Jmeter的安装使用
1. Jmeter 安装
安装可分为本地安装或者是服务器安装,一般正规的时使用方法是本地安装后在写测试计划和脚本看效果。脚本写完后,将jmx脚本放到服务器来执行压测。
1.1 本地安装和服务器安装
本地安装所需环境
环境:JDK 1.8+
官网:https://jmeter.apache.org/download_jmeter.cgi
阿里云镜像:https://mirrors.aliyun.com/apache/jmeter/binaries/
服务器安装方法
环境:Ubuntu 22.04 + Docker 26.0.0
在服务器上安装直接使用 docker-compose.yml
version: '3'
services:
# JMeter是一个功能强大的性能测试工具,可以模拟多种类型的负载,并提供详细的测试报告
# 官网:https://jmeter.apache.org/
# 脚本:jmeter -n -t one.jmx -l one.jtl
Jmeter:
image: justb4/jmeter:5.6.3
container_name: jmeter
restart: always
environment:
- DISPLAY=:0
- TZ=Europe/Paris
volumes:
- ./jmx/:/opt/apache-jmeter-5.5/jmx/1.2 启动 Jmeter
解压 apache-jmeter-5.6.3.zip, 进入到 bin 目录下:
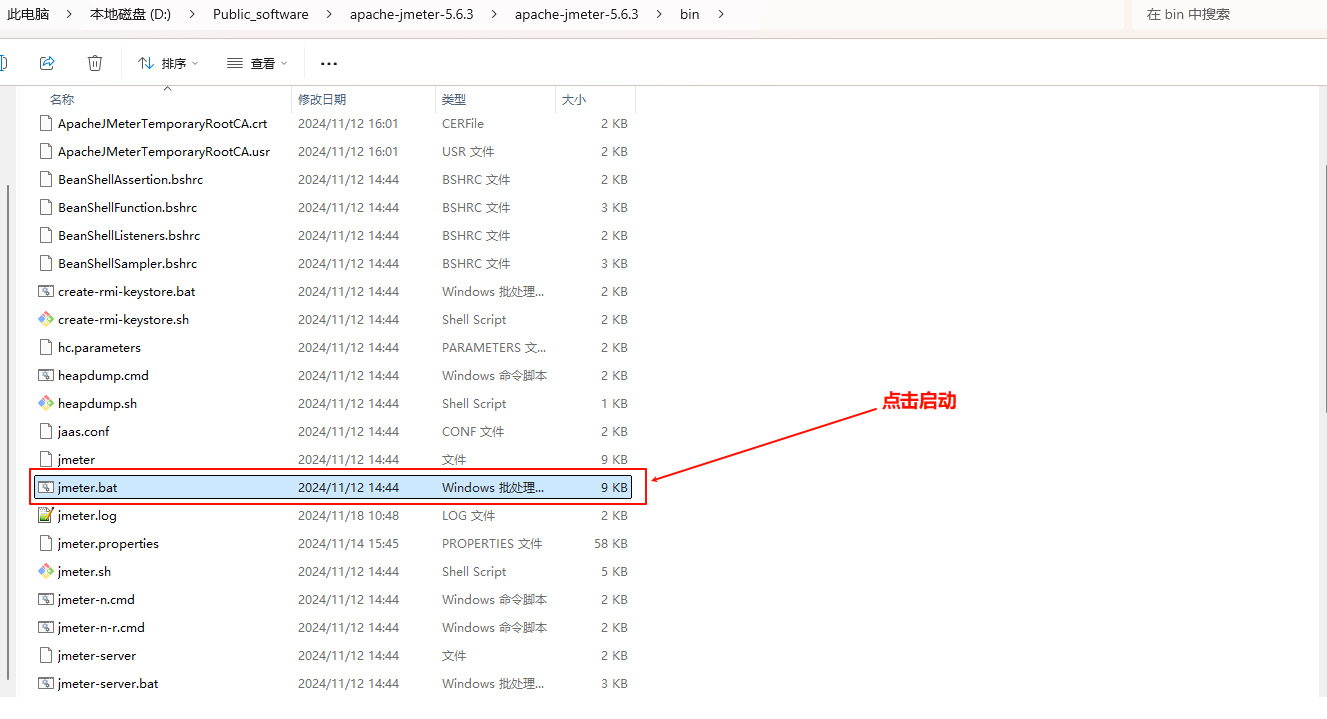
Windows 电脑,直接点 jmeter.bat 启动。
Mac 电脑,在 jmeter 右键,选择终端启动。
1.3 切换语言
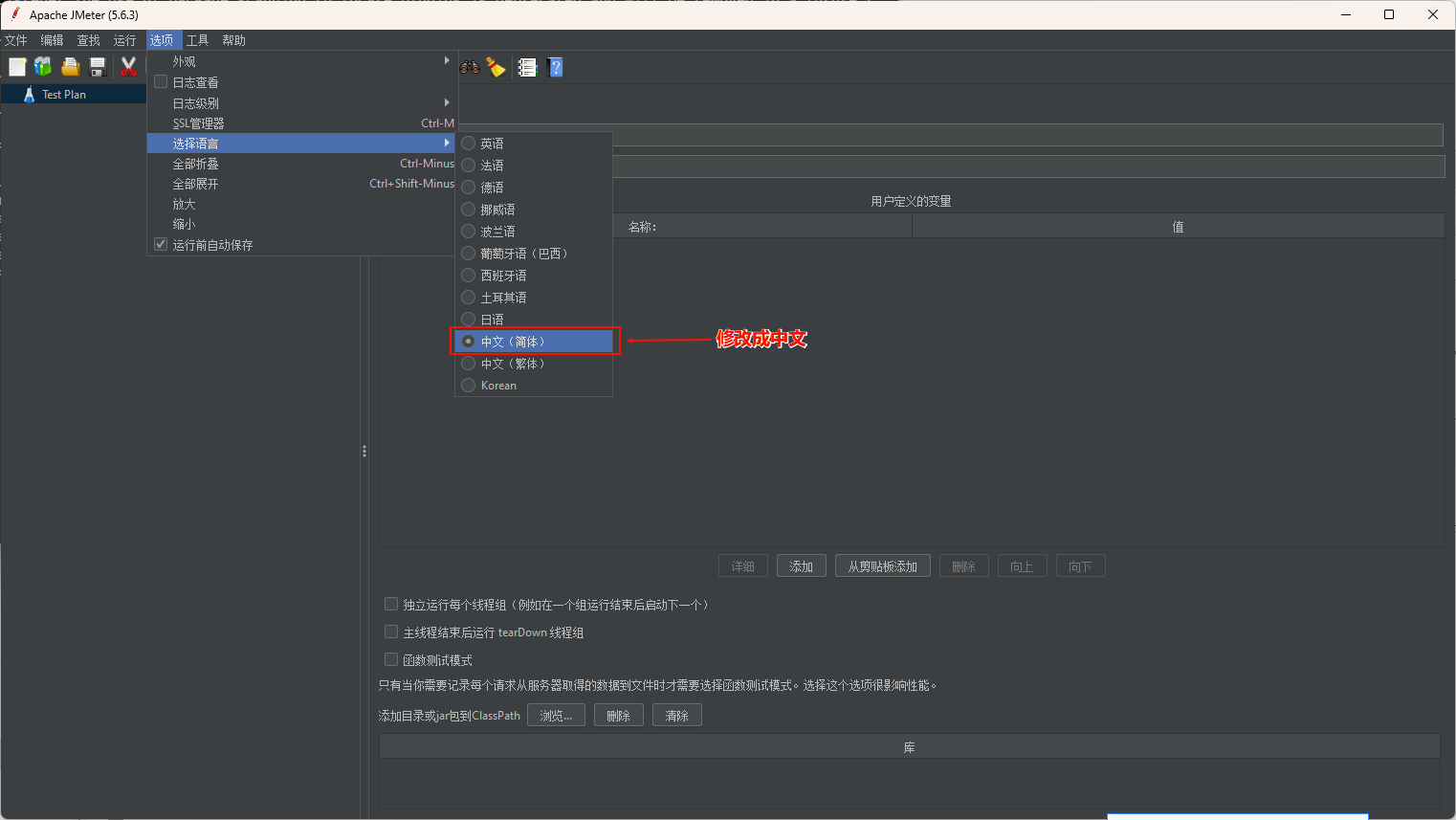
修改语言的方式:
进入 D:\Public_software\apache-jmeter-5.6.3\apache-jmeter-5.6.3\bin\jmeter.properties 设置 language=zh_CN。
如图,进入页面,手动选择。
在保存测试计划时会出现如图错误。
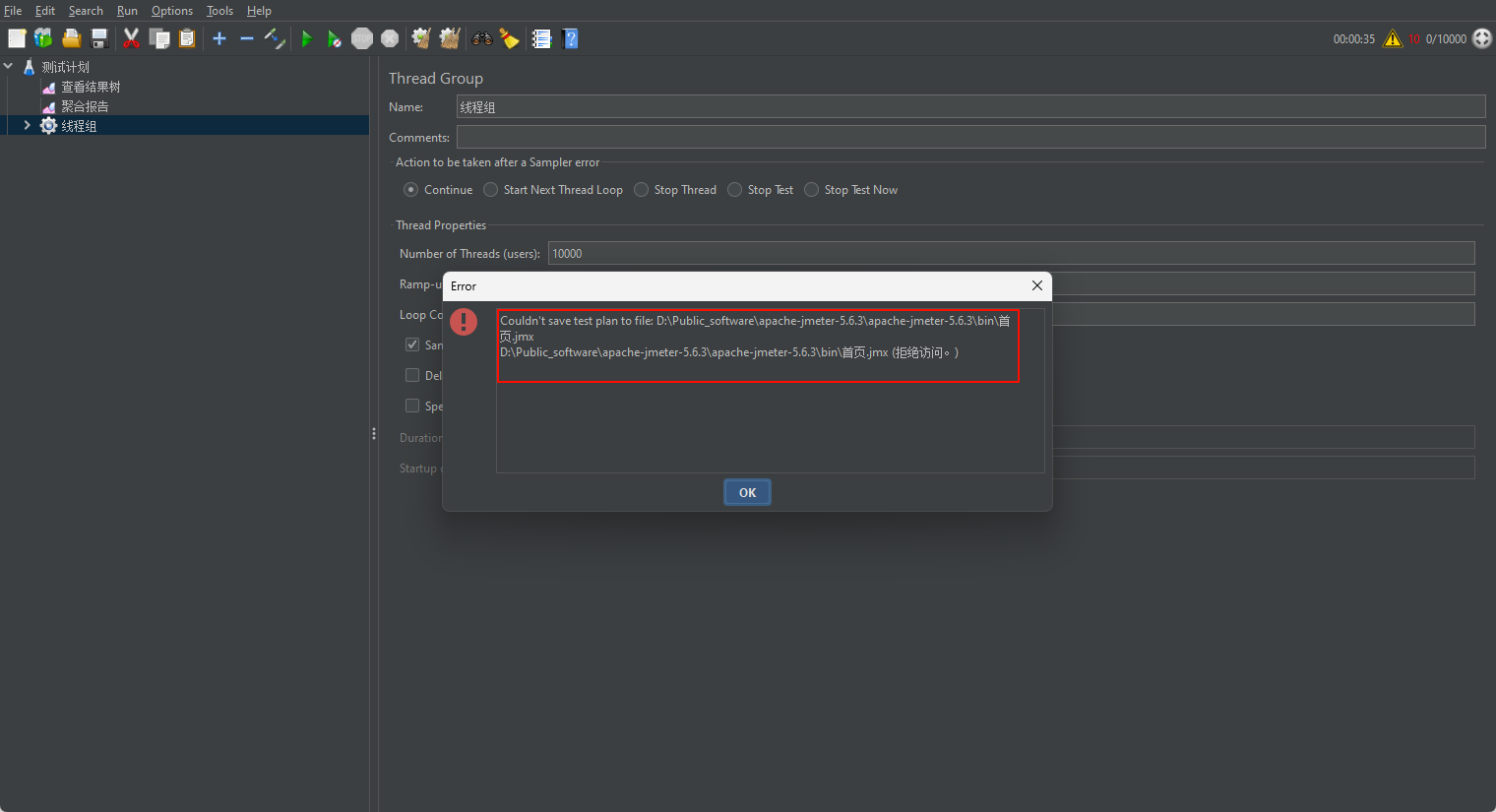
解决方式,选中Jmeter 文件夹,点击右键把只读置为空。
1.4 配置解析

上图是 JMeter 压测配置中非常简单的一个测试计划,测试计划下需要包括线程组 - 负责运行、取样器(压测的接口) - 负责调接口和至少一个监听器 - 负责看结果。这就形成了一个简单的测试计划。
1.4.1 线程组介绍
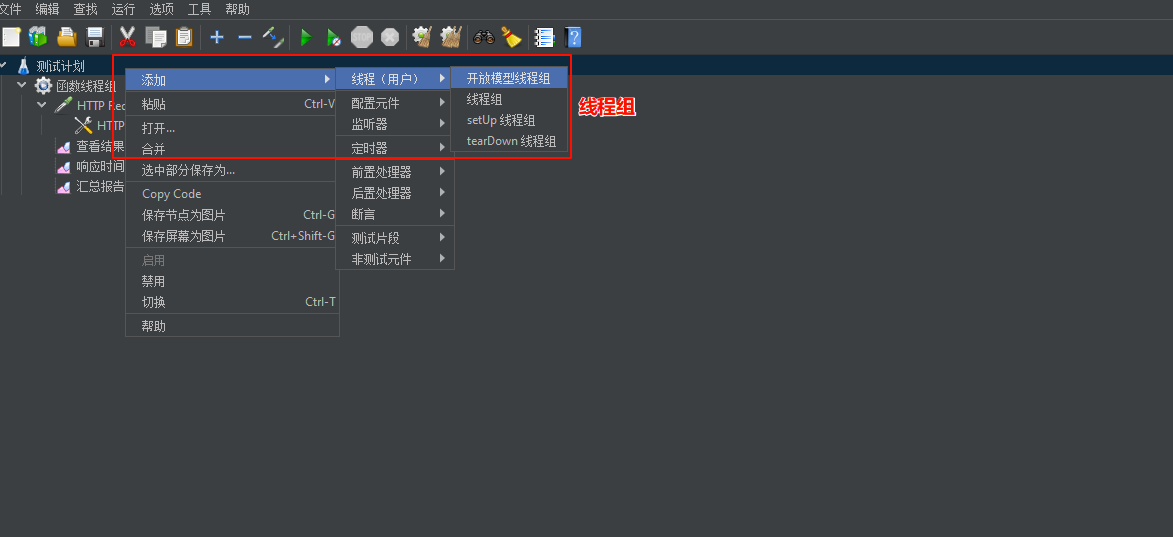
线程组是用于模拟用户行为的基本元素。每个线程代表一个虚拟用户,线程组通过控制线程数、每个线程的执行次数以及请求的时间间隔来模拟多用户访问的场景。线程组是测试计划中的基础组件之一,它决定了测试中虚拟用户的数量、执行频率和持续时间等参数。
1.4.1.1 函数线程组
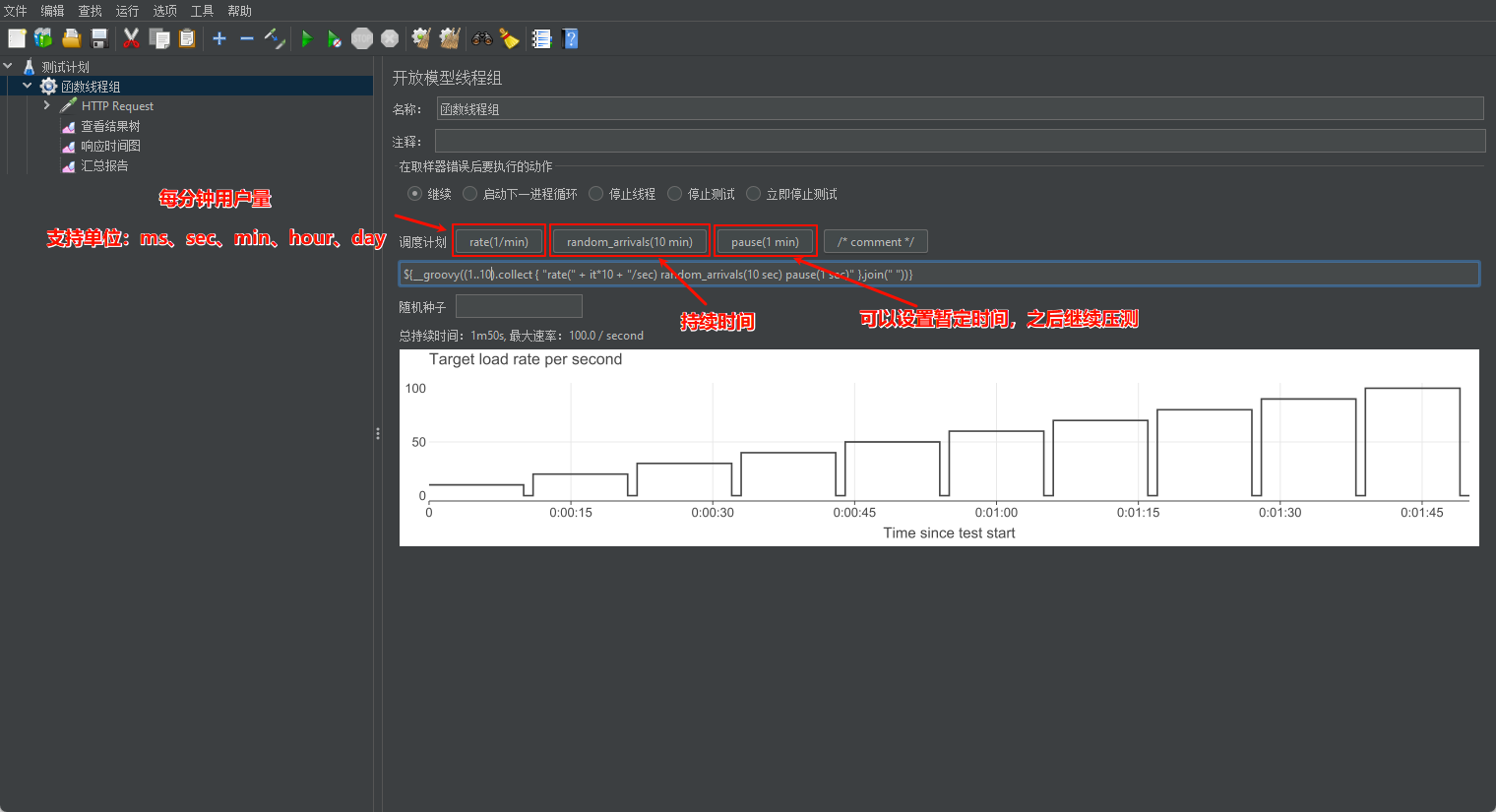
Open Mode Thread Group 支持配置简单的配置和 Groovy 脚本 如:
${__groovy((1..5).collect { "rate(" + it*10 + "/sec) random_arrivals(10 sec) pause(1 sec)" }.join(" "))} - 请求10次,每次都递进。还可以配置这些参数:
rate(0/min) random_arrivals(10 min) rate(100/min)
rate(0/min) random_arrivals(5 min) rate(100/min)
random_arrivals(100 min) rate(100/min)
random_arrivals(5 min) rate(0/min) - 通过这样的规律,就可以找到如何配置了。此外还支持 JMeter 函数:
pause(2 min) rate(${__Random(10,50,)}/min)random_arrivals(${__Random(10,100,)} min) rate(${__Random(10,1000,)}/min) - 也可以多行配置负载举例;总时长为1分10秒。前10秒内,速率达到10/s,然后,在1分钟内吞吐量将保持在10/s。最大吞吐量为600个/分钟。配置:
rate(600 / min) random_arrivals(10 s) rate(600 / min) random_arrivals(1 min)1.4.1.2 简单线程组
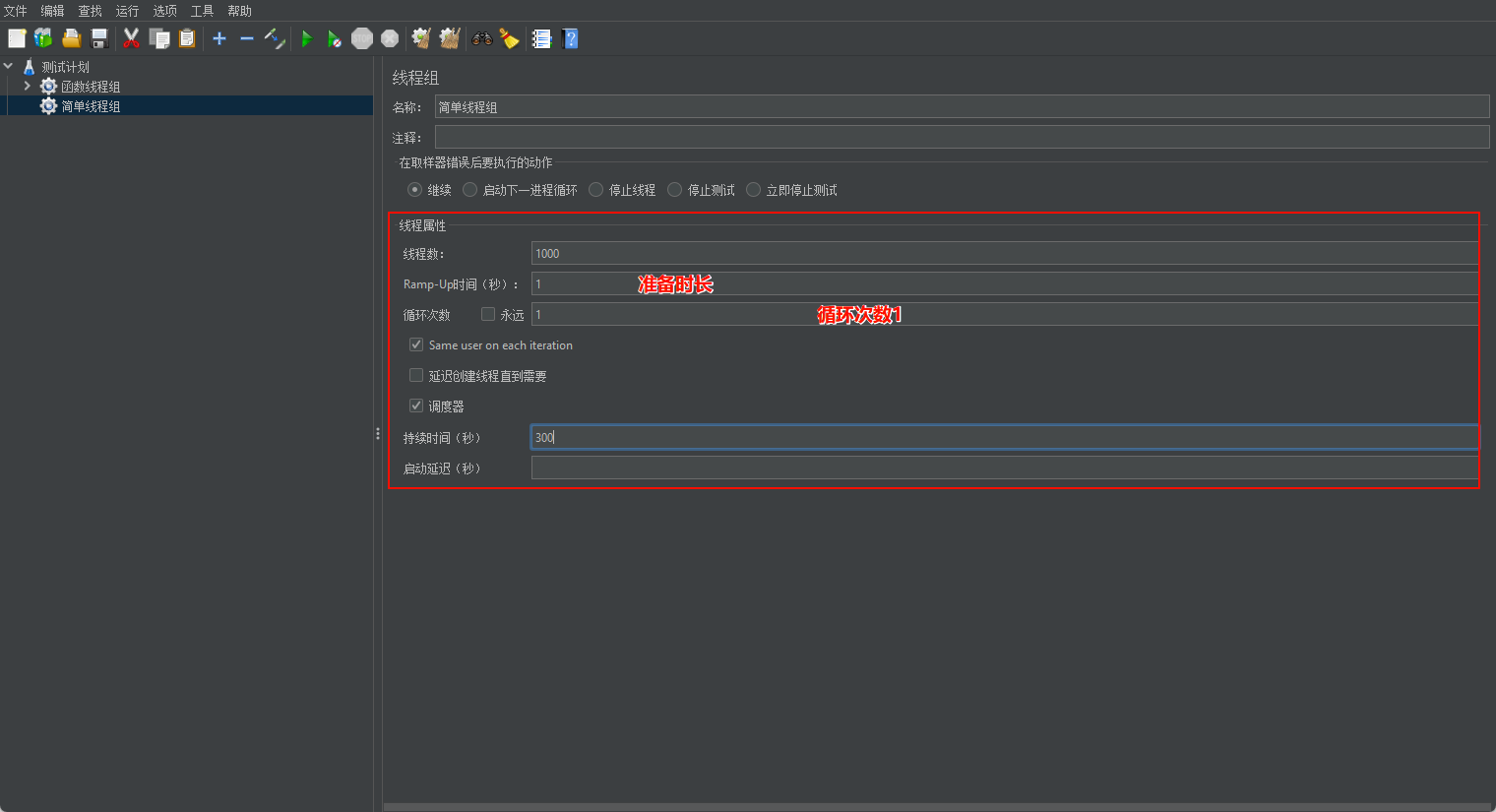
简单线程组配置起来比较简单,更适合一些循环压测的场景。
- 线程数:一个用户相当于一个线程。
- Ramp-Up:预期线程组的所有线程从启动-运行-释放的总时间。ramp up=0时,表示瞬时加压,启动线程的时间无限趋近于0。在负载测试的时候,尽量把ramp up设置大一些,让性能曲线平缓,容易找到瓶颈点。
- 循环次数:线程组的循环次数,如果不设置,则表示在调度时间范围内一直循环(jmeter不停的发请求)。
- 调度器:执行的时间设置。
- 此外,JMeter 还可以安装插件,设置更多的线程组模型来压测。
1.4.2 取样器
JMeter 取样器用于定义测试中请求的类型,比如HTTP请求、数据库查询、FTP请求等。每个取样器负责模拟特定的用户行为并收集响应数据。
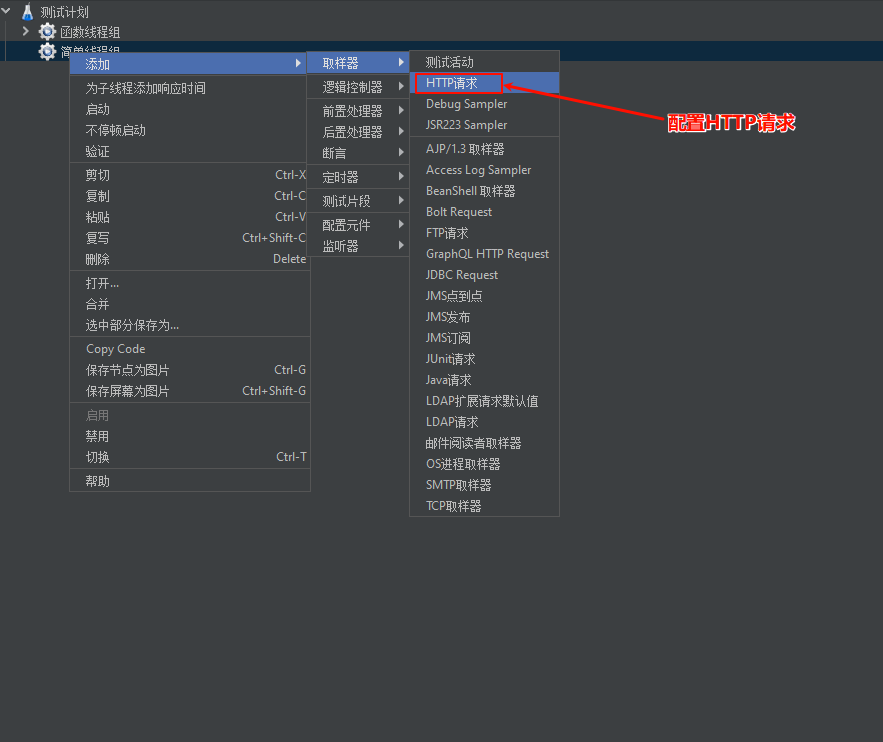
如上图所示,在线程组下创建一个取样器(HTTP压测接口)。还有一种更简单的方式创建HTTP请求cURL 方式导入(推荐)。
F12打开浏览器控制台,切换到 Network 窗口,找到需要压测的接口,右键选择以cURL格式复制,随后导入cURL 到 Jmeter.
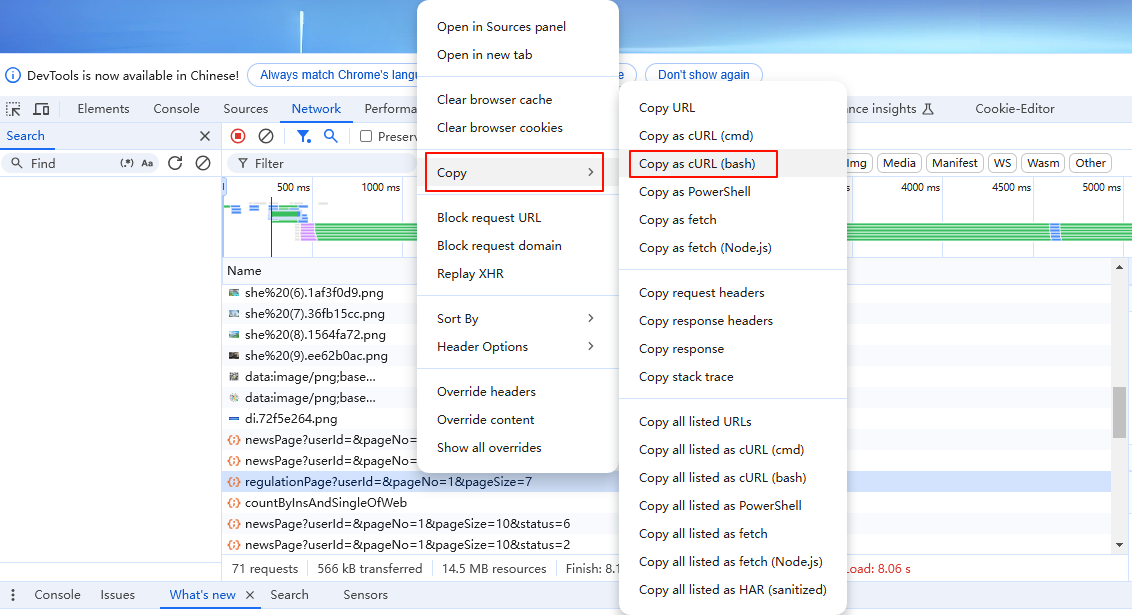
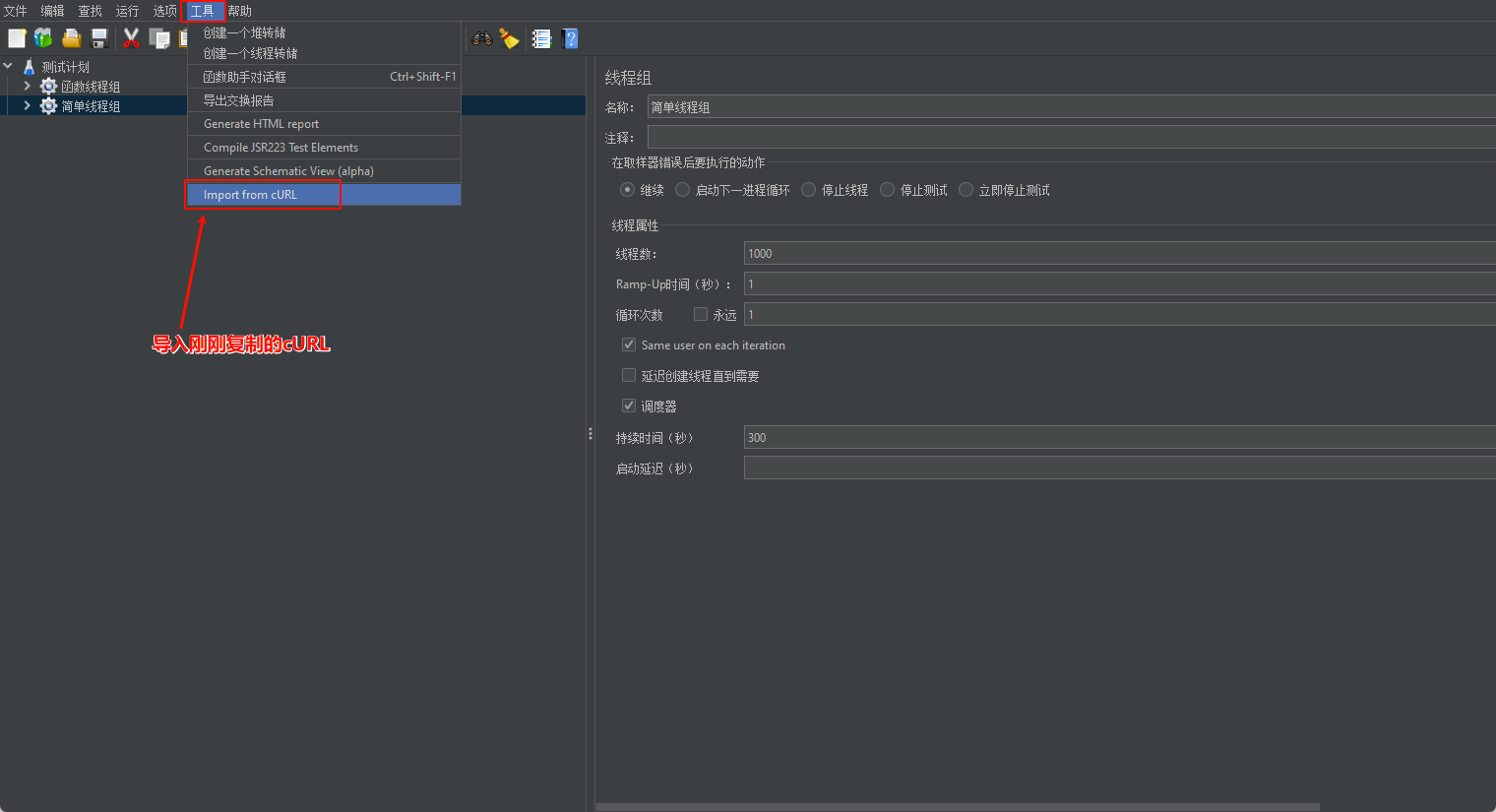
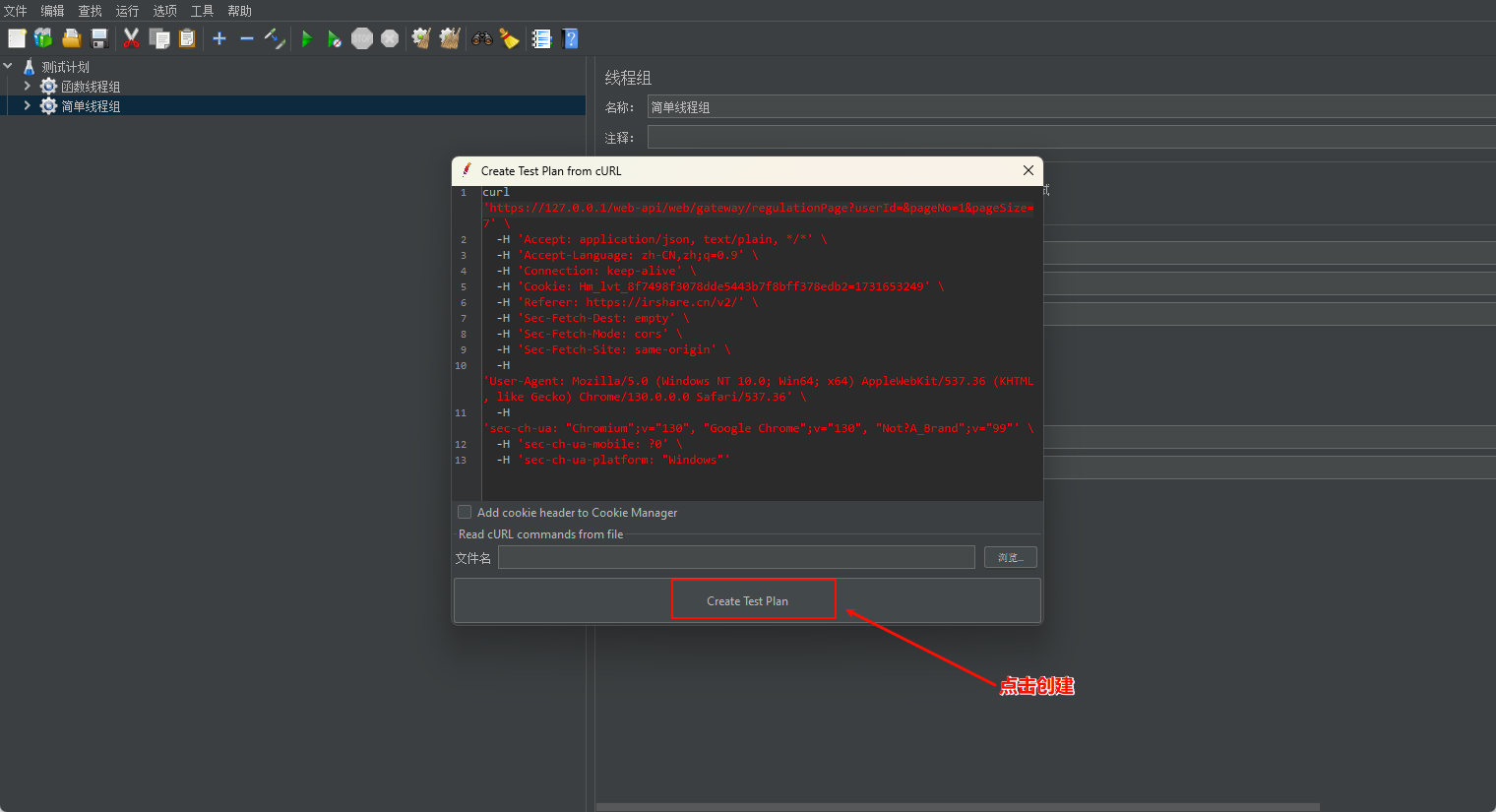
如上图操作完成后,打开线程组下面就有相应需要压测的HTTP请求了。
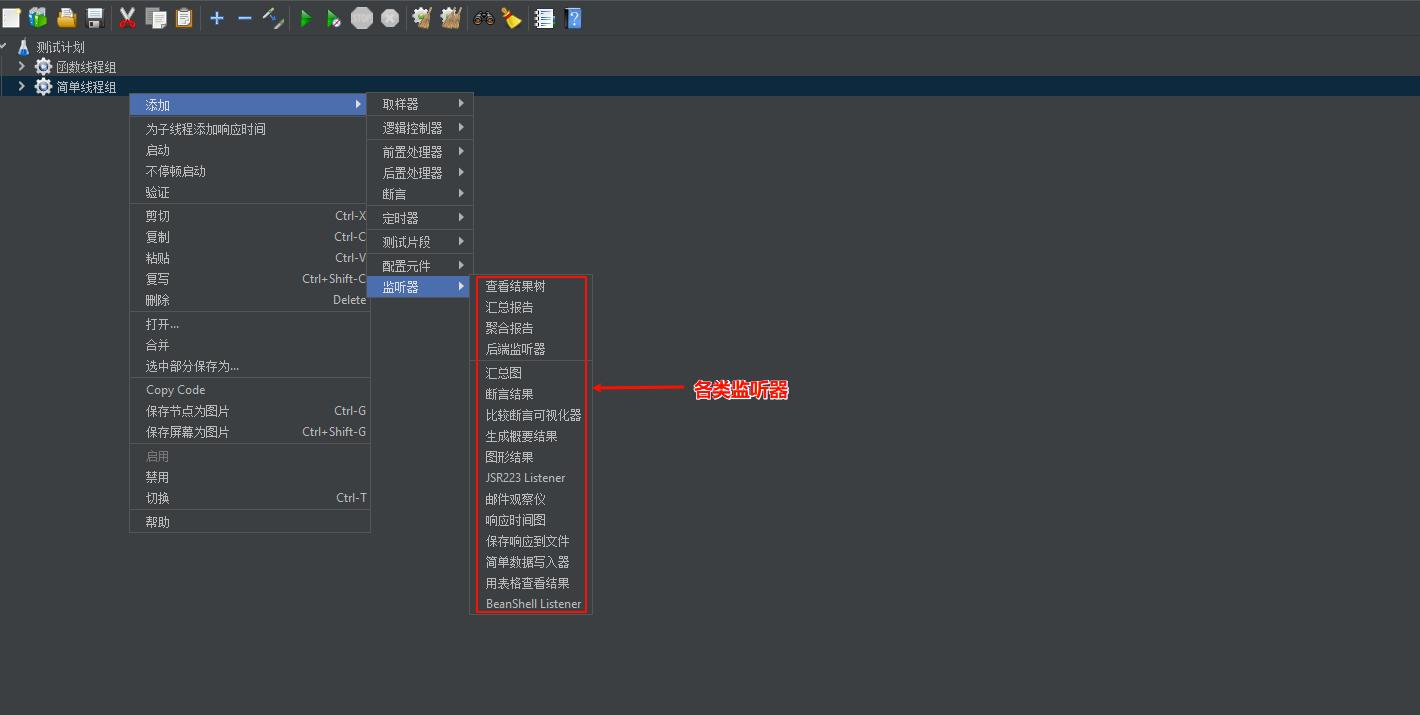
1.4.3 监听器
线程组是各类方式的模拟压测调用,取样器HTTP是压测的接口。那么监听器就是看线程组对取样器HTTP的压测结果。
2. 使用 Jmeter
2.1 压测前置需求
前置环境操作, 目前需求是把宽带流量限制到25M。后续可以根据实际情况进行调整。
| 常见宽带 | 理论最高速率(Mbps) | 理论最高速率(KB/S) | 常见下载速率(供参考) |
|---|---|---|---|
| 1M | 1 Mbps | 128 KB/S | 77~128 KB/S |
| 2M | 2 Mbps | 256 KB/S | 154~256 KB/S |
| 3M | 3 Mbps | 384 KB/S | 231~384 KB/S |
| 4M | 4 Mbps | 512 KB/S | 307~512 KB/S |
| 6M | 6 Mbps | 620 KB/S | 462~620 KB/S |
| 8M | 8 Mbps | 1024 KB/S | 614~1024 KB/S |
| 10M | 10 Mbps | 1280 KB/S | 768~1280 KB/S |
| 12M | 12 Mbps | 1536 KB/S | 922~1536 KB/S |
| 20M | 20 Mbps | 2560 KB/S | 1536~2560 KB/S |
| 30M | 30 Mbps | 3840 KB/S | 2560~3840 KB/S |
| 50M | 50 Mbps | 6400 KB/S | 3840~6400 KB/S |
| 100M | 100 Mbps | 12800 KB/S | 7680~12800 KB/S |
1Mbps 即 1Mbit/s (1 024 000 bit per second 1百万bit每秒)换算成Byte(字节)1024000 / 8 = 128000 Byte = 128KB
2.1.1 检查网络接口
首先,确认需要限速的网络接口名称。例如,通过 ip addr 查看网络接口名称:
ip addr假设接口名称是 docker0。
2.1.2 使用 tc 设置限速
以下命令可以将网络带宽限制为 25 Mbps:
sudo tc qdisc add dev docker0 root tbf rate 25mbit burst 32kbit latency 400ms参数解释:
dev eth0:指定限速的网络接口。rate 25mbit:设置带宽限制为 25 Mbps。burst 32kbit:允许的突发流量大小(可根据需要调整)。latency 400ms:最大延迟时间,用于缓冲。
2.1.3. 验证设置
可以通过以下命令验证限速是否生效:
sudo tc qdisc show dev docker02.1.4. 移除限速
如果需要删除限速规则,可以使用以下命令:
sudo tc qdisc del dev docker0 root使用 iftop 命令 是一个非常强大的网络流量监控工具,可以实时显示网卡的流量情况。我们可以用它来观察 8987 端口的流量:
sudo iftop -i docker0 -f 'port 8987's这个命令会显示 ens160 网卡上 8987 端口的实时流量情况,包括总流量、进出流量等。我们可以观察是否超过了 25M 的限制。
2.2 开始压测
真实测试案例;创建10000 用户,并设置1000并发用户同时访问压测接口。
在浏览器中 F12 打开控制台,找到 Network 复制想要压测的 cURL,最后导入到 Jmeter。(在取样器里有图文价绍)
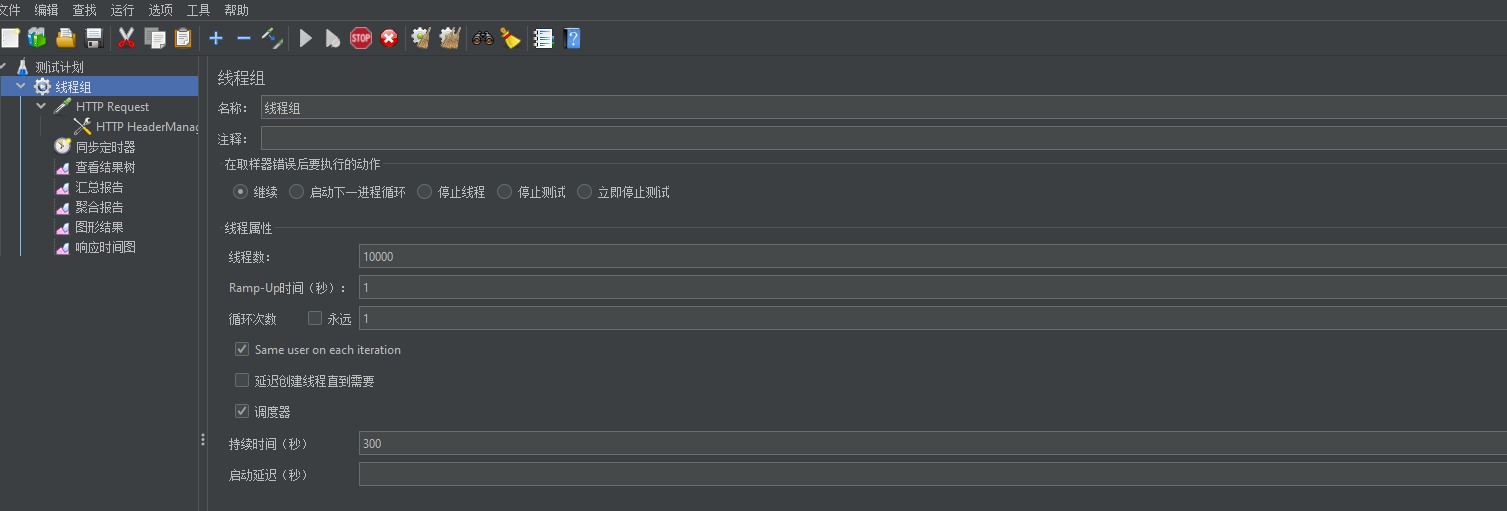

2.3 压测结果
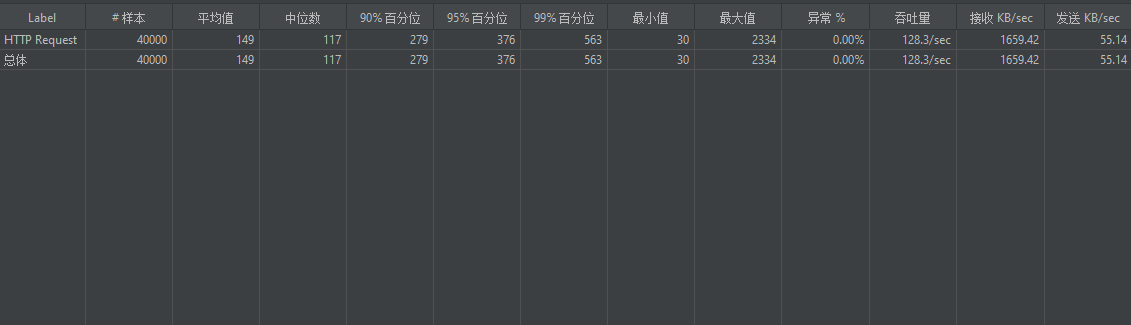
2.3.1 汇总报告

样本(Samples):发送的请求数量。在图中,HTTP 请求和总计的样本数都是 10,000,表示总共进行了 10,000 次请求。
响应时间【单位ms】:
- 平均值(Average):平均的响应时间
- 最小值(Min):请求返回的最小时间,其中一个用时最少的请求
- 最大值(Max):请求返回的最大时间,其中一个用时最大的请求
- 标准偏差(Standard Deviation):度量响应时间分布的分散程度的标准,衡量响应时间值偏离平均响应时间的程度
异常 %(Error % 或 异常率): 出现错误的百分比,错误率=错误的请求的数量/请求的总数
吞吐量TPS(Throughput): 吞吐能力,这个才是我们需要的并发数
平均字节数(Average Bytes):每个请求的平均数据大小(以字节为单位)。
2.3.2 聚合报告

样本(sample): 发送请求的总样本数量
响应时间【单位ms】:
- 平均值(average):平均的响应时间
- 中位数(median): 中位数的响应时间,50%请求的响应时间
- 90%百分位(90% Line): 90%的请求的响应时间,意思就是说90%的请求是<=1765ms返 回,另外10%的请求是大于等于1765ms返回的
- 95%百分位(95% Line): 95%的请求的响应时间,95%的请求都落在1920ms之内返回的
- 99%百分位(99% Line): 99%的请求的响应时间
- 最小值(min):请求返回的最小时间,其中一个用时最少的请求
- 最大值(max):请求返回的最大时间,其中一个用时最大的请求
异常(error): 出现错误的百分比,错误率=错误的请求的数量/请求的总数
吞吐量TPS(throughout): 吞吐能力
接收 KB/sec(Received KB/sec):每秒从服务器接收的数据量(以 KB 为单位)
发送 KB/sec(Sent KB/sec):每秒发送到服务器的数据量(以 KB 为单位)。
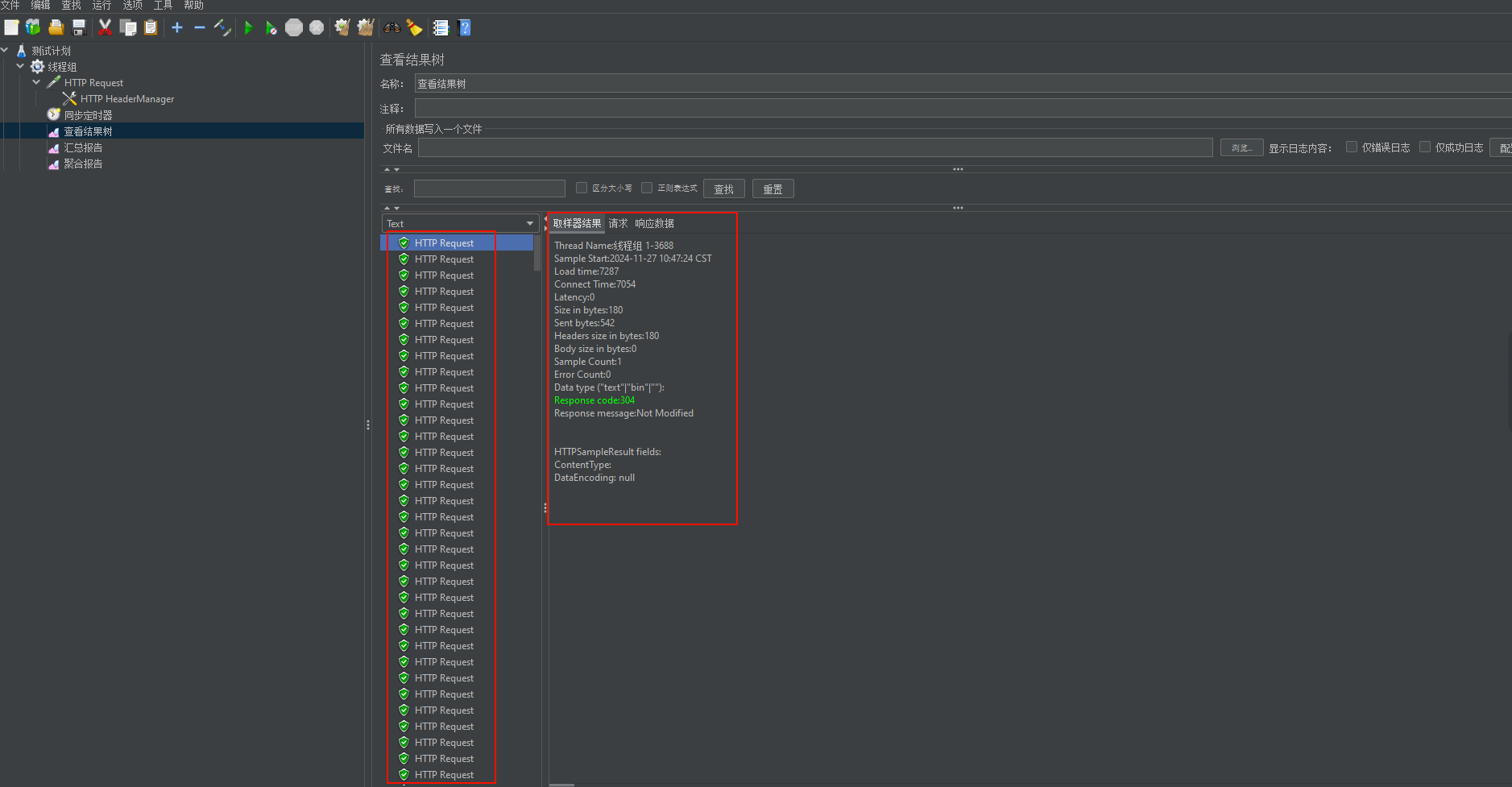
2.3.3 察看结果树
在这里记录了样本中的每一次请求
2.4 Jmeter常用插件
Jmeter自带的内容分析维度不够实际用的,这里需要加入新的插件来增强分析。
如:TPS、QPS、RT【平均响应时间】、压力机活动线程数 服务器资源信息的分析。
2.4.1 开启插件功能
访问官网地址 Jmeter,下载plugins-manager.jar并将其放入lib/ext目录,然后重新启动JMeter。
重启成功后开始安装所需插件:
- PerfMon:监控服务器硬件,如CPU,内存,硬盘读写速度等
- Basic Graphs:主要显示平均响应时间,活动线程数,成功/失败交易数等
- Average Response Time 平均响应时间
- Active Threads 活动线程数
- Successful/Failed Transactions 成功/失败 事务数
- Additional Graphs:主要显示吞吐量,连接时间,每秒的点击数等
- Response Codes 响应代码
- Bytes Throughput 字节吞吐量
- Connect Times 连接时间
- Latenc 延迟
- Hits/s 点击数/秒
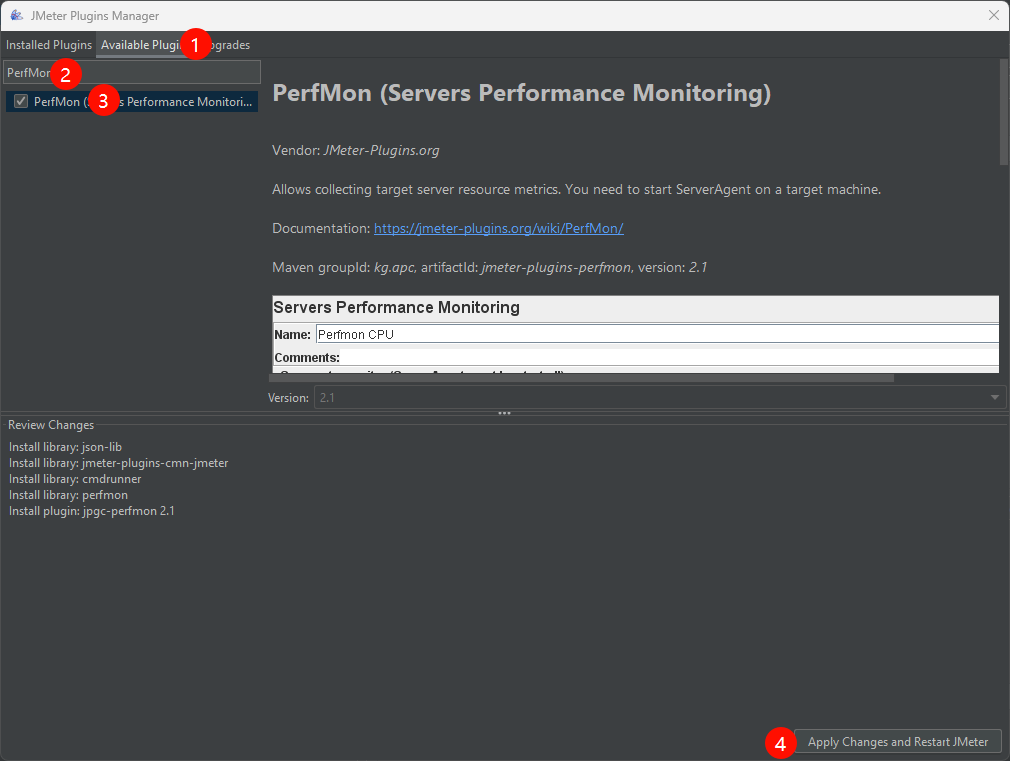
安装完成后就可以使用插件了。
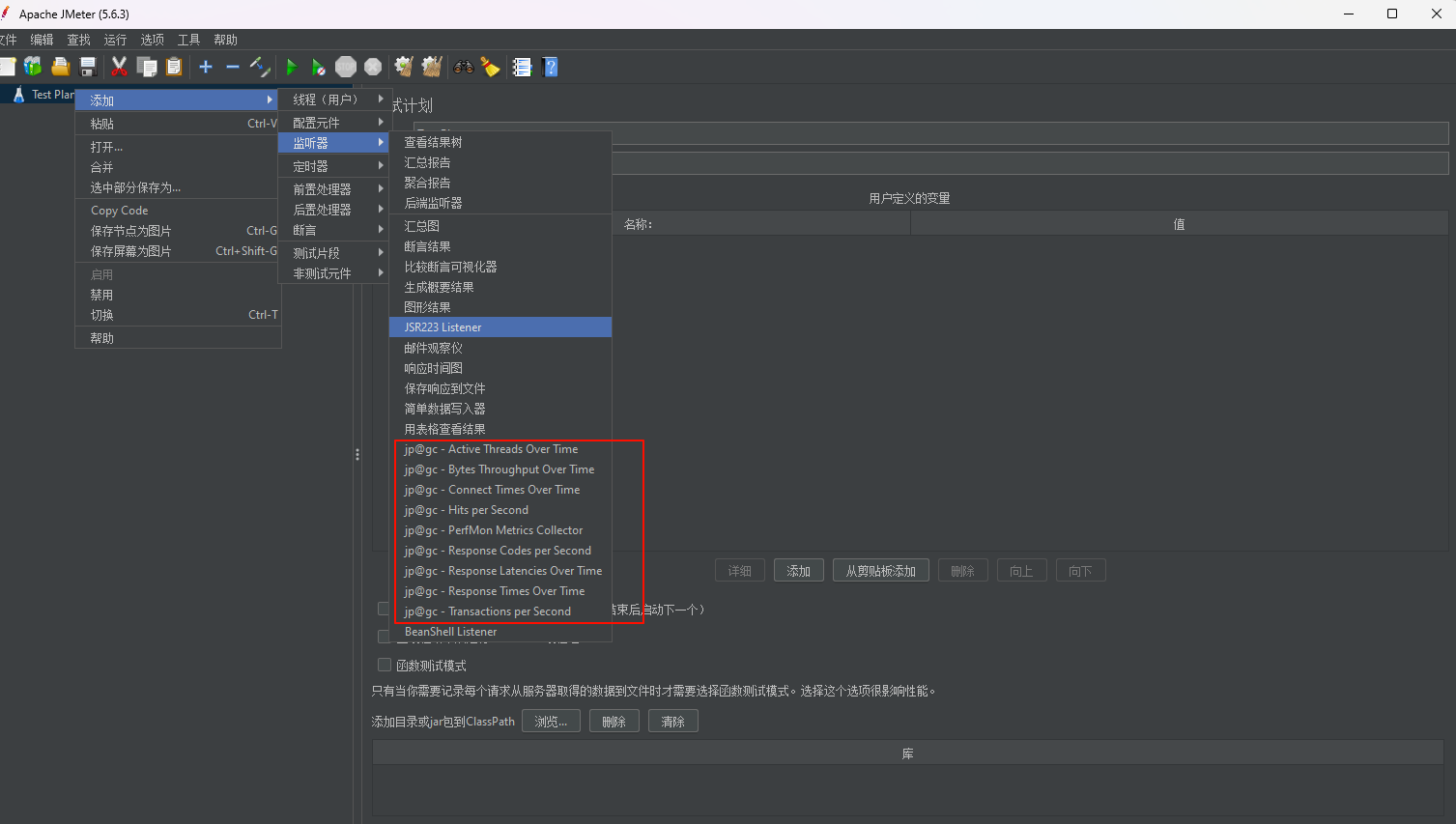
2.4.2 配置使用插件
添加需要执行压力测试的接口,并配置线程组信息。
响应时间:jp@gc - Response Times Over Time
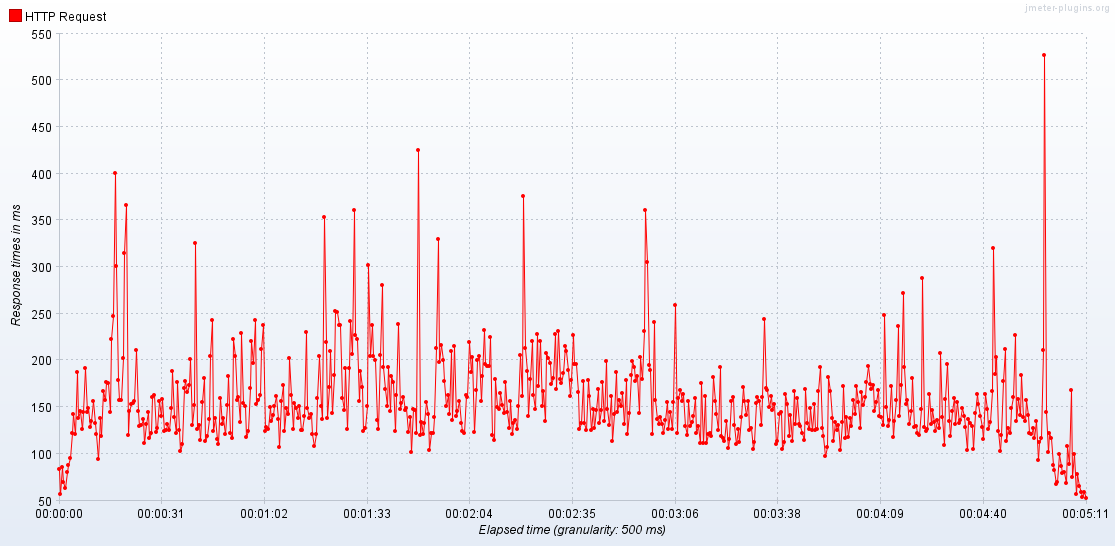
活动线程数:jp@gc - Active Threads Over Time
每秒事务数:jp@gc - Transactions per Second
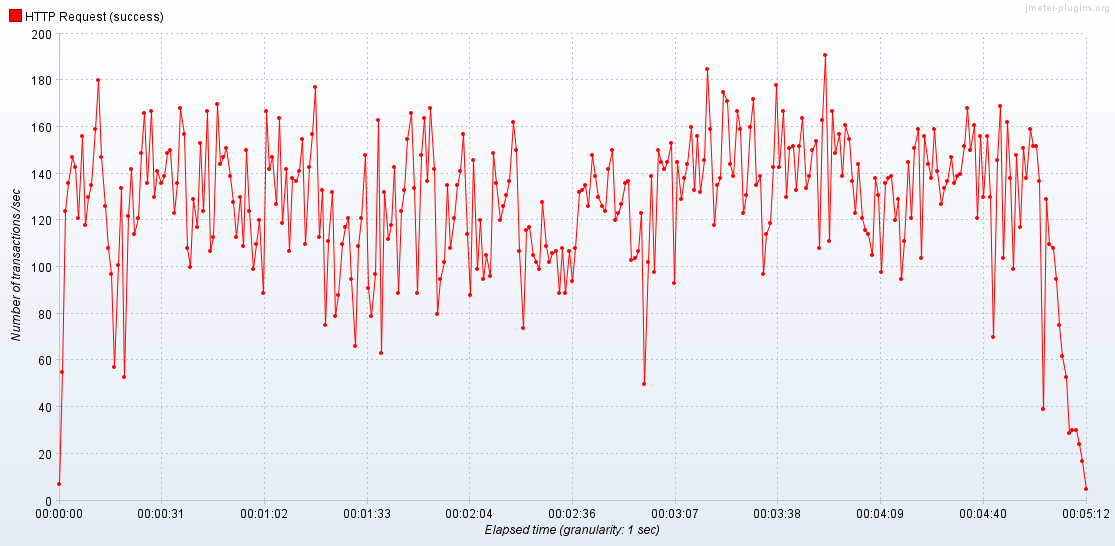
2.4.3 性能关键指标分析
响应时间(RT)
- 平均值: 请求响应的平均时间是149ms
- 中位数: 50%请求响应时间都在117ms之内
- P90: 90%的请求都在279ms之内响应结束
- P95: 95%的请求都在376ms之内响应结束
- P99:99%的请求都在563ms之内响应结束
- 最小值: 请求响应最小时间30ms
- 最大值: 请求响应的最大时间是2334ms
活动线程数
- 压力机中活动的线程数
TPS: 每秒的事务数
- 数字愈大,代表性能越好;
QPS: 每秒的查询数量
- 数字愈大,代表性能越好;(1tps >= QPS)
吞吐量: 每秒的请求数量
- 数字愈大,代表性能越好;
2.5 Jmeter 服务器性能监控
在进行压力测试时,我们需要了解服务器的 CPU、内存、网络等运行状态、系统整体负载情况等。这时,需要使用 top、iftop、vmstat 等 Linux 命令来查看服务器的资源占用情况。
2.5.1 配置服务器代理
要监控服务器的硬件资源,必须在服务器端安装 ServerAgent 代理服务,以便 JMeter 可以监控服务器的 CPU、内存和 IO 的使用情况。
下载地址:ServerAgent-2.2.3
默认启动运行 startAgent.sh 脚本即可:
#进入到ServerAgent-2.2.3目录下0
./startAgent.sh更改服务默认启动端口:
# 编辑启动文件
vim startAgent.sh
# 替换内容
nohup java -jar ./CMDRunner.jar --tool PerfMonAgent --udp-port 8784 --tcp-port 8784 > log.log 2>&1 &
# 赋予可执行权限
chmod +x startAgent.sh看到如下日志代表启动成功:
root@ss:ServerAgent-2.2.3# tail -f log.log
INFO 2024-11-27 16:48:40.243 [kg.apc.p] (): Binding UDP to 8784
INFO 2024-11-27 16:48:41.243 [kg.apc.p] (): Binding TCP to 8784
INFO 2024-11-27 16:48:41.248 [kg.apc.p] (): JP@GC Agent v2.2.3 started2.5.2 配置监控服务器CPU
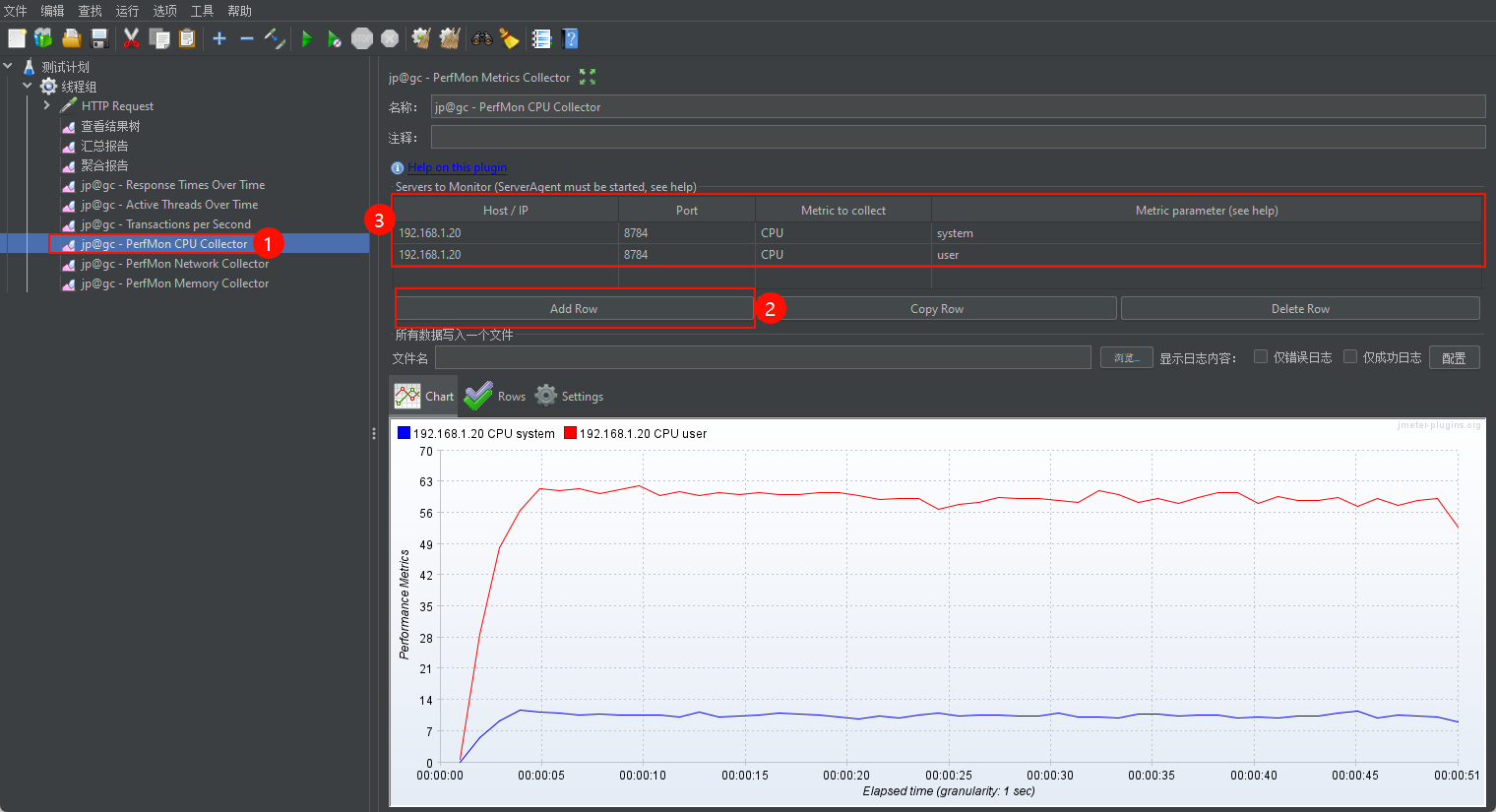
- idle:CPU空闲
- iowait:IO等待
- system:系统占用 CPU
- user:CPU用户占用
红色线条代表用户态 CPU 使用率(CPU user),开始时迅速上升并保持在大约 60% 左右。这表明服务器在处理用户级别的任务时占用了较高的 CPU 资源。
蓝色线条代表系统态 CPU 使用率(CPU system),在图中保持在较低的水平,大约 5% 左右。这表示用于系统级别任务的 CPU 资源占用较少。
2.5.3 配置监控服务器网络
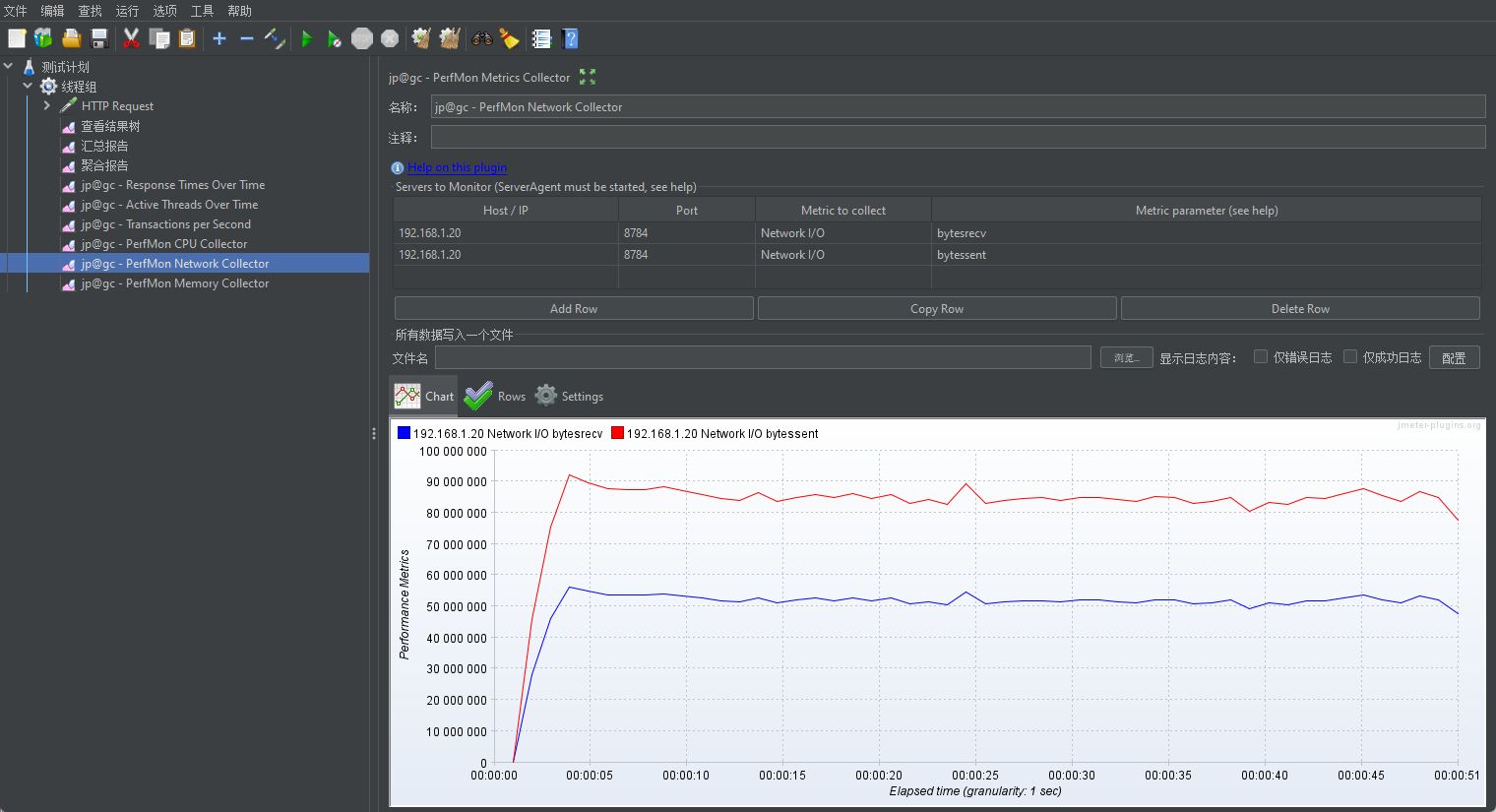
- 接收字节:byteSrecv【单位:比特、KB、MB】
- 发送字节:byteSent【单位:比特、KB、MB】
- 发送(transport):tx
- 接收(receive):rx
红色线条代表发送的数据量(Network I/O bytes sent),在图的开头迅速上升并稳定在一个高水平,大约 90,000,000 字节(8)。这表明服务器在发送大量数据。
蓝色线条代表接收的数据量(Network I/O bytes received),同样在开头迅速上升并稳定在一个较低水平,大约 60,000,000 字节,显示服务器接收的数据量较发送的数据量少。
换算字节到兆字节(MB)的方法如下:
- 1 MB = 1,024 KB
- 1 KB = 1,024 字节
因此,1 MB = 1,024 × 1,024 = 1,048,576 字节。
所以,90,000,000 字节 ÷ 1,048,576 字节/MB ≈ 85.83 MB
2.5.4 配置监控服务器内存
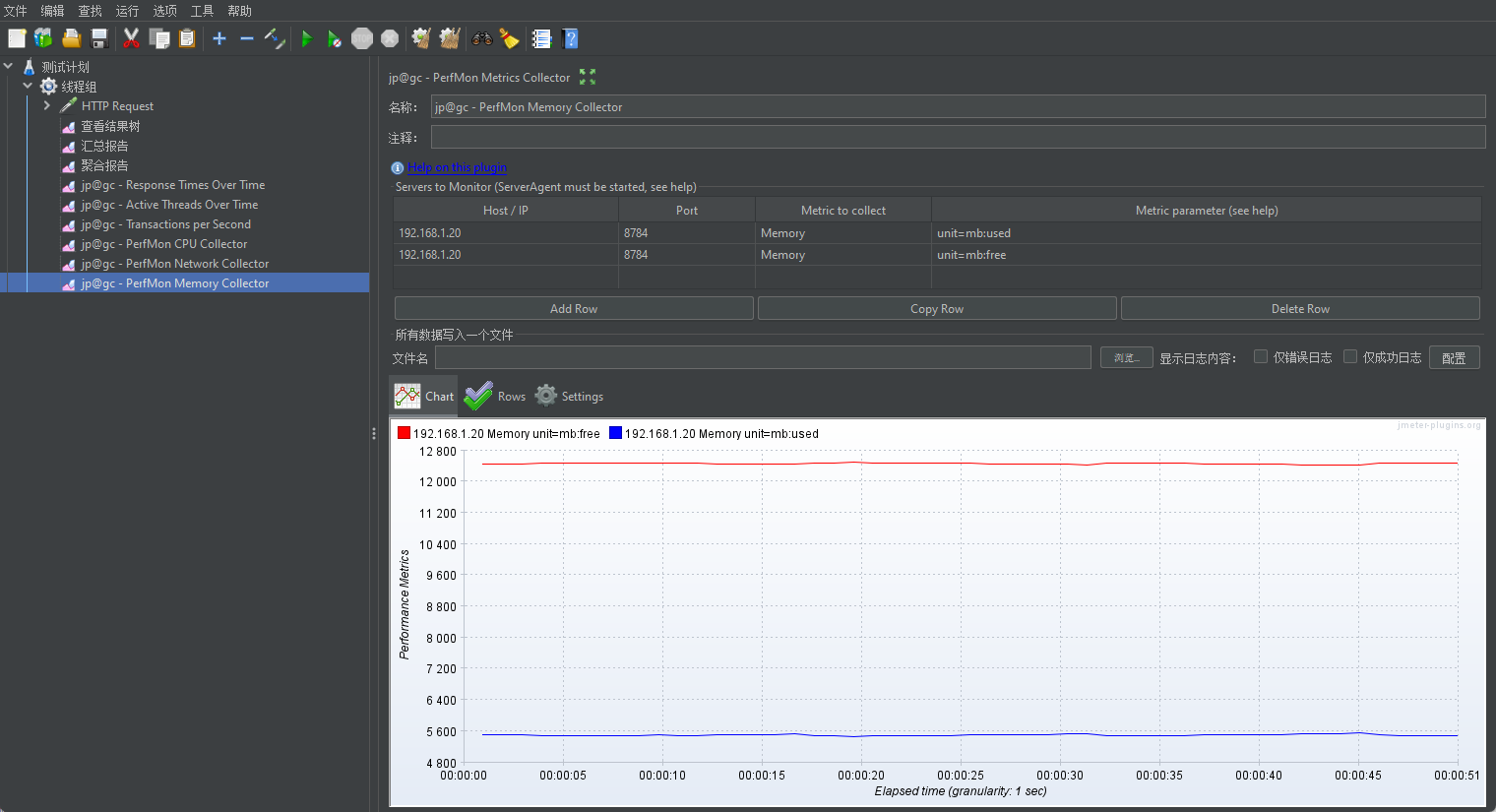
- usedPerc:每分钟使用内存【单位:字节、KB、MB】
- freePerc:每分钟未使用内存【单位:字节、KB、MB】
红色线条代表可用内存(Memory free),显示在大约 12,800 MB 的水平线附近,表示服务器有大量可用内存。
蓝色线条代表已用内存(Memory used),显示在大约 5,600 MB 的水平线附近,表明内存使用较为稳定,没有显著变化。
2.5.5 监控系统整体负载情况
使用 top 或 top -H 来查询服务器资源使用情况,也可以使用 uptime 命令查看精简信息。
top 和 top -H 的区别在于它们显示的信息范围:
top:显示系统中每个进程的资源使用情况,包括 CPU、内存等。默认情况下,它显示的是进程级别的信息。top -H:以线程为单位显示资源使用情况。这意味着它会显示每个进程的各个线程的资源使用情况。这在分析多线程应用程序的性能问题时非常有用。
如下图所示,可以看到系统负载 load average 情况,1分钟、5分钟和15分钟的负载平均值分别为:0.10、0.22、0.11。这些值表示系统在这些时间段内的平均进程数量。接近0的值表示系统负载较低。
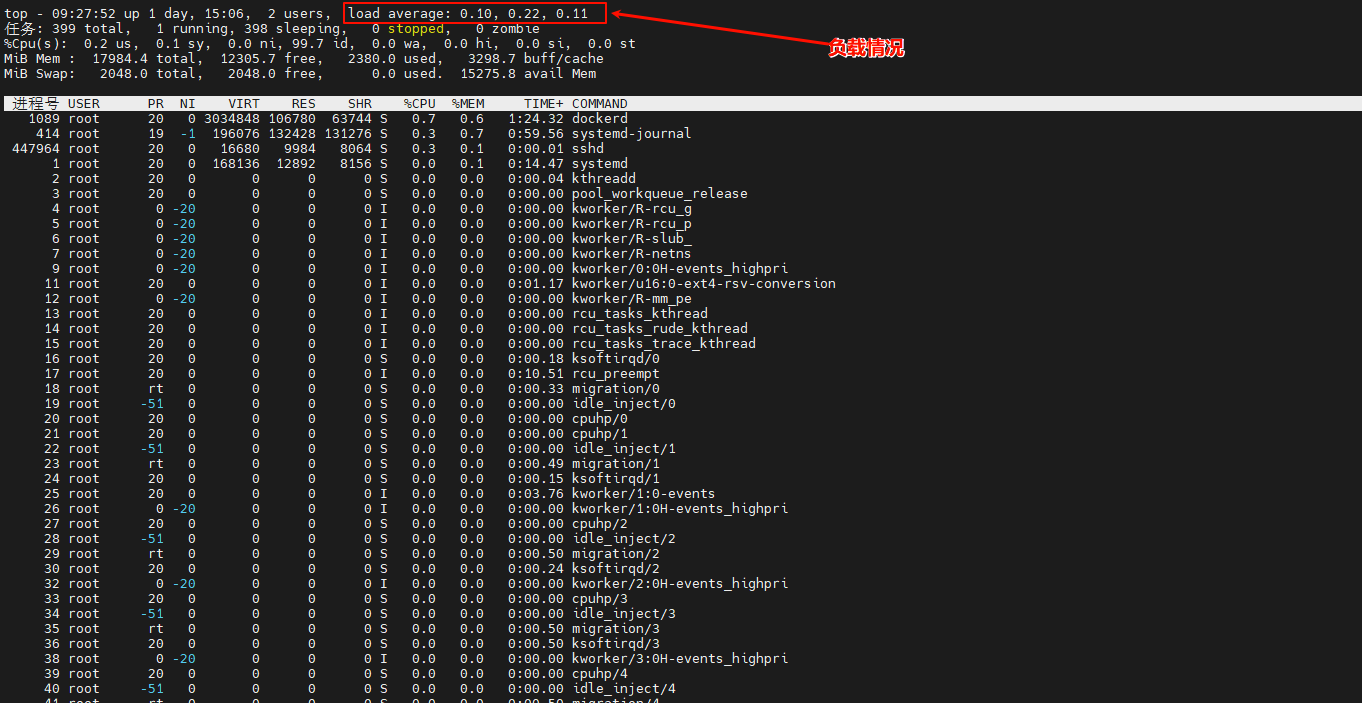
2.5.6 性能关键指标分析Load Average
影响Load Average 指标有:CPU、内存、网络IO等。
什么是Load Average?
Load Average(负载平均值)是一个表示系统负载的指标,通常用于衡量操作系统的运行状态和繁忙程度。它是操作系统中平均任务队列长度(正在等待 CPU 执行或等待 I/O)的时间平均值,通常以三个时间段表示:1 分钟、5 分钟和 15 分钟的平均值。
Load Average 的数值是什么含义?
不同的CPU性质不同,如单核,双核,四核,八核。
单核CPU三种Load Average情况:
举例说明:把CPU比喻成一条(单核)马路,进程任务比喻成马路上跑着的汽车,Load则表示马 路的繁忙程度。
情况1-Load小于1:不堵车,汽车在马路上跑得游刃有余:

image-20241128105409934 情况2-Load等于1:马路已无额外的资源跑更多的汽车了:

image-20241128105957426 情况3-Load大于1:汽车都堵着等待进入马路:

image-20241128110214345
双核CPU
如果有两个CPU,则表示有两条马路,此时即使Load大于1也不代表有汽车在等待:
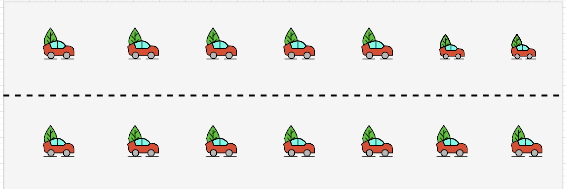
image-20241128110523856 Load==2,也是没有等待的
什么样的Load值得警惕?
如下分析针对单核CPU
- 【0.0 - 0.7]】 :系统很闲,马路上没什么车,要考虑多部署一些服务
- 【0.7 - 1.0 】:系统状态不错,马路可以轻松应对
- 【等于1.0】 :系统马上要处理不多来了,赶紧找一下原因
- 【大于5.0】 :马路已经非常繁忙了,进入马路的每辆汽车都要无法很快的运行
如下分析针对单核CPU的四种情况:
情况1:1分钟负载 > 5,5分钟负载 < 1,15分钟负载 < 1
举例: 5.18 , 0.05 , 0.03
短期内繁忙,中长期空闲,初步判断是一个“抖动”或者是“拥塞前兆”
情况2:1分钟负载 > 5,5分钟负载 > 1,15分钟负载 < 1
举例: 5.18 , 1.05 , 0.03
短期内繁忙,中期内紧张,很可能是一个“拥塞的开始”
情况3:1分钟负载 > 5,5分钟负载 > 5,15分钟负载 > 5
举例: 5.18 , 5.05 , 5.03
短中长期都繁忙,系统“正在拥塞”
情况4:1分钟负载 < 1,5分钟负载 > 1,15分钟负载 > 5
举例: 0.18 , 1.05 , 5.03
短期内空闲,中长期繁忙,不用紧张,系统“拥塞正在好转”