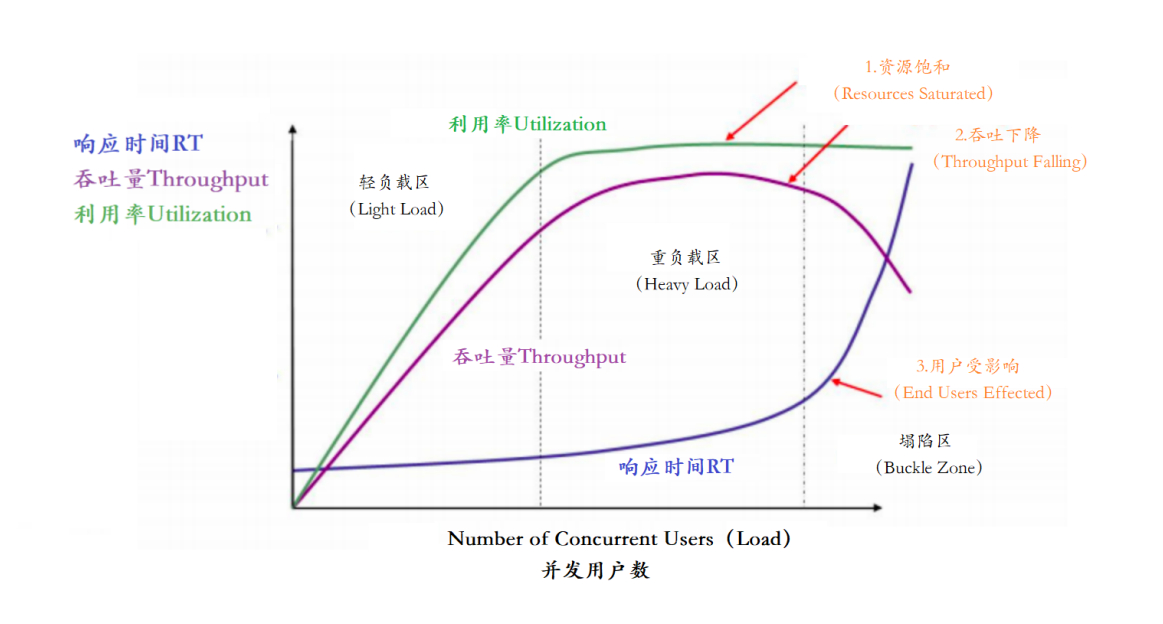
**结论:**随着压力的上升,TPS不再增加,接口响应时间逐渐在增加,偶尔出现异常,瓶颈凸显。系统的 负载不高。CPU、内存正常,说明系统这部分资源利用率不高。带宽带宽显然已经触顶了。
优化之后的解决方案:
方案01-降低接口响应数据包大小
调整接口请求和返回的数据量大小,响应数据包73kb,请求数据包42kb
http://218.249.73.244:48080/web-api/web/gateway/newsPage?userId=&pageNo=1&pageSize=1&status=6
方案02-提升带宽【或者在内网压测】
25Mbps --> 100Mbps
云服务器内网:这里在Linux中执行JMeter压测脚本
jmeter -n -t 首页.jmx -l 首页.jtl
优化之后效果,基于方案01-降低接口响应数据包大小,压测结果如下图所示:

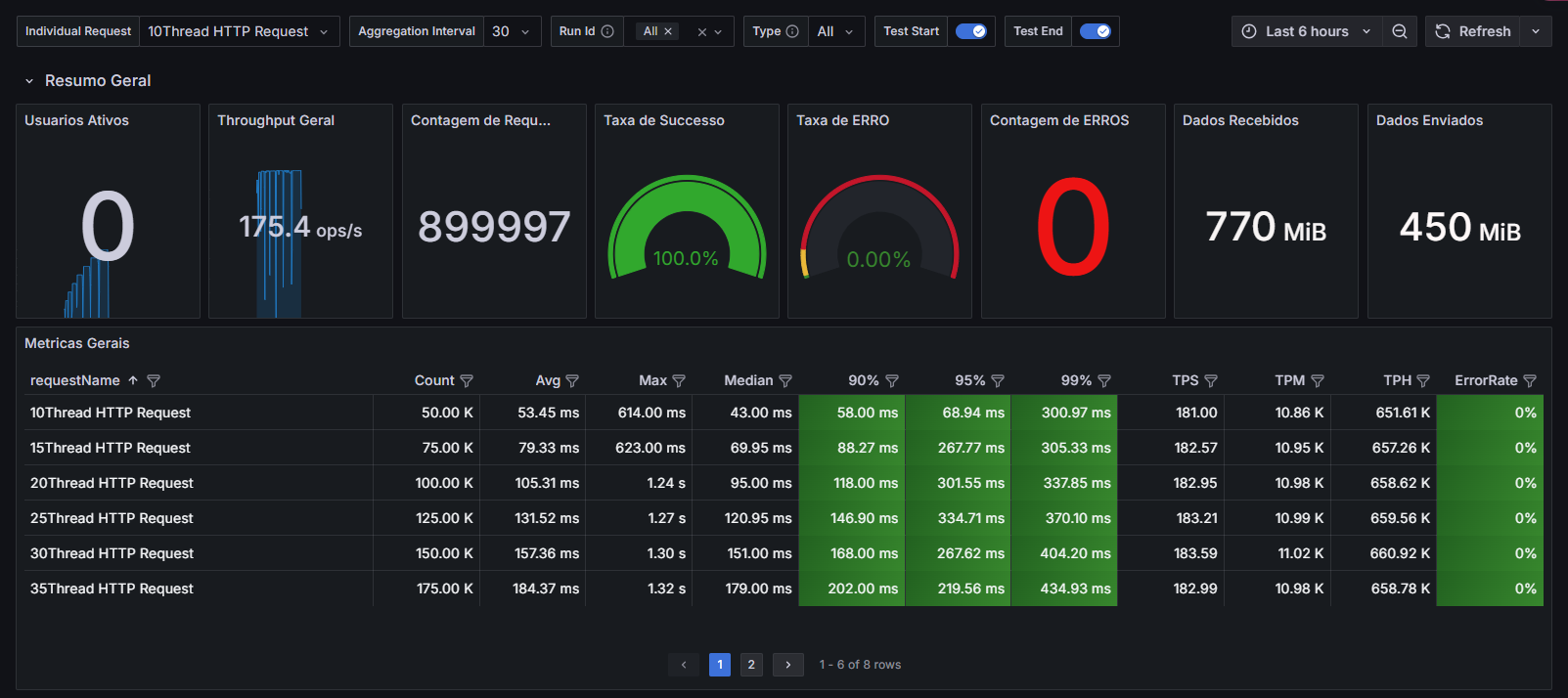
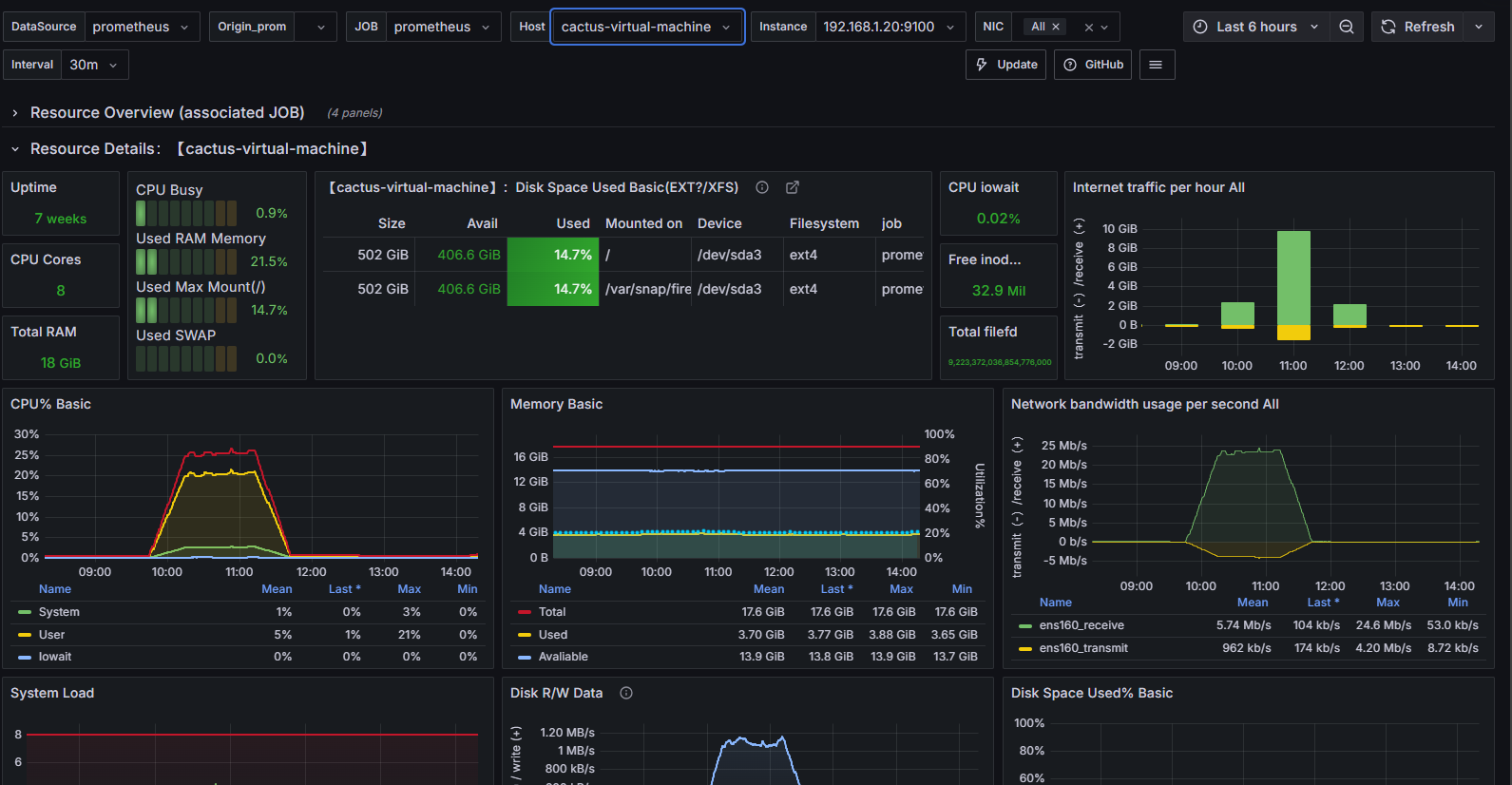
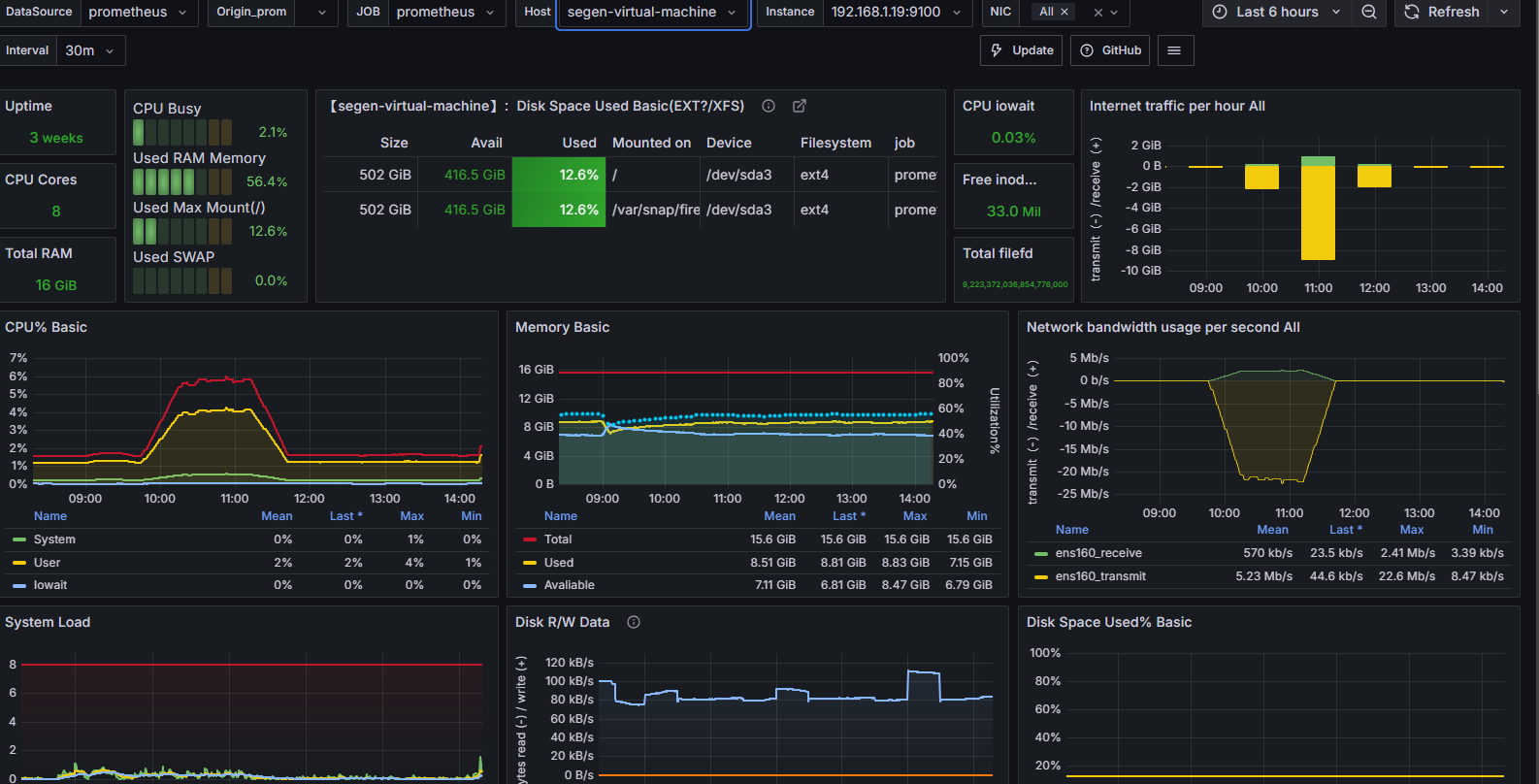
方案02-提升带宽【或者在内网压测】
提升自己测试机器的网络宽带,或在机器内网进行压测!
问题:可不可以基于RT与TPS算出服务端并发线程数?
服务端线程数计算公式:TPS/ (1000ms/ RT均值)
- RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
- RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 400
- RT=1000ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 800
结论:
- 在低延时场景下,服务瓶颈主要在服务器带宽。
- TPS数量等于服务端线程数 乘以 (1000ms/ RT均值)
- RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
2.4.3 问题2:接口的响应时间是否正常?是不是所有的接口响应都可以这么快?
情况02-模拟高延时场景,用户访问接口并发逐渐增加的过程。接口的响应时间为500ms;
线程梯度:100、200、300、400、500、600、700、800个线程;
循环请求次数200次
时间设置:Ramp-up period(inseconds)的值设为对应线程数的1/10;
- 测试总时长:约等于500ms x 200次 x 8 = 800s = 13分
配置断言:超过3s,响应状态码不为200,则为无效请求
@GetMapping("/newsPage")
@Operation(summary = "前端门户获得新闻分页")
public CommonResult<PageResult<NewsPageWebReqVO>> getNewsPage(@Valid NewsSelectWebReqVO pageReqVO) {
//查询已发布的新闻
pageReqVO.setAuditStatus(1);
PageResult<NewsDO> pageResult = webService.selectWebNewsPage(pageReqVO);
try {
//休眠500ms
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return success(BeanUtils.toBean(pageResult, NewsPageWebReqVO.class));
}响应慢接口:500ms+,响应数据包73kb,请求数据包42kb
http://218.249.73.244:48080/web-api/web/gateway/newsPage?userId=&pageNo=1&pageSize=1&status=6测试结果:RT、TPS、网络IO、CPU、内存、磁盘IO

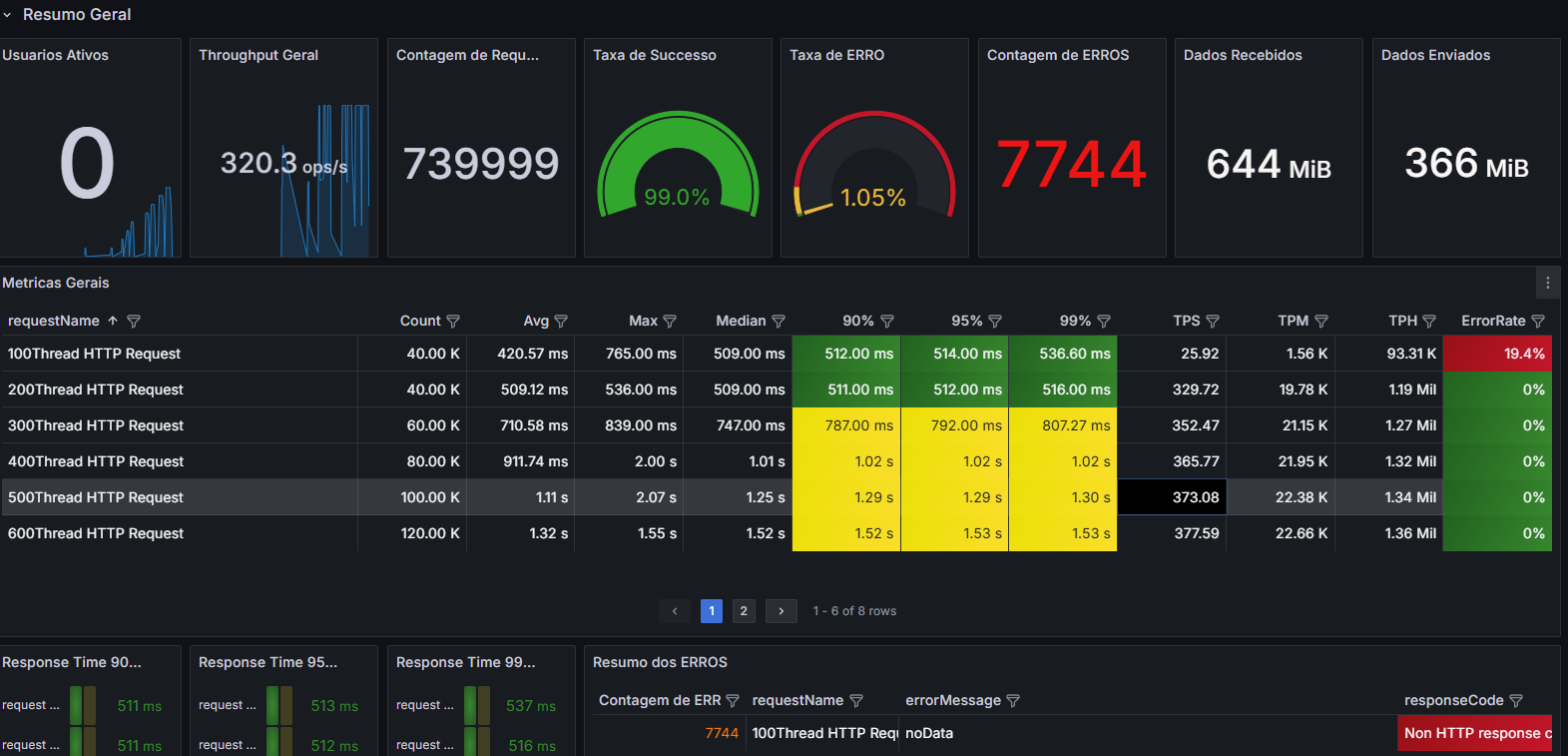
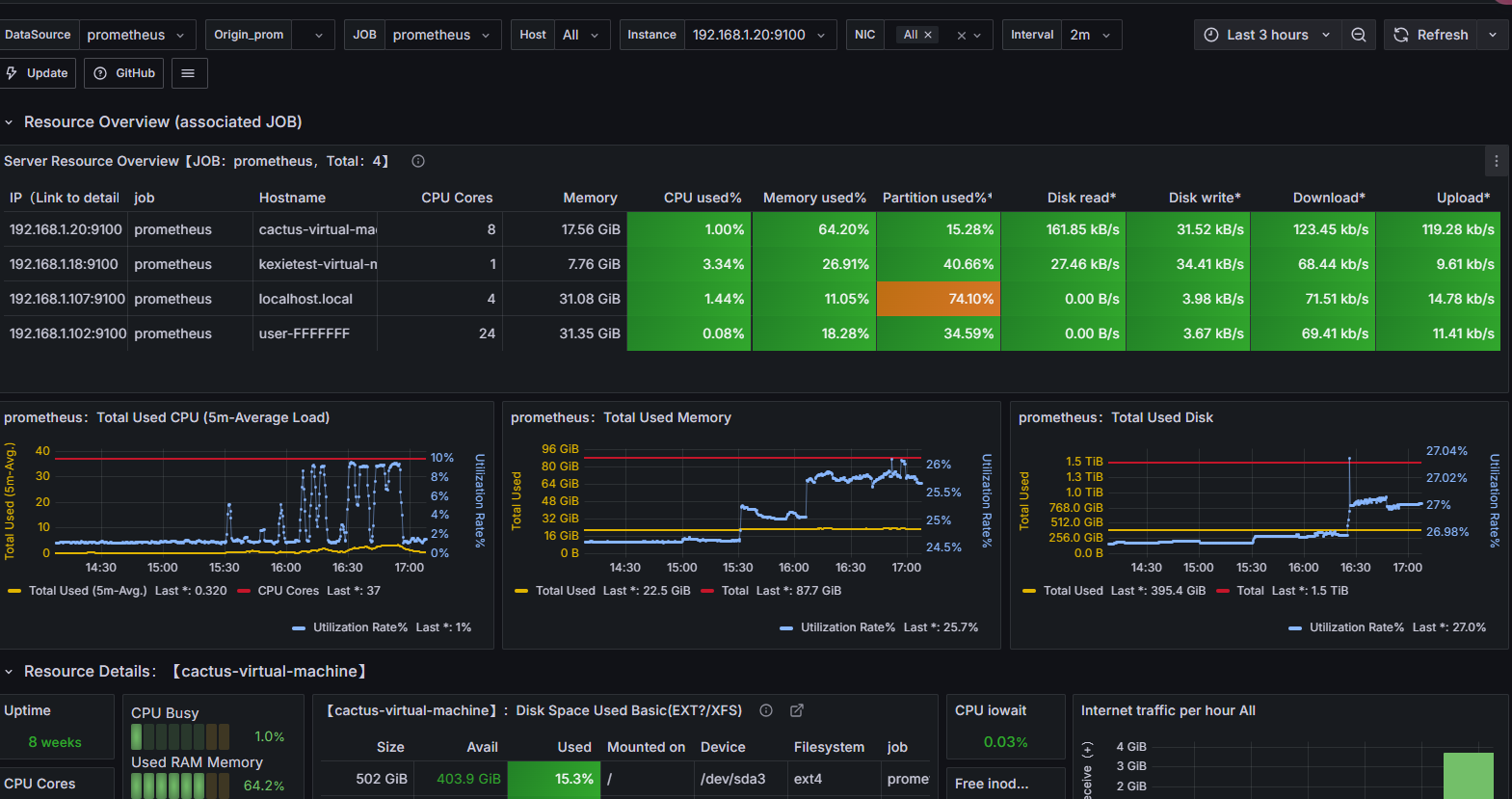
最后结论
- 在高延时场景下,服务瓶颈主要在容器最大并发线程数。
- RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT) = 400
- 观察服务容器最大线程数,发现处理能力瓶颈卡在容器端
2.4.4 问题3:TPS在上升到一定的值之后,异常率可能会变的比较高
- 可以理解为与IO模型有关系,因为当前使用的是阻塞式IO模型。
- 解决方案,刚换成非阻塞式IO模型。